02Data updated.pdf
•
0 likes•36 views
The document discusses different types of data sets and various concepts related to data preprocessing. It describes common data types like records, relational data, and transaction data. It also defines key concepts in data preprocessing like data objects, attributes, handling missing/noisy data, data integration, reduction, transformation and discretization. The goal of these techniques is to clean, integrate and prepare raw data for analysis.
Report
Share

More Related Content
Similar to 02Data updated.pdf
Similar to 02Data updated.pdf (20)
More from saman Iftikhar
Recently uploaded
Recently uploaded (20)
02Data updated.pdf
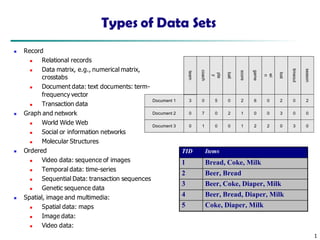
- 1. 1 Types of Data Sets Record Relational records Data matrix, e.g., numerical matrix, crosstabs Document data: text documents: term- frequency vector Transaction data Graph and network World Wide Web Social or information networks Molecular Structures Ordered Video data: sequence of images Temporal data: time-series Sequential Data: transaction sequences Genetic sequence data Spatial, image and multimedia: Spatial data: maps Image data: Video data: Document 1 season timeout lost wi n game score ball pla y coach team Document 2 Document 3 3 0 5 0 2 6 0 2 0 2 0 0 7 0 2 1 0 0 3 0 0 1 0 0 1 2 2 0 3 0 TID Items 1 Bread, Coke, Milk 2 Beer, Bread 3 Beer, Coke, Diaper, Milk 4 Beer, Bread, Diaper, Milk 5 Coke, Diaper, Milk
- 2. 2 Data Objects Data sets are made up of data objects. A data object represents an entity. Examples: sales database: customers, store items, sales medical database: patients, treatments university database: students, professors, courses Also called samples , examples, instances, data points, objects, tuples. Data objects are described by attributes. Database rows -> data objects; columns ->attributes.
- 3. 3 Attributes Attribute (or dimensions, features, variables): a data field, representing a characteristic or feature of a data object. E.g., customer _ID, name, address Types: Nominal Binary Numeric: quantitative Interval-scaled Ratio-scaled
- 4. 4 Attribute Types Nominal: categories, states, or “names of things” Hair_color = {auburn, black, blond, brown, grey, red, white} marital status, occupation, ID numbers, zip codes Binary Nominal attribute with only 2 states (0 and 1) Symmetric binary: both outcomes equally important e.g., gender Asymmetric binary: outcomes not equally important. e.g., medical test (positive vs. negative) Convention: assign 1 to most important outcome (e.g., HIV positive) Ordinal Values have a meaningful order (ranking) but magnitude between successive values is not known. Size = {small, medium, large}, grades, army rankings
- 5. 5 Numeric Attribute Types Quantity (integer or real-valued) Interval Measured on a scale of equal-sized units Values have order E.g., temperature in C˚or F˚, calendar dates No true zero-point Ratio Inherent zero-point We can speak of values as being an order of magnitude larger than the unit of measurement (10 K˚ is twice as high as 5 K˚). e.g., temperature in Kelvin, length, counts, monetary quantities
- 6. 6 Discrete vs. Continuous Attributes Discrete Attribute Has only a finite or countably infinite set of values E.g., zip codes, profession, or the set of words in a collection of documents Sometimes, represented as integer variables Note: Binary attributes are a special case of discrete attributes Continuous Attribute Has real numbers as attribute values E.g., temperature, height, or weight Practically, real values can only be measured and represented using a finite number of digits Continuous attributes are typically represented as floating-point variables
- 7. 7 Data Quality: Why Preprocess the Data? Measures for data quality: A multidimensional view Accuracy: correct or wrong, accurate or not Completeness: not recorded, unavailable, … Consistency: some modified but some not, dangling, … Timeliness: timely update? Believability: how trustable the data are correct? Interpretability: how easily the data can be understood?
