音楽波形データからコードを推定してみる
•
0 likes•2,707 views

音楽の波形データを題材にDeep Learningを用いて楽器や楽曲のコード推定を試してみた取り組みを紹介します。 スライド中で使っている音声はこちらから試聴できます:https://matsuken92.github.io/wav_music_analysis/index.html 動画はこちらのリンクから: https://matsuken92.github.io/wav_music_analysis/video/enlarge_wave.mp4
























音楽波形データからコードを推定してみる
- 1. 2022.1.27 Ken’ichi Matsui 株式会社ディー・エヌ・エー + 株式会社 Mobility Technologies 音楽波形データからコード を推定してみる 技術共有会発表資料
- 2. 社外秘 2 ⾃⼰紹介(松井 健⼀) 株式会社Mobility Technologies AI技術開発部 データサイエンスグループ グループマネージャー(Kaggle Master) (株式会社 ディー・エヌ・エーより出向) 最近のプロジェクト • ドライブデータの解析 (DRIVE CHART) • https://drive-chart.com/ 著書 • New!「ワンランク上を⽬指す⼈のためのPython実践活⽤ガイド」共著(2022年3⽉予定) • 「ソフトウェアデザイン 2020年10⽉号 【第1特集】Pythonではじめる統計学 2-4章」著 • 「アクセンチュアのプロフェッショナルが教える データ・アナリティクス実践講座」共著 楽器経験 • ギター、ベース、ドラムを嗜みます。DTMも好きでCUBASE使いです。 経歴 ⼤⼿SIer ⇒ ⼤⼿通信キャリア ⇒ 外資系コンサルティングファーム ⇒ 現職 NEW!
- 5. 時間 振幅 ※ 振幅は無単位らしい (参考:https://oku.edu.mie-u.ac.jp/~okumura/blog/node/2426 ) 波形データとは 音と空気の振動の波なのでそれをデータ化したもの。データ化するにあたってサ ンプリングレート(横軸方向)とビット深度(縦軸方向)という仕様がある。 1. サンリングレートの例:44100 hz(1秒間に44100回データを記録) 2. ビット深度の例: 32bit( 2!" =4294967296段階の音量) ) データの個数が44100個のところで1秒 振幅方向の 解像度が 2!" 段階 空気 密度 密 疎
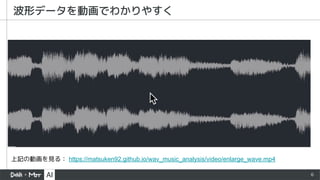
- 6. 6 波形データを動画でわかりやすく 上記の動画を見る: https://matsuken92.github.io/wav_music_analysis/video/enlarge_wave.mp4
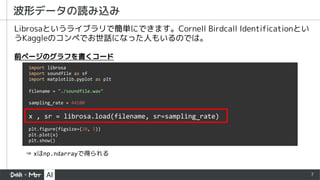
- 7. 7 波形データの読み込み Librosaというライブラリで簡単にできます。Cornell Birdcall Identificationとい うKaggleのコンペでお世話になった人もいるのでは。 import librosa import soundfile as sf import matplotlib.pyplot as plt filename = "./soundfile.wav" sampling_rate = 44100 x , sr = librosa.load(filename, sr=sampling_rate) plt.figure(figsize=(20, 5)) plt.plot(x) plt.show() 前ページのグラフを書くコード ⇒ xはnp.ndarrayで得られる
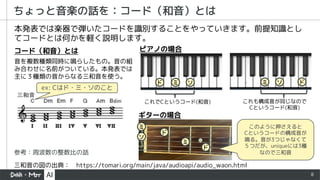
- 8. 8 ちょっと音楽の話を:コード(和音)とは 本発表では楽器で弾いたコードを識別することをやっていきます。前提知識とし てコードとは何かを軽く説明します。 コード(和音)とは 三和音の図の出典: https://tomari.org/main/java/audioapi/audio_waon.html 音を複数種類同時に鳴らしたもの。音の組 み合わせに名前がついている。本発表では 主に3種類の音からなる三和音を使う。 参考:周波数の整数比の話 ex: Cはド・ミ・ソのこと ド ミ ソ これでCというコード(和音) ド ミ ソ これも構成音が同じなので Cというコード(和音) ピアノの場合 ギターの場合 ド ミ ソ ド ミ このように押さえると Cというコードの構成音が 鳴る。音が3つじゃなくて 5つだが、uniqueには3種 なので三和音
