Machine Learning Models in Production

Data Scientists and Machine Learning practitioners, nowadays, seem to be churning out models by the dozen and they continuously experiment to find ways to improve their accuracies. They also use a variety of ML and DL frameworks & languages , and a typical organization may find that this results in a heterogenous, complicated bunch of assets that require different types of runtimes, resources and sometimes even specialized compute to operate efficiently. But what does it mean for an enterprise to actually take these models to "production" ? How does an organization scale inference engines out & make them available for real-time applications without significant latencies ? There needs to be different techniques for batch (offline) inferences and instant, online scoring. Data needs to be accessed from various sources and cleansing, transformations of data needs to be enabled prior to any predictions. In many cases, there maybe no substitute for customized data handling with scripting either. Enterprises also require additional auditing and authorizations built in, approval processes and still support a "continuous delivery" paradigm whereby a data scientist can enable insights faster. Not all models are created equal, nor are consumers of a model - so enterprises require both metering and allocation of compute resources for SLAs. In this session, we will take a look at how machine learning is operationalized in IBM Data Science Experience (DSX), a Kubernetes based offering for the Private Cloud and optimized for the HortonWorks Hadoop Data Platform. DSX essentially brings in typical software engineering development practices to Data Science, organizing the dev->test->production for machine learning assets in much the same way as typical software deployments. We will also see what it means to deploy, monitor accuracies and even rollback models & custom scorers as well as how API based techniques enable consuming business processes and applications to remain relatively stable amidst all the chaos. Speaker Piotr Mierzejewski, Program Director Development IBM DSX Local, IBM

























Machine Learning Models in Production
- 1. Operationalizing Machine Learning Models in production —
- 2. What many people think ML is “Given inputs (x) and answer (y) . . . . . . learn a function f(x) y” Model Development
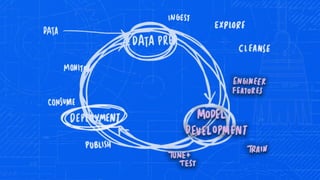
- 3. What real-world ML actually looks like:
- 8. Operationalizing ML is a challenge Data science pipelines > act on real-world data > impact business activities as they happen Transactions + Decisions in a closed-loop Goes beyond traditional BI
- 9. 5 tenets for operationalizing ML Analytics-Ready Data Managed Trusted Quality, Provenance and Explainability Resilient Measurable Monitor + Measure Evolution Deliver & ImproveAt Scale & Always On
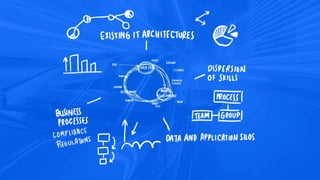
- 10. Where’s my data ? Analytics-Ready Data Managed • access to data with techniques to track & deal with sensitive content • data virtualization • automate-able pipelines for data preparation, transformations
- 11. How can I convince you to use my model ? • provenance of data used to train & test • lineage of the model - transforms , features & labels • model explainability - algorithm, size of data, compute resources used to train & test, evaluation thresholds, repeatable Trusted Quality, Provenance and Explainability How was the model built ?
