Inside GitHub
•
90 likes•69,275 views

This document provides a summary of Chris Wanstrath's talk about the history and technical details of GitHub. It begins with Chris introducing himself and stating he will discuss GitHub. He then provides a brief history of GitHub starting as a git hosting site and evolving into a social coding platform. The rest of the talk focuses on the technical aspects including the web framework, application servers, databases, caching, jobs processing, search, git implementation, file serving, and monitoring.
Report
Share



























































































































































Inside GitHub
- 2. My name is Chris Wanstrath. I go by @defunkt online.
- 3. inside github And today I’m going to talk about GitHub.
- 4. inside github That’s me.
- 5. GitHub is what we like to call “social coding.”
- 6. You can see what your friends are doing from your dashboard or news feed
- 7. Everyone has a profile showing off their code and activity
- 8. And you can do things like leave comments on commits.
- 9. But it wasn’t always like this.
- 10. Originally we just wanted to make a git hosting site. In fact, that was the first tagline.
- 11. git repository hosting git repository hosting. That’s what we wanted to do: give us and our friends a place to share git repositories.
- 12. It’s not easy to setup a git repository. It never was. But back in 2007 I really wanted to.
- 13. I had seen Torvalds’ talk on YouTube about git. But it wasn’t really about git - it was more about distributed version control. It answered many of my questions and clarified DVCS ideas. I still wasn’t sold on the whole idea, and I had no idea what it was good for.
- 14. CVS is stupid But when Torvalds says “CVS is stupid”
- 15. and so are you “and so are you,” the natural reaction for me is...
- 16. To start learning git.
- 17. At the time the biggest and best free hosting site was repo.or.cz.
- 18. Right after I had seen the Torvalds video, the god project was posted up on repo.or.cz I was interested in the project so I finally got a chance to try it out with some other people.
- 19. Namely this guy, Tom Preston-Werner. Seen here in his famous “I put ketchup on my ketchup” shirt.
- 20. I managed to make a few contributions to god before realizing that repo.or.cz was not different. git was not different. Just more of the same - centralized, inflexible code hosting.
- 21. This is what I always imagined. No rules. Project belongs to you, not the site. Share, fork, change - do what you want. Give people tools and get out of their way. Less ceremony.
- 22. So, we set off to create our own site. A git hub - learning, code hosting, etc.
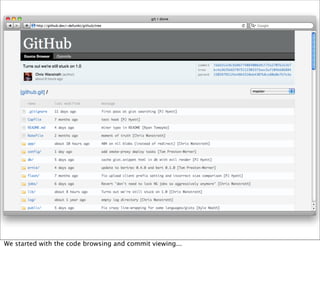
- 23. We started with the code browsing and commit viewing...
- 24. But once we added the current version of the dashboard, we knew this was different.
- 25. And eventually “git repository hosting” gave way to “social coding”
- 26. What’s special about GitHub is that people use the site in spite of git. Many git haters use the site because of what it is - more than a place to host git repositories, but a place to share code with others.
- 27. a brief history So that’s how it all started. Now I want to (briefly) cover some milestones and events.
- 28. 2007 october The first commit was on a Friday night in October, around 10pm.
- 29. 2008 january We launched the beta in January at Steff’s on 2nd street in San Francisco’s SOMA district. The first non-github user was wycats, and the first project was merb-core. They wanted to use the site for their refactoring and 0.9 branch.
- 30. 2008 april A few short months after that we launched to the public.
- 31. 2009 january In January of this year, we were awared the “Best Bootstrapped Startup” by TechCrunch.
- 32. 2009 april Then in April we were featured as some of the best young tech entrepreneurs in BusinessWeek. (Finally something to show mom)
- 33. 2009 june Our Firewall Install, something we’d been talking about since practically day one, was launched in June of 2009.
- 34. 2009 september And in September we moved to Rackspace, our current hosting provider. (Which some of you may have noticed.)
- 35. Along the way we managed to pick up Scott Chacon, our VP of R&D
- 36. Tekkub, our level 80 support druid
- 37. Melissa Severini, who keeps us all in check
- 38. Kyle Neath, who makes the site pretty
- 39. And Ryan Tomayko, who helps keep the site running smoothly.
- 40. Oh yeah, and the other founders: PJ and Tom.
- 41. github.com That’s where we’re at today. So let’s talk about the technical details of the website: github.com
- 42. .com as opposed to fi, which I’m not going to get into today. You’ll have to invite PJ out if you want to hear about that.
- 43. the web app As everyone knows, a web “site” is really a bunch of different components. Some of them generate and deliver HTML to you, but most of them don’t. Either way, let’s start with the HTMLy parts.
- 44. rails We use Ruby on Rails 2.2.2 as our web framework. It’s kept up to date with all the security patches and includes custom patches we’ve added ourselves, as well as patches we’ve cherry-picked from more recent versions of Rails.