- 9. 9 ちょっと音楽の話を:コードの種類(全部理解しなくて良い) 音の組み合わせに全部名前がついているので、実際は非常に多くの組み合わせと なり種類がたくさんあります。本発表では主要なコードのみを扱います。 1 2 3 4 5 6 7 8 9 10 11 12 イタリア式表記 ド ド# レ レ# ミ ファ ファ# ソ ソ# ラ ラ# シ 英・米式表記 C C# D D# E F F# G G# A A# B 三和音 メジャー コード コード名 C C# D D# E F F# G G# A A# B 構成音 8 5 1 9 6 2 10 7 3 11 8 4 12 9 5 1 10 6 2 11 7 3 12 8 4 1 9 5 2 10 6 3 11 7 4 12 三和音 マイナー コード コード名 Cm C#m Dm D#m Em Fm F#m Gm G#m Am A#m Bm 構成音 8 4 1 9 5 2 10 6 3 11 7 4 12 8 5 1 9 6 2 10 7 3 11 8 4 12 9 5 1 10 6 2 11 7 3 12 1 • 音の数は12種類(これはこれで全部) • 和音はタイプはメジャー、マイナーの2種類(これは本当はたくさんあるが本発表では 主要な2種類を扱う) 5 6 3 10 12 8 9 11 7 2 4 よく見ると全体的に1つずれてるだけ 真ん中が1つ ずれてるだけ
- 10. 10 ちょっと音楽の話を:コードの種類 メジャーコード:明るい感じ マイナーコード:暗い感じ コードの種類を音で感じてみる E E B G# C#m Bm A A G#m G#m C#m C# B A F#m G#m C C# D D# E F F# G G# A A# B Cm C#m Dm D#m Em Fm F#m Gm G#m Am A#m Bm うまく組み合わせて繋げると 音楽的になります (これをコード進行という) 実際の曲での使われ方 (BiSH:オーケストラ) これだけ覚えて欲しい:音の数が12種類、和音のタイプが2種類、計24種類の主 要なコードをこの発表ではこの後も扱います。 音源の場所: https://matsuken92.github.io/wav_music_analysis/index.html wav1, wav2 wav1 wav2
- 12. 12 やりたいこと: ギターを弾いて作られた波形データをインプットに、それがどのコードかを識別するDeep Learningモデルを作りたい。 Guitarのコードを識別する:どうやって? 1. ギターを弾く 2. 波形データ化する 3. データセットにする 4. モデルを作って評価する 手順
- 14. 14 1. ギターを弾く ①ひたすらギターのコードを弾く 24種コード × ギター2本 x それぞれ数十回 ⇒ 計 1351 + 430 = 1751 個の波形データを取得 ② 波形データを整える 波形を無音部分でsplitしたり、音量の大小をノー マライズしたり。 録音
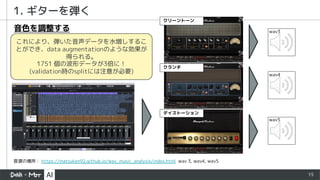
- 15. 15 1. ギターを弾く クリーントーン クランチ デイストーション 音色を調整する これにより、弾いた音声データを水増しするこ とができ、data augmentationのような効果が 得られる。 1751 個の波形データが3倍に! (validation時のsplitには注意が必要) 音源の場所: https://matsuken92.github.io/wav_music_analysis/index.html wav 3, wav4, wav5 wav3 wav4 wav5
- 16. 16 2. 波形データ化する オーディオミックスダウン で.wavファイルを書き出す。 .wavファイル ※ 長い音声データを書き出してpythonで細切れにする 処理を入れているがここでは説明割愛
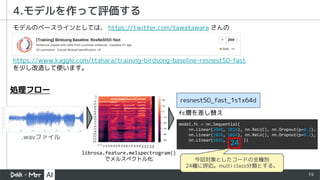
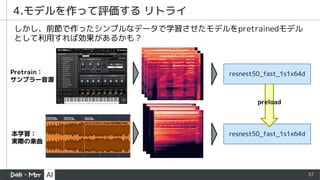
- 19. 19 4.モデルを作って評価する https://www.kaggle.com/ttahara/training-birdsong-baseline-resnest50-fast を少し改造して使います。 モデルのベースラインとしては、 https://twitter.com/tawatawara さんの .wavファイル librosa.feature.melspectrogram() でメルスペクトル化 resnest50_fast_1s1x64d 処理フロー model.fc = nn.Sequential( nn.Linear(2048, 1024), nn.ReLU(), nn.Dropout(p=0.2), nn.Linear(1024, 1024), nn.ReLU(), nn.Dropout(p=0.2), nn.Linear(1024, 24 )) 今回対象としたコードの全種別 24種に呼応。multi class分類とする。 fc層を差し替え
- 22. 22 やりたいこと: シンセサイザーで作られた波形データをインプットに、それがどのコードかを識別する Deep Learningモデルを作りたい。 サンプラー音源のコードを識別する:どうやって? 1. さまざまな音色で音声を作り波形データ化する 2. データセットにする 3. モデルを作って評価する 手順
