















































Os unit 3 , process management
- 1. PROCESS MANAGEMENT UNIT III Processes: Process Concept, Process Scheduling, Operation on Processes. CPU Scheduling: Basic Concepts, Scheduling Criteria, Scheduling Algorithms, Multiple- Processor Scheduling, Process Synchronization: Background, The Critical-Section Problem, Synchronization, Hardware, Semaphores.
- 2. Process • A process is basically a program in execution. • The execution of a process must progress in a sequential fashion. • A process is defined as an entity which represents the basic unit of work to be implemented in the system. • we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program. • When a program is loaded into the memory and it becomes a process, it can be divided into four sections ─ stack, heap, text and data. The following image shows a simplified layout of a process inside main memory −
- 3. Process S.N. Component & Description 1 Stack The process Stack contains the temporary data such as method/function parameters, return address and local variables. 2 Heap This is dynamically allocated memory to a process during its run time. 3 Text This includes the current activity represented by the value of Program Counter and the contents of the processor's registers. 4 Data This section contains the global and static variables.
- 4. PROCESS LIFE CYCLE • When a process executes, it passes through different states. These stages may differ in different operating systems, and the names of these states are also not standardized. • In general, a process can have one of the following five states at a time.
- 5. PROCESS LIFE CYCLE S.N. State & Description 1 Start This is the initial state when a process is first started/created. 2 Ready The process is waiting to be assigned to a processor. Ready processes are waiting to have the processor allocated to them by the operating system so that they can run. Process may come into this state after Start state or while running it by but interrupted by the scheduler to assign CPU to some other process. 3 Running Once the process has been assigned to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions. 4 Waiting Process moves into the waiting state if it needs to wait for a resource, such as waiting for user input, or waiting for a file to become available. 5 Terminated or Exit Once the process finishes its execution, or it is terminated by the operating system, it is moved to the terminated state where it waits to be removed from main memory.
- 6. PROCESS CONTROL BLOCK (PCB) • A Process Control Block is a data structure maintained by the Operating System for every process. The PCB is identified by an integer process ID (PID). A PCB keeps all the information needed to keep track of a process as listed below in the table −
- 7. PROCESS CONTROL BLOCK (PCB) S.N. Information & Description 1 Process State The current state of the process i.e., whether it is ready, running, waiting, or whatever. 2 Process privileges This is required to allow/disallow access to system resources. 3 Process ID Unique identification for each of the process in the operating system. 4 Pointer A pointer to parent process. 5 Program Counter Program Counter is a pointer to the address of the next instruction to be executed for this process. 6 CPU registers Various CPU registers where process need to be stored for execution for running state. 7 CPU Scheduling Information Process priority and other scheduling information which is required to schedule the process. 8 Memory management information This includes the information of page table, memory limits, Segment table depending on memory used by the operating system. 9 Accounting information This includes the amount of CPU used for process execution, time limits, execution ID etc. 10 IO status information This includes a list of I/O devices allocated to the process.
- 8. PROCESS SCHEDULING • The process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process on the basis of a particular strategy. • Process scheduling is an essential part of a Multiprogramming operating systems. Such operating systems allow more than one process to be loaded into the executable memory at a time and the loaded process shares the CPU using time multiplexing.
- 9. PROCESS SCHEDULING • Process Scheduling Queues: The Operating System maintains the following important process scheduling queues − • Job queue − This queue keeps all the processes in the system. • Ready queue − This queue keeps a set of all processes residing in main memory, ready and waiting to execute. A new process is always put in this queue. • Device queues − The processes which are blocked due to unavailability of an I/O device constitute this queue
- 10. PROCESS OPERATIONS • There are many operations that can be performed on processes. Some of these are process creation, process preemption, process blocking, and process termination. These are given in detail as follows − Process Creation Processes need to be created in the system for different operations. This can be done by the following events − • User request for process creation • System initialization • Execution of a process creation system call by a running process • Batch job initialization
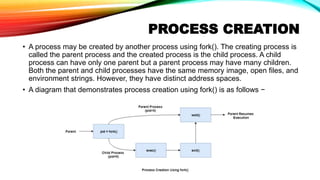
- 11. PROCESS CREATION • A process may be created by another process using fork(). The creating process is called the parent process and the created process is the child process. A child process can have only one parent but a parent process may have many children. Both the parent and child processes have the same memory image, open files, and environment strings. However, they have distinct address spaces. • A diagram that demonstrates process creation using fork() is as follows −
- 12. PROCESS PREEMPTION • An interrupt mechanism is used in preemption that suspends the process executing currently and the next process to execute is determined by the short-term scheduler. Preemption makes sure that all processes get some CPU time for execution. • A diagram that demonstrates process preemption is as follows −
- 13. PROCESS BLOCKING • The process is blocked if it is waiting for some event to occur. This event may be I/O as the I/O events are executed in the main memory and don't require the processor. After the event is complete, the process again goes to the ready state. • A diagram that demonstrates process blocking is as follows − •
- 14. PROCESS TERMINATION • After the process has completed the execution of its last instruction, it is terminated. The resources held by a process are released after it is terminated. • A child process can be terminated by its parent process if its task is no longer relevant. The child process sends its status information to the parent process before it terminates. Also, when a parent process is terminated, its child processes are terminated as well as the child processes cannot run if the parent processes are terminated.