- 12. Dependable for your business Resilient At Scale & Always On • reliable & performant for (re-)training • highly available, low latency model serving at real time even with sophisticated data prep • outage free model /version upgrades in production ML infused in real-time, critical business processes
- 13. Is my model still good enough ? Measurable Monitor + Measure • latency metrics for real-time scoring • frequent accuracy evaluations with thresholds • health monitoring for model decay
- 14. Growth & Maturity Evolution Deliver & Improve • versioning: champion/challenger, experimentation and hyper-parameterization • process efficiencies: automated re-training auto deployments (with curation & approvals)
- 15. Governed Data Science - is also a team sport Data Engineer CDO (Data Steward) Data Scientist Organizes • Data & Analytics Asset Enterprise Catalog • Lineage • Governance of Data & Models • Audits & Policies • Enables Model Explainability Collects Builds data lakes and warehouses Gets Data Ready for Analytics Analyzes Explores, Shapes data & trains models Exec App. Developer Problem Statement or target opportunity Finds Data Explores & Understands Data Collects, Preps & Persists Data Extracts features for ML Train Models Deploy & monitor accuracy Trusted Predictions Experiments Sets goals & measures results Real-time Apps & business processes Infuses ML in apps & processes PRODUCTION • Secure & Governed • Monitor & Instrument • High Throughput -Load Balance & Scale • Reliable Deployments - outage free upgrades Auto-retrain & upgrade Refine Features, Lineage/Relationships recorded in Governance Catalog Development & prototyping Production Admin/Ops
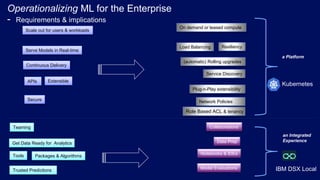
- 16. Operationalizing ML for the Enterprise - Requirements & implications 16 On demand or leased compute Scale out for users & workloads Serve Models in Real-time APIs Load Balancing Resiliency Service Discovery Role Based ACL & tenancy Network PoliciesSecure Trusted Predictions a Platform Notebooks & IDEs Model Evaluations an Integrated Experience Continuous Delivery (automatic) Rolling upgrades Teaming Collaborations Extensible Get Data Ready for Analytics Data Prep Plug-n-Play extensibility Kubernetes IBM DSX Local Tools Packages & Algorithms
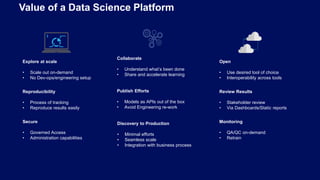
- 17. Explore at scale • Scale out on-demand • No Dev-ops/engineering setup Reproducibility • Process of tracking • Reproduce results easily Secure • Governed Access • Administration capabilities Collaborate • Understand what’s been done • Share and accelerate learning Publish Efforts • Models as APIs out of the box • Avoid Engineering re-work Discovery to Production • Minimal efforts • Seamless scale • Integration with business process Open • Use desired tool of choice • Interoperability across tools Review Results • Stakeholder review • Via Dashboards/Static reports Monitoring • QA/QC on-demand • Retrain Value of a Data Science Platform
- 18. Data Science Experience DSX is an Open Platform Add your favorite libraries Publish Open APIs for secure ML applications
- 19. Organize Models, scripts & other assets A “Project” • just a folder of assets grouped together • “models” (say serialized pickle or R objects) aren’t everything o you still need scripts for data wrangling or for scheduled evaluations and interactive notebooks and apps (R Shiny etc.) o scripts used for training & testing need to be recorded (remember repeatable ?) o as well as sample data sets & references to remote data sources o perhaps even your own home-grown libraries & modules.. • also a git repository ! • why ? Easy to share, version & publish – across different teams /personas • track history of commit changes & truly co-develop Easily enable a CICD pipeline for Machine Learning ! • git tag a project and deploy to production the “release”. (Reproducible snapshots of assets !)