- 8. 8 Major Tasks in Data Preprocessing Data cleaning Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies Data integration Integration of multiple databases, data cubes, or files Data reduction (Reduced representation of the data set that is much smaller in valumn) Dimensionality reduction Numerosity reduction Data compression Data transformation and data discretization Normalization (smaller rang i.e.[0.0,1.0] Concept hierarchy generation :- raw data values are replaced by ranges
- 9. 9 Data Cleaning Data in the Real World Is Dirty: Lots of potentially incorrect data, e.g., instrument faulty, human or computer error, transmission error incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., Occupation=“ ” (missing data) noisy: containing noise, errors, or outliers e.g., Salary=“−10” (an error) inconsistent: containing discrepancies in codes or names, e.g., Age=“42”, Birthday=“03/07/2010” Was rating “1, 2, 3”, now rating “A, B, C” discrepancy between duplicate records Intentional (e.g., disguised missing data) Jan. 1 as everyone’s birthday?
- 10. 10 Incomplete (Missing) Data Data is not always available E.g., many tuples have no recorded value for several attributes, such as customer income in sales data Missing data may be due to equipment malfunction inconsistent with other recorded data and thus deleted data not entered due to misunderstanding certain data may not be considered important at the time of entry not register history or changes of the data Missing data may need to be inferred
- 11. 11 How to Handle Missing Data? Ignore the tuple: usually done when class label is missing (when doing classification)—not effective when the % of missing values per attribute varies considerably Fill in the missing value manually: tedious + infeasible? Fill in it automatically with a global constant : e.g., “unknown”, a new class?! the attribute mean the attribute mean for all samples belonging to the same class: smarter the most probable value: inference-based such as Bayesian formula or decision tree
- 12. 12 Noisy Data Noise: random error or variance in a measured variable Incorrect attribute values may be due to faulty data collection instruments data entry problems data transmission problems technology limitation inconsistency in naming convention Other data problems which require data cleaning duplicate records incomplete data inconsistent data
- 13. 13 How to Handle Noisy Data? Binning first sort data and partition into (equal-frequency) bins then one can smooth by bin means, smooth by bin median, smooth by bin boundaries, etc.
- 14. How to Handle Noisy Data? Regression smooth by fitting the data into regression functions Clustering detect and remove outliers Combined computer and human inspection detect suspicious values and check by human (e.g., deal with possible outliers) 14
- 15. 15 15 Data Integration Data integration: Combines data from multiple sources into a coherent store Schema integration: e.g., A.cust-id. B.cust-# Integrate metadata from different sources Entity identification problem: Identify real world entities from multiple data sources, e.g., Bill Clinton = William Clinton Detecting and resolving data value conflicts For the same real world entity, attribute values from different sources are different Possible reasons: different representations, different scales, e.g., metric vs. British units
- 16. 16 16 Handling Redundancy in Data Integration Redundant data occur often when integration of multiple databases Object identification: The same attribute or object may have different names in different databases Derivable data: One attribute may be a “derived” attribute in another table, e.g., annual revenue Redundant attributes may be able to be detected by correlation analysis and covariance analysis Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality
- 17. 17 Correlation Analysis (Nominal Data) Χ2 (chi-square) test The larger the Χ2 value, the more likely the variables are related The cells that contribute the most to the Χ2 value are those whose actual count is very different from the expected count Correlation does not imply causality # of hospitals and # of car-theft in a city are correlated Both are causally linked to the third variable: population Expected Expected Observed 2 2 ) (
- 18. 18 Data Transformation A function that maps the entire set of values of a given attribute to a new set of replacement values s.t. each old value can be identified with one of the new values Methods Smoothing: Remove noise from data Attribute/feature construction New attributes constructed from the given ones Aggregation: Summarization, data cube construction Normalization: Scaled to fall within a smaller, specified range min-max normalization z-score normalization normalization by decimal scaling Discretization: Concept hierarchy climbing
- 19. 19 Data Preprocessing Data Preprocessing: An Overview Data Quality Major Tasks in Data Preprocessing Data Cleaning Data Integration Data Reduction Data Transformation and Data Discretization