통계 기초 용어1
•Download as PPTX, PDF•
14 likes•9,915 views

초보자의 입장에서 정리한 통계 관련 기초 용어입니다. 혹시 잘못된 것이 있으면 알려주십시오.
Report
Share










































































통계 기초 용어1
- 4. 통계학은 데이터를 생산하고 이해하는 논리와 방법들을 제공하는 학문
- 7. 데이터 질적 데이터 양적 데이터 비례척도 척도 명목척도 순서척도 간격척도 <데이터의 분류> 비정형 데이터 정형 데이터 연속 데이터 이산 데이터 1차 데이터 2차 데이터 수집 방법 속성 대상
- 8. 데이터 편차값 표준화 표준편차 분산 중앙값 최빈값 정규분포 값 대표값 평균값 기타 산술평 균 기하평 균 조화평 균 편차 편차제곱합 변수의 변환 산포도 범위 사분위수 상자수염 그림 구성 최대값최소값 요소변수(변량) 표두 표측 크로스집계표 공분산표준편차 상관계수 <데이터> 가중평균, 절단평균, 사분평균… 분포 도수 일변량 다변량
- 10. 이름 점수 홍길동 90 이순신 80 박지성 90 손흥민 100 변수명 변량(변수) 요소요소명
- 13. No 점수 1 90 2 80 3 90 4 100 5 75 No 점수 6 35 7 80 8 55 9 70 10 60 No 점수 11 95 12 20 13 65 14 50 15 85 No 점수 16 70 17 50 18 60 19 30 20 15 계급(점수) 계급값 도수 (명) 0~20미만 10 1 20~40 30 3 40~60 50 3 60~80 70 6 80~100 90 7 합계 20 <자료 : 시험성적> <도수분포표>
- 14. 계급 계급값 도수 상대도수 150~160 155 1 0.05 160~170 165 8 0.40 170~180 175 10 0.50 180~190 185 1 0.05 190~200 195 0 0.00 계 20 1 0.00 0.10 0.20 0.30 0.40 0.50 0.60 155 165 175 185 195 상대도수 히스토그램
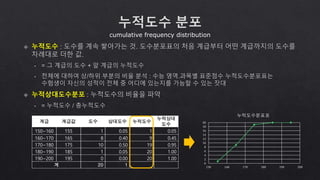
- 15. 계급 계급값 도수 상대도수 누적도수 누적상대 도수 150~160 155 1 0.05 1 0.05 160~170 165 8 0.40 9 0.45 170~180 175 10 0.50 19 0.95 180~190 185 1 0.05 20 1.00 190~200 195 0 0.00 20 1.00 계 20 1 cumulative frequency distribution 0 2 4 6 8 10 12 14 16 18 20 150 160 170 180 190 200 누적도수분포표
- 16. 평균값(mean, average) 중앙값(median) 최빈값(mode) 의미 • 데이터의 크기 합을 데이터 개수로 나눈 값 • 변량의 값을 크기 순으로 늘어놓았을 때 꼭 중앙에 오는 값 • 도수(빈도)가 가장 많은 값 특징 • 일부 이상치에 크게 영향 받음 • 수학적인 연산에 의해 계산되므로 수학적 조작 가능 • 서열자료의 경우 중앙값 사용 • 이상치 영향 없음 • 명목자료에서는 최빈값이 대표값 • 이상치 영향 없음 예 • 연간 평균 강우량 • 기말고사 평균점수 • 학교 석차 100명 중 50등 • 유행하는 가방 • 인기투표
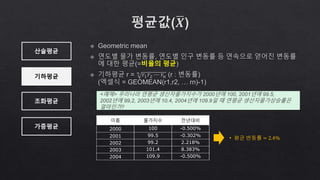
- 18. 산술평균 기하평균 조화평균 가중평균 이름 물가지수 전년대비 2000 100 -0.500% 2001 99.5 -0.302% 2002 99.2 2.218% 2003 101.4 8.383% 2004 109.9 -0.500% • 평균 변동률 = 2.4%
- 19. 산술평균 기하평균 조화평균 가중평균 H = 2𝐴 𝐴 4 + 𝐴 6 = 2 1 4 + 1 6 = 4.8(km/h) 갈 때 걸리는 시간 = 𝐴 4 , 올 때 걸리는 시간 = 𝐴 6 왕복(2A)하는데 걸린 시간 = 𝐴 4 + 𝐴 6
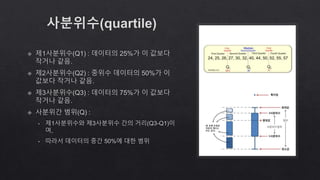
- 20. 산술평균 기하평균 조화평균 가중평균 평균 = (1000 𝑥 50)+(2000𝑥100) 50+100 = 1,666.7 = 16,667,000원
- 22. 이름 득점(x) 편차(x-x) 편차제곱(x-x)2 가 9 2 4 나 4 -3 9 다 10 3 9 라 5 -2 4 마 7 0 0 분산 = 편차제곱합(26) / 데이터 수(5) = 5.2 합계 26이 편차제곱 합
- 24. No 소득 가 100 나 110 다 150 라 200 마 160 <월평균 소득> No 소득 바 190 사 230 아 210 자 180 차 300 • 평균 = 183 • 분산 = 3423.3 • 표준편차 = 58.5 183 183 − 58.5 183 + 58.5
- 25. No 체중 가 51 나 49 다 50 라 57 마 43 <체중자료> • 최대값 = 57 • 최소값 = 43 • R = 57 – 43 = 14 “이 집단의 체중은 14kg안에 다 모여 있다.”