- 45. We found out Rails was moving to GitHub in March 2008, after we had reached out to them and they had turned us down. So it was a bit of a surprise.
- 46. rails But there are entire presentations on Rails, so I’m not going to get further into it here. As for whether it scales or not, we’ll let you know when we find out. Because so far it hasn’t come close to presenting a problem.
- 47. rack One of the big features in Rails 2.3 is Rack support.
- 48. We badly wanted this, but didn’t want to invest the time upgrading. So using a few open source libraries we’ve wrapped our Rails 2.2.2 instance in Rack.
- 49. Now we can use awesome Rack middleware like Rack::Bug in GitHub
- 50. In fact, the Coderack competition is about to open voting to the public this week. Coders created and submitted dozens of Rack middleware for the competition. I was a judge so I got the see the submissions already. Some of my favorite were
- 53. talison / rack-mobile-detect sets the X_MOBILE_DEVICE header to the mobile device, if recognized
- 54. unicorn We use unicorn as our application server - master / worker - 16 workers - preforking
- 55. unicorn - instant restart after kill - hard 30s request timeouts - control ram growth
- 56. unicorn - 0 downtime deploys - protects against bad rails startup - migrations handled old fashioned way
- 57. nginx For serving static content and slow clients, we use nginx nginx is pretty much the greatest http server ever it’s simple, fast, and has a great module system
- 58. nginx Limit Zone Limit simultaneous connections from a client
- 59. nginx Limit Requests Limit frequency of connections from a client Anti-DDOS
- 60. nginx I see many people using Rack to do what the Limit modules do. Don’t.
- 61. nginx memcached memcached support can serve directly from memcached
- 63. git The next major part of GitHub is git
- 64. grit We wrote an open source library called Grit which lets us use git from Ruby
- 65. mojombo / grit you can get it here it originally shelled out to git and just parsed the responses. which worked well for a long time.
- 66. grit File.read() Eventually we realized, however, that File.read() can be 100 times faster
- 68. One of the first things Scott worked on was rewriting the core parts of Grit to be pure Ruby Basically a Ruby implementation of Git
- 69. mojombo / grit And that’s what we run now
- 70. smoke Kinda. Eventually we needed to move of our git repositories off of our web servers Today our HTTP servers are distinct from our git servers. The two communicate using smoke
- 71. smoke “Grit in the cloud” Instead of reading and writing from the disk, Grit makes Smoke calls The reading and writing then happens on our file servers
- 72. bert-rpc Rather than use Protocol Buffers or Thrift or JSON-RPC, Smoke uses BERT-RPC
- 73. bert-rpc bert : erlang :: json : javascript BERT is an erlang-based protocol BERT-RPC is really great at dealing with large binaries Which is a lot of what we do
- 74. bert-rpc we have four file servers, each running bert-rpc servers our front ends and job queue make RPC calls to the backend servers
- 75. mojombo / bertrpc You can grab bert-rpc on GitHub
- 76. mojombo / bertrpc Or if you just want to play with BERT
- 77. chimney We have a proprietary library called chimney It routes the smoke. I know, don’t blame me.
- 78. chimney All user routes are kept in Redis Chimney is how our BERT-RPC clients know which server to hit It falls back to a local cache and auto-detection if Redis is down
- 79. chimney It can also be told a backend is down. Optimized for connection refused but in reality that wasn’t the real problem.
- 80. proxymachine All anonymous git clones hit the front end machines the git-daemon connects to proxymachine, which uses chimney to proxy your connection between the front end machine and the back end machine (which holds the actual git repository) very fast, transparent to you
- 81. mojombo / proxymachine proxymachine can be used to proxy any kind of tcp connection open source
- 82. ssh Sometimes you need to access a repository over ssh In those instances, you ssh to an fe and we tunnel your connection to the appropriate backend To figure that out we use chimney
- 83. jobs We do a lot of work in the background at GitHub
- 84. resque Currently we use a system called Resque.
- 85. defunkt / resque You can grab it on GitHub
- 86. resque - dealing with pushes - web hooks - creating events in the database - generating GitHub Pages - clearing & warmingcaches - search indexing
- 87. queues In Resque, a queue is used as both a priority and a localization technique By localization I mean, “where your workers live”
- 88. queues critical,high,low these three run on our front end servers Resque processes them in this order
- 89. queues page GitHub Pages are generated on their own machine using the `page` queue
- 90. queues archive And tarball and zip downloads are created on the fly using the `archive` queue on our archiving machines
- 91. search On GitHub, you can search code, repositories, and people
- 92. solr Solr is basically an HTTP interface on top of Lucene. This makes it pretty simple to use in your code. We use solr because of its ability to incrementally add documents to an index.