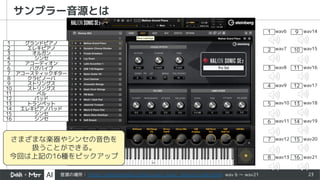
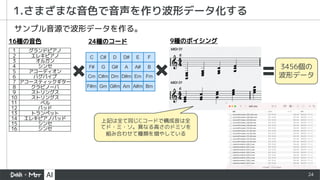
- 24. 24 1.さまざまな音色で音声を作り波形データ化する グランドピアノ エレキピアノ オルガン シンセ アコーディオン バグパイプ アコースティックギター クラビノーバ ストリングス ストリングス ベル パッド トランペット エレキピアノパッド シンセ シンセ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 16種の音色 9種のボイシング 上記は全て同じCコードで構成音は全 てド・ミ・ソ。異なる高さのドミソを 組み合わせて種類を増やしている C C# D D# E F F# G G# A A# B Cm C#m Dm D#m Em Fm F#m Gm G#m Am A#m Bm 24種のコード 3456個の 波形データ サンプル音源で波形データを作る。
- 26. 26 3.モデルを作って評価する(ギターの時と同じ) https://www.kaggle.com/ttahara/training-birdsong-baseline-resnest50-fast を少し改造して使います。 ギターの時同様モデルのベースラインとしては、 https://twitter.com/tawatawara さんの .wavファイル librosa.feature.melspectrogram() でメルスペクトル化 resnest50_fast_1s1x64d 処理フロー model.fc = nn.Sequential( nn.Linear(2048, 1024), nn.ReLU(), nn.Dropout(p=0.2), nn.Linear(1024, 1024), nn.ReLU(), nn.Dropout(p=0.2), nn.Linear(1024, 24 )) 今回対象としたコードの全種別 24種に呼応。multi class分類とする。 fc層を差し替え
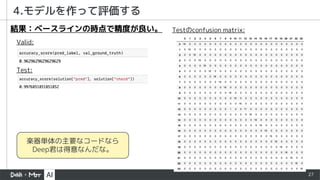
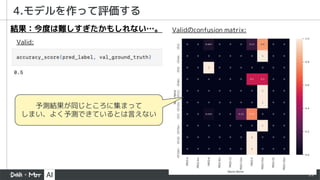
- 27. 27 4.モデルを作って評価する 結果:ベースラインの時点で精度が良い。 楽器単体の主要なコードなら Deep君は得意なんだな。 Valid: Test: Testのconfusion matrix:
- 29. 選曲 データを難しくして、実際の楽曲にチャレンジします。選曲は最近お気に入りの アイナ・ジ・エンドのオーケストラ THE FIRST TAKE version。 https://www.youtube.com/watch?v=URABwFBT8Ok ⇒ 歌とピアノのみなので、シンプルで実際の楽曲の中では取り組みやすそう アイナ・ジ・エンド - オーケストラ / THE FIRST TAKE
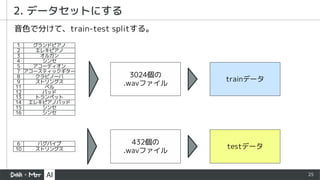
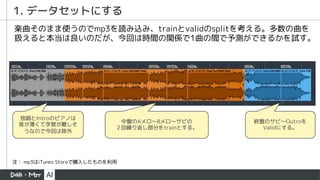
- 33. trainデータ 140files validデータ 76files 1. データセットにする train-valid splitを行い、216ファイルを得る。これで学習させる。
- 34. 34 2.モデルを作って評価する(前回までと同じ) https://www.kaggle.com/ttahara/training-birdsong-baseline-resnest50-fast を少し改造して使います。 ギターの時同様モデルのベースラインとしては、 https://twitter.com/tawatawara さんの .wavファイル librosa.feature.melspectrogram() でメルスペクトル化 resnest50_fast_1s1x64d 処理フロー model.fc = nn.Sequential( nn.Linear(2048, 1024), nn.ReLU(), nn.Dropout(p=0.2), nn.Linear(1024, 1024), nn.ReLU(), nn.Dropout(p=0.2), nn.Linear(1024, 24 )) 今回対象としたコードの全種別 24種に呼応。multi class分類とする。 fc層を差し替え
- 38. 38 結果:十分ではないが可能性を感じる。 Valid: Validのconfusion matrix(ratio): 4.モデルを作って評価する リトライ 対角線に結果が集まり始めている! Validのconfusion matrix(個数): train test
- 39. 39 まとめと今後の展開 ▪ 実際の楽曲のコードをDeep Learningで識別することの可能 性を感じた。 ▪ Pretraindモデルの入力データを増やすことと、楽曲データも 豊富に用意して再チャレンジしたい。 ▪ 四和音などコードの種類も増やすことも試したい。
- 40. 40 EOF