- 27. 표준화 No x 가 61 나 59 다 60 라 67 마 53 평균값 60 표준편차 4.47 No z 가 0.22 나 -0.22 다 0.00 라 1.57 마 -1.57 평균값 0 표준편차 1.00 표준화 “평균이 60이고 표준편차가 4.47인 정규분포를 표준화”
- 28. 13.6% 13.6%2.1% 2.1 % 0.1 % 0.1 % 평균값 기대값 ± 표본오차 기대값 ±2 ×표본오차 기대값 ± 3 × 표본오차
- 30. 상황 그래프 비율을 나타내는 그래프 띠 그래프, 원 그래프, 복합 그래프 관계를 나타내는 그래프 산포토, 레이더 차트 분산을 나타내는 그래프 도수분포표, 히스토그램, 상사수염그림, 줄기잎 그림, 꺾은선 그래프 누적도수분포를 나타내는 그래프 꺾은선 그래프
- 31. <출처 : ‘R분석과 프로그래밍' (http://rfriend.tistory.com)>
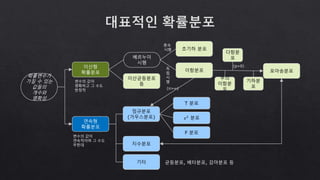
- 33. 확률 사건 표본공간 확률변수 리스크 사람(의 경험, 지식, 태도, 성격 등)에 따라 다르게 일어날 확률 경우의 수 확률분포 성 공 실 패 독 립 사 건 종 속 사 건 배 타 적 사 건 주관적 확률 객관적 확률 논리적 확률 경험적 확률 대수의 법칙 상대도수 어떤 상황이 발생할 가능성 기대값 분산 유형 유형 조사 전수조사 표본조사 모집단 표본 시행 곱 의 법 칙 합 의 법 칙 순열 조합 모수 통계량 표본추출 표본오차 <확률>
- 34. 가설 검정 수 락 역 기 각 역 귀무가설( 𝐻0 ) 대립가설 (𝐻1) 표본 검정동계량 (표본통계량) 유 의 수 준 확률밀도 함수 확률변수 연속 형 확률 변수 이산 형 확률 변수틀릴 가능성 판단 근거 확률분포 이산형 확률분포 이산균등분 포 등 베르누이 시행 초기하 분포 이항분포 포아송분포 종속 시행 독립 시행 다항 분포 기하 분포 정규분포 (가우스분포) 균등분포 지수분포 평균 표준편차 표준점수 표준 정규분포 T = 50+10( 𝑋− 𝑋 𝑆 ) 편차 평균제곱 합 제곱합 연속형 확률분포 (p>0) 채택 <가설검정과 확률분포>
- 36. 모집단 (모수) 표본 (통계량) 평균 𝜇 𝑋 표준편차 𝜎 S 분산 𝜎2 𝑆2 상관계수 𝜌 회귀계수 𝛽 𝑏
- 41. 확률 확률 P 통계학 평균값 𝜇, 𝑋 분산 𝜎2 , 𝑆2 표본오차 𝜎, S 확률변수 𝑋 확률통계
- 42. 이산형(discrete) 연속형(continuous) • 비연속 수치 • 셀 수 있는 경우 • 연속 수치 • 확률변수가 갖는 값을 셀 수 없는 경우 = 무한 히 쪼개질 수 있음 • 주사위 던지기 등 • 체중, 키 등
- 44. 동전 앞면 횟 수 0 1 2 3 확률 1/8 3/8 3/8 1/8 <동전을 3회 던졌을 때 앞면이 나올 확률> X 확률 𝑥1 𝑝1 𝑥2 𝑝2 𝑥3 𝑝3 𝑥4 𝑝4 … … 계 1
- 45. 이산형 확률분포 이산균등분포 등 베르누이 시행 초기하 분포 이항분포 포아송분포 종속 시행 독 립 시 행 다항분 포 기하분 포 정규분포 (가우스분포) 기타 지수분포 연속형 확률분포 (p>0) 변수의 값이 연속적이며 그 수도 무한대 변수의 값이 명확하고 그 수도 한정적 확률변수가 가질 수 있는 값들의 개수와 명확성 T 분포 𝑥2 분포 F 분포 부의 이항분 포 균등분포, 베타분포, 감마분포 등 (n>∞)
