Building stateful systems with akka cluster sharding

We’re at another juncture in enterprise computing where there is a large push behind a big vision of the future, the push towards serverless architectures—a world where less human oversight and participation is required in operations. At this time, serverless computing is so hot right now. A promise of ‘Opsless’, cloud-native, pay-for-what-you-use functions does sound great, but the current incarnation of serverless that most people think of–Function as a Service (FaaS)–is limited to ephemeral, stateless, and short-lived functions. Amazon Lambda caps their lifespan to 15 minutes, for example. This is not what we need out of a general platform for building modern real-time, data-centric applications and systems. What we do need are scalable, stateful services that can operate on cloud infrastructure as if they are stateless. Explore how to make your next application stateful, providing a better understanding of the technology landscape, challenges and pitfalls, and successful methods with Akka Cluster Sharding





































Building stateful systems with akka cluster sharding
- 1. Building Stateful Systems with Akka Cluster Sharding Presented By: Hugh Mckee Himanshu Gupta Anjali Sharma
- 2. Before we start… 1. Please use the Q&A section to post your questions and raise your hand after the webinar to discuss your questions with experts 2. Session is recorded and we will be sharing with you after the session. 3. We will send a follow up mail with all links and downloads soon.
- 3. About the Speakers Hugh Mckee Developer Advocate at Lightbend ● Speaker and advocate for development of Reactive Cloud Native Systems Himanshu Gupta Akka Expert and Sr. Lead Consultant at Knoldus Inc. ● Speaker for Fast Data Systems and Reactive Application Engineer. Anjali Sharma Software Consultant at Knoldus Inc. ● Developer Engineer specialised in Scala, Akka and Spark.
- 4. Agenda What is Cluster Sharding? Understanding Entity/Shard Ids Sharding Example What are Stateful Systems? How to use Stateful Actors? No more Blocking Passivation
- 5. About Knoldus Product Engineering for Innovative Organizations Keeping your business competitive & future-ready with extremely well-engineered systems through the unwavering pursuit of emerging technology, high-quality engineers, processes, and practices
- 6. REACTIVE PRODUCTS Microservices & API ● ● ● ● ● ENTERPRISE DATA PROGRAM Data Lake ● ARTIFICIAL INTELLIGENCE Machine Learning Data Science Deep Learning ● ● ● ● BLOCKCHAIN ● ● ● Knoldus Practice Areas Fast Data ● ● ● Agile Transformation Reactive UI/UX Test Automation Practice Reactive DevOps Product Engineering
- 7. Knoldus Global Presence 10+ Years Years of Profitable Growth 175+ Engineers Reactive products, Fast Data strategy, AI 04 Offices Toronto, Chicago, Singapore, India 20+ Customers Multi-year Global Customers
- 8. About Lightbend Lightbend empowers organizations to quickly implement any digitally transformative business strategy—no matter how ambitious, challenging or innovative. We take care of the architectural hurdles and back-end complexity of building globally distributed, cloud-native application environments. Lightbend enables development teams with the technology and expertise required to build applications that support business critical decisions. That’s why Global 2000 enterprises turn to us. Unleash the full power of the cloud with Lightbend.
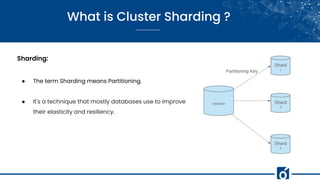
- 9. What is Cluster Sharding ? Sharding: ● The term Sharding means Partitioning. ● It's a technique that mostly databases use to improve their elasticity and resiliency.
- 10. What is Cluster Sharding ? Database Sharding: ● Records are distributed across nodes, using a shard key or a partition key. ● A router which directs requests to the appropriate shard or partition. ● Even after sharding, it may lead to bottleneck.
- 11. What is Cluster Sharding ? Akka Cluster Sharding: ● The Akka toolkit provides cluster sharding as a way to introduce sharding into your application. ● Instead of distributing database records across a cluster, we are going to distribute actors across the cluster. ● Each actor is then going to act as a consistency boundary, for the data that it manages.
- 12. Components of Cluster Sharding ? Entities: ● The basic unit in akka cluster sharding is an actor called an entity. ● There is only one entity per entity ID in the cluster. ● Messages are addressed to the entity ID and processed by the entity. This allows the entity to act as a single source of truth, acting as a consistency boundary for the data that it manages.
- 13. Components of Cluster Sharding ? Shards: ● Entities are distributed in shards. ● Each shard manages a number of entities and creates entity actors on demand. ● And each shard has a unique ID mapping entities to a shard ID is how we control the distribution.
- 14. Components of Cluster Sharding ? Shard Region: ● Shards gets distribute into different shard regions. Each shard region contains a number of shards. ● For a type of entity, there is usually one shard region per JVM. ● A shard region will look up the location of the shard for the entity the first time when it doesn’t already know its location, and then forwards the messages to the appropriate node region, and the entity.