- 93. Here I am searching for my name in source code
- 94. solr We’ve had some problems making it stable but luckily the guys at Pivotal have given us some tips Like bumping the Java heap size. Whatever that means
- 95. database Our database story is pretty uninteresting
- 96. mysql We use mysql 5
- 97. master / slave All reads and writes go to the master We use the slave for backups and failover
- 98. caching On the site we do a ton of caching using memcached
- 99. fragments We cache chunks of HTML all over Usually they are invalidated by some action
- 100. fragments Formerly we invalidated most of our fragments using a generation scheme, where you put a number into a bunch of related keys and increment it when you want all those caches to be missed (thus creating new cache entries with fresh data)
- 101. fragments But we had high cache eviction due to low ram and hardware constraints, and found that scheme did more harm than good. We also noticed some cached data we wanted to remain forever was being evicted due to the slabs with generational keys filling up fast
- 102. page We cache entire pages using nginx’s memcached module Lots of HTML, but also other data which gets hit a lot and changes rarely:
- 103. page - network graph json - participation graph data Always looking to stick more into page caches
- 104. object We do basic object caching of ActiveRecord objects such as repositories and users all over the place Caches are invalidated whenever the objects are saved
- 105. associations We also cache associations as arrays of IDs Grab the array, then do a get_multi on its contents to get a list of objects That way we don’t have to worry about caching stale objects
- 106. walker We also have a proprietary caching library called Walker
- 107. walker It originally walked trees and cached them when someone pushed But now it caches everything related to git:
- 108. walker - commits - diffs - commit listing - branches - tags - everything
- 109. Every git-related page load hits Walker a lot
- 110. walker For most big apps, you need to write a caching layer that knows your business domain Generic, catch-all caching libraries probably won’t do
- 111. events An example of this is our events system
- 113. This is one fragment
- 114. Each of these is a fragment
- 115. They’re also cached as objects
- 116. As well as a list of ids
- 117. And that’s just for the dashboard...
- 118. optimizations So what other optimizations have we done
- 119. asset servers Well we do the common trick of serving assets from multiple subdomains
- 121. sha asset id Instead of using timestamps for asset ids, which may end up hitting the disk multiple times on each request, we set the asset id to be the sha of the last commit which modified a javascript or css file
- 122. sha asset id /css/bundle.css?197d742e9fdec3f7 /js/bundle.js?197d742e9fdec3f7 Now simple code changes won’t force everyone to re-download the css or js bundles
- 123. bundling For bundling itself, we use
- 124. bundling yui’s compressor for css and
- 125. bundling google’s closure compiler for javascript we don’t use the most aggressive setting because it means changing your javascript to appease the compression gods, which we haven’t committed to yet
- 126. scripty 301 Again, for most of these tricks you need to really pay attention to your app. One example is scriptaculous’ wiki
- 127. scripty 301 When we changed our wiki URL structure, we setup dynamic 301 redirects for the old urls. Scriptaculous’ old wiki was getting hit so much we put the redirect into nginx itself - this took strain off our web app and made the redirects happen almost instantly
- 128. ajax loading We also load data in via ajax in many places. Sometimes a piece of information will just take too long to retrieve In those instances, we usually load it in with ajax
- 131. If Walker sees that it doesn’t have all the information it needs, it kicks off a job to stick that information in memcached.
- 132. We then periodically hit a URL which checks if the information is in memcached or not. If it is, we get it and rewrite the page with the new information.
- 133. We use this same trick on the Network Graph
- 134. Fork Queue
- 135. ajax loading and anywhere else it makes sense.
- 136. comet loading very soon this will all be comet, though
- 137. monitoring what do we use for monitoring?
- 138. nagios Our support team monitors the health of our machines and core services using nagios. I don’t really touch the thing.
- 139. Here’s a screenshot from my IE browser, complete with the ICQ plugin
- 140. resque web We monitor our queue using Resque’s included Sinatra app
- 142. haystack We use an in-house app called Haystack to monitor arbitrary information, tracked as JSON.
- 143. Here’s an example of Haystack’s “exceptions” view
- 144. collectd We also use collectd to monitor load, RAM usage, CPU usage, and other app-related metrics
- 145. pingdom pingdom sends us SMSes when the site is down it’s nice
- 146. tender tender is what we use for customer support
- 147. it works incredibly well, and they’re constantly improving it
- 148. testing Our testing setup is pretty standard
- 149. test unit We mostly use Ruby’s test/unit. We’ve experimented with other libraries including test/spec, shoulda, and RSpec, but in the end we keep coming back to test/unit
- 150. git fixtures As many of our fixtures are git repositories, we specify in the test what sha we expect to be the HEAD of that fixture. This means we can completely delete a git repository in one test, then have it back in pristine state in another. We plan to move all our fixtures to a similar git-system in the future.
- 151. ci joe We use ci joe, a continuous integration server, to run on tests after each push. He then notifies us if the tests fail.
- 154. defunkt / cijoe You can grab him at github
- 155. staging We also always deploy the current branch to staging This means you can be working on your branch, someone else can be working on theirs, and you don’t need to worry about reconciling the two to test out a feature One of the best parts of Git
- 156. security
- 157. github.com/ security having a security page really helps
- 158. security@ github.com we get weekly emails to our security email (that people find on the security page) and people are always grateful when we can reassure them or a answer their question
- 159. consultant if you can, find a security consultant to poke your site for XSS vulnerabilities having your target audience be developers helps, too
- 160. backups backups are incredibly important don’t just make backups: ensure you can restore them, as well
- 161. sql we keep nightly, off-site backups of our sql databases
- 162. git and the same for all our git repositories