- 46. “통계학” 68쪽 내용 추가
- 47. X 1 2 3 4 5 6 계 확률 p 1 6 1 6 1 6 1 6 1 6 1 6 1 <확률변수 X의 확률분포> <변량 x의 도수분포> X 1 2 3 4 5 6 계 도수 f 𝑁 6 𝑁 6 𝑁 6 𝑁 6 𝑁 6 𝑁 6 N N회 반복 1 6 1 6 1 6 1 6 1 𝑁 𝑁 6 𝑁 6 𝑁 6 𝑁 6
- 48. 이 면적 = 확률 확률변수 X가 두 수 a와 b 사이에 놓일 확률 = f( 𝑥)의 아래 a와 b 사이의 면적
- 51. X 1 0 5𝐶0 1 6 0 1 − 1 6 5 1 5𝐶1 1 6 1 1 − 1 6 4 2 5𝐶2 1 6 2 1 − 1 6 3 3 5𝐶3 1 6 3 1 − 1 6 2 4 5𝐶4 1 6 4 1 − 1 6 5 5𝐶5 1 6 5 예) 주사위를 5번 던져서 ‘1’이 X회 나올 X의 확률분포
- 54. 신뢰구간 양측검정 단측검정 (또는 상위검정) 68.3%의 신뢰구간 기대값( 𝜇) ± 표본 오차 95%의 신뢰구간 기대값( 𝜇) ± 1.96 x 표본오차 기대값( 𝜇) + 1.64 x 표본오차 99%의 신뢰구간 기대값( 𝜇) ± 2.58 x표본오차 기대값( 𝜇) + 2.33 x 표본오차
- 55. 표본의 크기가 클 때 정규분포 형태에 가까워짐 그림통계학 73p 주사위 던지기 추가
- 57. 1. 기획 모집단/모수, 표본크기, 통계량 2. 조사(실험) 3. 자료 처리 4. 자료 분석 5. 집단(현상) 설명, 정책집행 평가 6. 예측, 정책 도출 표본, 조사방법 개체, 변수, 자료, 이상치, MDIS 활용… 요약, 그래프, 관계 표본점수, 확률분포 모형, 표집분포, 표본오차, 신뢰구간, 가설검정
- 58. Paired T-test 연속형 종속변 수 독립변수 의 갯수 독립변수 종속변수독립변수독립변수 범주형 연속형 연속형 or 변수 2개 이상1개 2개 이상 범주형 범주형 연속 형 수준 짝 2 3이상 Covariat e 혼합 Yes N o 이분 명목,서열 (2수준) 명목 (3수준 이상) Yes No 2-sample T-test 단순회귀분 석 One-way ANOVA ANOVA (GLM) 다중회귀분 석 이분형 Logistic회 귀 카이제곱분 석 다중명목 Logistic회 귀 순서형 Logistic회 귀 정규성 정규성 정규성 Yes No Yes No Yes No GLM (Covariate) 회귀분석 (dummy) Wilcoxon Mann- Whitney Kruskal- Wallis 서열 (3수준 이상) 범주형
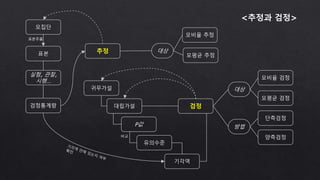
- 59. 추정 대립가설 검정 표본 대상 모비율 추정 모평균 추정 P값 모집단 방법 단측검정 양측검정 귀무가설 검정통계량 유의수준 비교 <추정과 검정> 실험, 관찰, 시행… 대상 모비율 검정 모평균 검정 표본추출 기각역
- 66. 귀무가설 채택 귀무가설 탈락
- 67. 표본오차 = 오차한계 = 임계값 x 𝑠 𝑛 (또는 𝛿 𝑛 ) 표본크기 = 신뢰계수 2 x 0.52 / 허용오차 2
- 68. 검정결과 𝐻0의 실제 상태 𝐻0 = 참 𝐻0 = 거짓 𝐻0 채택 ○ 제2종 오류( 𝛽) 𝐻0 기각 제1종 오류( 𝛼) ○ 𝛽𝛼 𝐻0 𝐻1