- 15. Components of Cluster Sharding ? Shard Coordinator: ● The shard coordinator is responsible to manage shards, it’s a cluster singleton. ● It’s responsible for ensuring that the system knows where to send messages addressed to a specific entity. ● And it decides which shard gets to live in which region, which is to stay on which node.
- 16. Understanding Entity ID ● To uniquely identify each entity, entityIDs are used. ● They are used to create name of the actor and hence must be unique across the entire cluster. ● Entity Id Extractors are used to process each incoming message and separate it into an entity id and a message to be passed to the entity actor. case class MyMessage(entityID: String, message: String) val idExtractor: ShardRegion.ExtractorEntityId = { case MyMessage(id, message) => (id, message) }
- 17. Understanding Shard ID val shardIdExtractor: ShardRegion.ExtractShardId = { case MyMessage(id, _) => (Math.abs(id.hashCode % totalShards)).toString } ● To identify shards, Shard Ids are used. ● Entities are mapped to a Shard Id. ● An Extractor function is used to process each incoming message and produce Shard Id. ● Best practice is to aim for roughly 10 shards per node. ● When selecting a ShardId and producing an extractor it is important to consider how the Shards will be balanced. ● Poor sharding strategy will produce hotspots which result in uneven workload.
- 18. Sharding Example val shards = ClusterSharding(myActorSystem).start( “shardedActors”, MyShardedActor.props(), ClusterShardingSettings(myActorSystem), idExtractor, shardIdExtractor ) ● ClusterSharding.start is called on each node that will be hosting shards. ● The role of the above block of code is to provide an actor ref which is the reference for the local shard region. ● For sending messages we have to take the shard region actor ref and we send it the message we’re expecting. ● Messages are first sent to the entities, through the local shard region. shards ! MyMessage(entityId, someMessage)
- 19. What are Stateful Systems? First, stateless systems CART-1234 CART-1234 Temp Hot State Cold State 1. Retrieve state 2. Change state 3. Save state 4. Forget state Retrieve
- 20. What are Stateful Systems? First, stateless systems CART-1234 CART-1234 Temp Hot State Cold State 1. Retrieve state 2. Change state 3. Save state 4. Forget state Change
- 21. What are Stateful Systems? First, stateless systems CART-1234 CART-1234 Temp Hot State Cold State 1. Retrieve state 2. Change state 3. Save state 4. Forget state Save
- 22. What are Stateful Systems? First, stateless systems CART-1234Cold State 1. Retrieve state 2. Change state 3. Save state 4. Forget state
- 23. What are Stateful Systems? CART-1234 CART-1234Cold State CART-1234 Contention handled by the database First, stateless systems
- 24. What are Stateful Systems? CART-1234 CART-1234 Hot State Cold State Stateful systems Retrieve state on 1st access
- 25. What are Stateful Systems? CART-1234 CART-1234 Hot State Cold State Stateful systems Save incremental state changes
- 26. What are Stateful Systems? Stateful systems CART-1234 CART-1234 Load Balancer
- 27. What are Stateful Systems? Stateful systems CART-1234 CART-1234 Load Balancer
- 28. How to use Stateful Actors Akka Cluster Sharding https://github.com/mckeeh3/akka-typed-java-cluster-sharding.git
- 29. No More Blocking Why blocking inside an Actor is bad? Blocking inside an actor can tie-up a thread inside an Actor which cannot be reused by other Actors when required. Hence it creates resource contention. Note: Generally DB operations are blocking in an application.
- 30. Non-Blocking Requires Extra Care ● Next message can’t be processed until the previous message is complete. ● What to do in case a non-blocking operation fails?
- 31. Handling Non-Blocking Failures ● We need to be careful when updating data asynchronously in DB. ● Because if the update fails, then state will become inconsistent.
- 32. Handling Non-Blocking Failures ● We should fail the actor so that it can restart itself. ● Because on restart the actor will reload the state from DB, and the state will be consistent.
- 33. Passivation ● Keeping the state of all the actors in memory is a huge risk. ● As it can fill the memory fast and cause OOM (OutOfMemory exception). ● Hence Akka Cluster Sharding provides a way to remove idle actors from memory known as Passivation.
- 34. How Passivation works? ● Passivation works on a configurable time span. ● For every actor the time of last processed is tracked. ● In case an actor has not processed a message for the configured time span, then it is removed from the Actor System.
- 35. How Passivation works? (contd.) ● Now, as soon as the actor starts receiving messages, it’s state is loaded back from the DB. ● Since the actor was removed from the memory, all it’s state was lost. Note: While the actor was not present in the memory, it’s messages are stored in buffer. Hence they remain safe.
- 36. Configuring Passivation ● Using passivate-idle-entity-after setting we can configure when entities will passivate. ● By default it’s value is 120 seconds.
- 37. Demo
- 38. Questions?
- 39. References ● Reactive Banking Sample Code ● Akka Cluster Sharding - Scala