- 15. CPU SCHEDULING • CPU scheduling is a process which allows one process to use the CPU while the execution of another process is on hold(in waiting state) due to unavailability of any resource like I/O etc, thereby making full use of CPU. The aim of CPU scheduling is to make the system efficient, fast and fair. • Whenever the CPU becomes idle, the operating system must select one of the processes in the ready queue to be executed. The selection process is carried out by the short-term scheduler (or CPU scheduler). The scheduler selects from among the processes in memory that are ready to execute, and allocates the CPU to one of them.
- 16. TYPES OF CPU SCHEDULING • CPU scheduling decisions may take place under the following four circumstances: • When a process switches from the running state to the waiting state(for I/O request or invocation of wait for the termination of one of the child processes). • When a process switches from the running state to the ready state (for example, when an interrupt occurs). • When a process switches from the waiting state to the ready state(for example, completion of I/O). • When a process terminates.
- 17. CPU SCHEDULING: SCHEDULING CRITERIA There are many different criterias to check when considering the "best" scheduling algorithm, they are: • CPU Utilization • To make out the best use of CPU and not to waste any CPU cycle, CPU would be working most of the time(Ideally 100% of the time). Considering a real system, CPU usage should range from 40% (lightly loaded) to 90% (heavily loaded.) • Throughput • It is the total number of processes completed per unit time or rather say total amount of work done in a unit of time. This may range from 10/second to 1/hour depending on the specific processes. • Turnaround Time • It is the amount of time taken to execute a particular process, i.e. The interval from time of submission of the process to the time of completion of the process(Wall clock time).
- 18. CPU SCHEDULING: SCHEDULING CRITERIA • Waiting Time • The sum of the periods spent waiting in the ready queue amount of time a process has been waiting in the ready queue to acquire get control on the CPU. • Load Average • It is the average number of processes residing in the ready queue waiting for their turn to get into the CPU. • Response Time • Amount of time it takes from when a request was submitted until the first response is produced. Remember, it is the time till the first response and not the completion of process execution(final response).
- 19. SCHEDULING ALGORITHMS • First Come First Serve(FCFS) Scheduling • Shortest-Job-First(SJF) Scheduling • Priority Scheduling • Round Robin(RR) Scheduling • Multilevel Queue Scheduling • Multilevel Feedback Queue Scheduling
- 20. • First Come First Serve, is just like FIFO(First in First out) Queue data structure, where the data element which is added to the queue first, is the one who leaves the queue first. • This is used in Batch Systems. • It's easy to understand and implement programmatically, using a Queue data structure, where a new process enters through the tail of the queue, and the scheduler selects process from the head of the queue. • A perfect real life example of FCFS scheduling is buying tickets at ticket counter. First Come First Serve Scheduling
- 21. FCFS • Calculating Average Waiting Time • For every scheduling algorithm, Average waiting time is a crucial parameter to judge it's performance. • AWT or Average waiting time is the average of the waiting times of the processes in the queue, waiting for the scheduler to pick them for execution. • Lower the Average Waiting Time, better the scheduling algorithm. • Consider the processes P1, P2, P3, P4 given in the below table, arrives for execution in the same order, with Arrival Time 0, and given Burst Time, let's find the average waiting time using the FCFS scheduling algorithm.
- 22. EXAMPLE
- 23. PROBLEMS WITH FCFS SCHEDULING Below we have a few shortcomings or problems with the FCFS scheduling algorithm: • It is Non Pre-emptive algorithm, which means the process priority doesn't matter. If a process with very least priority is being executed, more like daily routine backup process, which takes more time, and all of a sudden some other high priority process arrives, like interrupt to avoid system crash, the high priority process will have to wait, and hence in this case, the system will crash, just because of improper process scheduling. • Not optimal Average Waiting Time. • Resources utilization in parallel is not possible, which leads to Convoy Effect, and hence poor resource(CPU, I/O etc) utilization.
- 24. PROBLEMS WITH FCFS SCHEDULING • What is Convoy Effect? • Convoy Effect is a situation where many processes, who need to use a resource for short time are blocked by one process holding that resource for a long time. • This essentially leads to poor utilization of resources and hence poor performance.