- 20. Build & Collaborate Collaborate within git-backed projects
- 21. Essential tools for Data Scientists Jupyter notebook Environment Python 2.7/3.5 with Anaconda Scala, R R Studio Environment with > 300 packages, R Markdown, R Shiny Zeppelin notebook with Python 2.7 with Anaconda
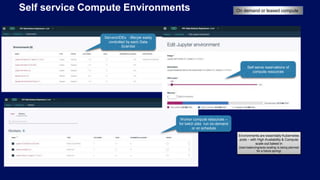
- 22. Self service Compute Environments Servers/IDEs - lifecyle easily controlled by each Data Scientist Self-serve reservations of compute resources Worker compute resources – for batch jobs run on-demand or on schedule Environments are essentially Kubernetes pods – with High Availability & Compute scale-out baked in (load-balancing/auto-scaling is being planned for a future spring) On demand or leased compute
- 23. Extend .. – Roll your own Environments Add libs/packages to the existing Jupyter, Rstudio , Zeppelin IDE Environments or introduce new Job “Worker” environments https://content-dsxlocal.mybluemix.net/docs/content/local/images.html DSX Local provides a Docker Registry (and replicated for HA) as well. These images get managed by DSX and is used to help build out custom Environments Plug-n-Play extensibility Reproducibility, courtesy of Docker images
- 24. Automate .. Jobs – trigger on-demand or by a schedule. such as for Model Evaluations, Batch scoring or even continuous (re-) training
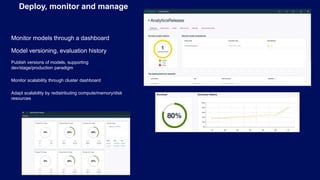
- 25. Monitor models through a dashboard Model versioning, evaluation history Publish versions of models, supporting dev/stage/production paradigm Monitor scalability through cluster dashboard Adapt scalability by redistributing compute/memory/disk resources Deploy, monitor and manage
- 26. Deployment manager - Project Releases Project releases Deployed & (delta) updatable Current git tag
- 27. Bring in a new “release” to production New Releases - from a “Source” Project in the same cluster New Releases - from a “Source” Project pulled from github/bitbucket New Releases - from a “Source” Project created from a .tar.gz package
- 28. Expose a ML model via a REST API replicas for load balancing pick a version to expose (multiple deployments are possible too..) Optionally reserve compute scoring end-point Model pre-loaded into memory inside scoring containers
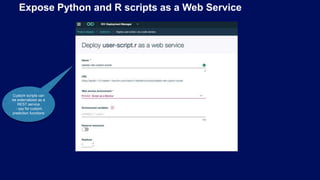
- 29. Expose Python and R scripts as a Web Service Custom scripts can be externalized as a REST service - say for custom prediction functions
- 30. DSX Local Architecture overview Customer Systems DSX Local Cluster Relational Data Stores (DB2,Oracle, Teradata, etc.) LDAP/AD (Authentication) Spark Cluster (via Livy) Hadoop (HDFS, Hive, IBM Big SQL) Admin interfaces Metering Monitoring Kubernetes Master Components Platform Control & Management Redis (session store) Shared user volume Cloudant (metadata) Storage Management Services registry vol (dockeri mages) KubernetesCluster csv files, projects, models Kubernetes cluster spread across multiple servers Data Scientist – web browser & API • Start with 3 nodes with HA enabled • Expand as needed GitHub & GitHub Enterprise (projects & assets) Kubernetes Persistent Volumes Integrations & Connections Project services, Data Sources & .git Spark, Spark-ML Environments: Resource mgmt & Jobs Core Services User Management & tokens DSX Hadoop Integration Service Custom Scorers Model Evaluations Project Releases: Deployment/Scale-out load balancing & Monitoring Model Mgmt & Deployment + operations Scorers Package & Image mgmt Jupyter (anaconda-python, scala, R) Tensorflow-GPU Zeppelin Scripts (.py, .R) & Jobs Data Scientist Dev environment RStudio (and Shiny Apps) Projects, Publish & collaborations Data Refinery SPSS Modeler (add-on) Decision Opt/CPLEX (add-on) H20 Flows (add-on) Jobs & Scheduling Hosted Apps Webservices (Python,R) Batch Scoring Jupyter notebook apps R.Shiny apps
- 31. Operationalizing Machine Learning Models in production — Summary
- 32. 5 tenets for operationalizing ML Analytics-Ready Data Managed Trusted Quality, Provenance and Explainability Resilient Measurable Monitor + Measure Evolution Deliver & ImproveAt Scale & Always On IBM DSX LocalKubernetes