- 25. SHORTEST JOB FIRST(SJF) SCHEDULING Shortest Job First scheduling works on the process with the shortest burst time or duration first. • This is the best approach to minimize waiting time. • This is used in Batch Systems. It is of two types: • Non Pre-emptive • Pre-emptive • To successfully implement it, the burst time/duration time of the processes should be known to the processor in advance, which is practically not feasible all the time. • This scheduling algorithm is optimal if all the jobs/processes are available at the same time. (either Arrival time is 0 for all, or Arrival time is same for all)
- 26. NON PRE-EMPTIVE SHORTEST JOB FIRST • Consider the below processes available in the ready queue for execution, with arrival time as 0 for all and given burst times.
- 27. PROBLEM WITH NON PRE-EMPTIVE SJF • If the arrival time for processes are different, which means all the processes are not available in the ready queue at time 0, and some jobs arrive after some time, in such situation, sometimes process with short burst time have to wait for the current process's execution to finish, because in Non Pre-emptive SJF, on arrival of a process with short duration, the existing job/process's execution is not halted/stopped to execute the short job first. • This leads to the problem of Starvation, where a shorter process has to wait for a long time until the current longer process gets executed. This happens if shorter jobs keep coming, but this can be solved using the concept of aging.
- 28. PRE-EMPTIVE SHORTEST JOB FIRST• In Preemptive Shortest Job First Scheduling, jobs are put into ready queue as they arrive, but as a process with short burst time arrives, the existing process is preempted or removed from execution, and the shorter job is executed first. •
- 29. PRIORITY CPU SCHEDULING • Preemptive Priority Scheduling: If the new process arrived at the ready queue has a higher priority than the currently running process, the CPU is preempted, which means the processing of the current process is stopped and the incoming new process with higher priority gets the CPU for its execution. • Non-Preemptive Priority Scheduling: In case of non-preemptive priority scheduling algorithm if a new process arrives with a higher priority than the current running process, the incoming process is put at the head of the ready queue, which means after the execution of the current process it will be processed.
- 30. EXAMPLE OF PRIORITY SCHEDULING ALGORITHM
- 31. PROBLEM WITH PRIORITY SCHEDULING ALGORITHM • In priority scheduling algorithm, the chances of indefinite blocking or starvation. • A process is considered blocked when it is ready to run but has to wait for the CPU as some other process is running currently. • But in case of priority scheduling if new higher priority processes keeps coming in the ready queue then the processes waiting in the ready queue with lower priority may have to wait for long durations before getting the CPU for execution. • In 1973, when the IBM 7904 machine was shut down at MIT, a low-priority process was found which was submitted in 1967 and had not yet been run.
- 32. ROUND ROBIN SCHEDULING • A fixed time is allotted to each process, called quantum, for execution. • Once a process is executed for given time period that process is preempted and other process executes for given time period. • Context switching is used to save states of preempted processes.
- 34. MULTILEVEL QUEUE SCHEDULING • A common division is made between foreground(or interactive) processes and background (or batch) processes. These two types of processes have different response-time requirements, and so might have different scheduling needs. In addition, foreground processes may have priority over background processes. • A multi-level queue scheduling algorithm partitions the ready queue into several separate queues. The processes are permanently assigned to one queue, generally based on some property of the process, such as memory size, process priority, or process type. Each queue has its own scheduling algorithm.
- 35. MULTILEVEL QUEUE SCHEDULING • Let us consider an example of a multilevel queue-scheduling algorithm with five queues: 1.System Processes 2.Interactive Processes 3.Interactive Editing Processes 4.Batch Processes 5.Student Processes
- 36. MULTILEVEL FEEDBACK QUEUE SCHEDULING • In a multilevel queue-scheduling algorithm, processes are permanently assigned to a queue on entry to the system. Processes do not move between queues. This setup has the advantage of low scheduling overhead, but the disadvantage of being inflexible. • Multilevel feedback queue scheduling, however, allows a process to move between queues. The idea is to separate processes with different CPU-burst characteristics. If a process uses too much CPU time, it will be moved to a lower-priority queue. Similarly, a process that waits too long in a lower-priority queue may be moved to a higher-priority queue. This form of aging prevents starvation.
- 38. MULTILEVEL FEEDBACK QUEUE SCHEDULING In general, a multilevel feedback queue scheduler is defined by the following parameters: • The number of queues. • The scheduling algorithm for each queue. • The method used to determine when to upgrade a process to a higher-priority queue. • The method used to determine when to demote a process to a lower-priority queue. • The method used to determine which queue a process will enter when that process needs service.
- 39. MULTIPLE-PROCESSOR SCHEDULING • In multiple-processor scheduling multiple CPU’s are available and hence Load Sharing becomes possible. However multiple processor scheduling is more complex as compared to single processor scheduling. In multiple processor scheduling there are cases when the processors are identical i.e. HOMOGENEOUS, in terms of their functionality, we can use any processor available to run any process in the queue.
- 40. APPROACHES TO MULTIPLE- PROCESSOR SCHEDULING • One approach is when all the scheduling decisions and I/O processing are handled by a single processor which is called the Master Server and the other processors executes only the user code. This is simple and reduces the need of data sharing. This entire scenario is called Asymmetric Multiprocessing. • A second approach uses Symmetric Multiprocessing where each processor is self scheduling. All processes may be in a common ready queue or each processor may have its own private queue for ready processes. The scheduling proceeds further by having the scheduler for each processor examine the ready queue and select a process to execute.
- 41. PROCESSOR AFFINITY • Processor Affinity means a processes has an affinity for the processor on which it is currently running. When a process runs on a specific processor there are certain effects on the cache memory. The data most recently accessed by the process populate the cache for the processor and as a result successive memory access by the process are often satisfied in the cache memory. Now if the process migrates to another processor, the contents of the cache memory must be invalidated for the first processor and the cache for the second processor must be repopulated. Because of the high cost of invalidating and repopulating caches, most of the SMP(symmetric multiprocessing) systems try to avoid migration of processes from one processor to another and try to keep a process running on the same processor. This is known as PROCESSOR AFFINITY. 1.Soft Affinity – When an operating system has a policy of attempting to keep a process running on the same processor but not guaranteeing it will do so, this situation is called soft affinity. 2.Hard Affinity – Hard Affinity allows a process to specify a subset of processors on which it may run. Some systems such as Linux implements soft affinity but also provide some system calls like sched_setaffinity() that supports hard affinity.
- 42. PROCESS SYNCHRONIZATION • Process Synchronization is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources. • It is specially needed in a multi-process system when multiple processes are running together, and more than one processes try to gain access to the same shared resource or data at the same time. • This can lead to the inconsistency of shared data. So the change made by one process not necessarily reflected when other processes accessed the same shared data. To avoid this type of inconsistency of data, the processes need to be synchronized with each other.
- 43. PROCESS SYNCHRONIZATION • For Example, process A changing the data in a memory location while another process B is trying to read the data from the same memory location. There is a high probability that data read by the second process will be erroneous.
- 44. CRITICAL SECTION PROBLEM • A Critical Section is a code segment that accesses shared variables and has to be executed as an atomic action. It means that in a group of cooperating processes, at a given point of time, only one process must be executing its critical section. If any other process also wants to execute its critical section, it must wait until the first one finishes.
- 45. CRITICAL SECTION PROBLEM Sections of a Program Here, are four essential elements of the critical section: • Entry Section: It is part of the process which decides the entry of a particular process. • Critical Section: This part allows one process to enter and modify the shared variable. • Exit Section: Exit section allows the other process that are waiting in the Entry Section, to enter into the Critical Sections. It also checks that a process that finished its execution should be removed through this Section. • Remainder Section: All other parts of the Code, which is not in Critical, Entry, and Exit Section, are known as the Remainder Section.
- 46. SOLUTION TO CRITICAL SECTION PROBLEM 1. Mutual Exclusion Out of a group of cooperating processes, only one process can be in its critical section at a given point of time. 2. Progress If no process is in its critical section, and if one or more threads want to execute their critical section then any one of these threads must be allowed to get into its critical section. 3. Bounded Waiting After a process makes a request for getting into its critical section, there is a limit for how many other processes can get into their critical section, before this process's request is granted. So after the limit is reached, system must grant the process permission to get into its critical section.
- 47. SOLUTION TO CRITICAL SECTION PROBLEM Synchronization Hardware Some times the problems of the Critical Section are also resolved by hardware. Some operating system offers a lock functionality where a Process acquires a lock when entering the Critical section and releases the lock after leaving it. So when another process is trying to enter the critical section, it will not be able to enter as it is locked. It can only do so if it is free by acquiring the lock itself. Mutex Locks As the synchronization hardware solution is not easy to implement for everyone, a strict software approach called Mutex Locks was introduced. In this approach, in the entry section of code, a LOCK is acquired over the critical resources modified and used inside critical section, and in the exit section that LOCK is released. As the resource is locked while a process executes its critical section hence no other process can access it.
- 48. SOLUTION TO CRITICAL SECTION PROBLEM • Semaphores: These are integer variables that are used to solve the critical section problem by using two atomic operations, wait and signal that are used for process synchronization. The definitions of wait and signal are as follows − • Wait: The wait operation decrements the value of its argument S, if it is positive. If S is negative or zero, then no operation is performed. wait(S) { while (S<=0); S--; }
- 49. SOLUTION TO CRITICAL SECTION PROBLEM Signal: The signal operation increments the value of its argument S. signal(S) { S++; }