- 69. 추정 점 구간 표본 불편성 최소 분산 효율성 추정량모집단 신뢰구간 상충관계 추정구간의 크기 추정정보의 효과 모수 허용오차 90% 95% 99% 표본분포 평균 분산 확률변수 중심극한 정리 정규분포 모집단의 분포모양과는 상관없이 일정한 모양
- 71. 예) 4명의 학생들에게 자신이 좋아하는 학생 1명을 선택하라고 할 때, 자유롭게 선택할 수 있는 대상은 나를 제외한 3명 df = 4 - 1 = 3 자유도 = n -1
- 72. 번호 그룹 A B C 1 49 56 51 2 47 54 55 3 46 61 57 4 50 57 53 그룹 평균 48 57 54 번호 그룹 A B C 1 1 -1 -3 2 -1 -3 1 3 -2 4 3 4 2 0 -1 합 0 0 0 제약조건 k = 3 (3개 그룹) df = 12 – 3 = 9 X − 𝑋 2 = 12 + (−1)2 + (−2)2 + 22 + (−1)2 + (−3)2 + 42 + 02 + (−3)2 + 12 32 + (−1)2 = 56 불편분산 𝒔 𝟐 = 56/9 조건1 <표본> <그룹내 편차> 조건2 조건3
- 75. 귀무가설을 세운다1 ‘내용량은 500ml이다’ • 모평균 𝜇 = 500 대립가설을 세운다2 ‘내용량은 500ml가 아니다’ • 모평균 𝜇 ≠ 500 유의수준을 정한다3 • 유의수준 = 0.05 (5%) 검정통계랑이 따르는 분포를 확인한다 4 모집단분포가 정규분포이므로 검정통계량 T는 자유도 8의 t분포에 따른다.(앞의 t분포 참조) • T = 561−500 1.80 9 = 1.67 기각역을 설정한다5 대립가설이 모평균 𝜇 ≠ 500이므로 양측검정시 기각역 ±5%부분은 ‘기대값( 𝜇) ± 1.94 x 표본오차’이므로 • 기각역 = -2.31 > T, 2.31 < T 검정통계량의 값이 기각역에 있는지 확인한다 6 관측한 T값은 1.67은 기각역에 들어있지 않다. • 관측값 T = 1.67 • 귀무가설은 기각할 수 없다. • 즉, ‘내용량은 500ml이다’고 볼 수 있다.
- 76. 귀무가설을 세운다1 ‘신제품을 먹어본 사람의 비율은 21%다’ • 모비율 R = 0.21 대립가설을 세운다2 ‘신제품을 먹어본 사람의 비율은 21%보다 늘었다’ • 모비율 R > 0.21 유의수준을 정한다3 • 유의수준 = 0.05 (5%) 검정통계랑이 따르는 분포를 확인한다 4 검정통계량인 ‘먹어보았다‘는 인원수 X는 다음 정규분포를 따른다. • 기대값 nR = 100 x 0.21 = 21 • 분산 nR(1-R) = 100 x 0.21(1-0.21) = 16.59 • 표본오차 = 16.59 = 4.07 기각역을 설정한다5 대립가설이 R>0.21이므로 단측검정시 기각역 5%부분은 ‘기대값( 𝜇) + 1.64 x 표본오차’이므로 • 기각역 = 27.7 < X 검정통계량의 값이 기각역에 있는지 확인한다 6 관측값 X는 29이므로 기각역에 들어있지 않다. • 관측값 X = 29 • 귀무가설은 기각된다. • 즉, ‘제품을 먹어본 사람의 비율은 21%보다 늘었다’고 볼 수 있다.
- 78. 데이터 값 = 전체 평균 + 그룹간 편차 + 그룹 내 편차
- 79. 구획 비료A 비료B 비료C 1 49 56 51 2 47 54 55 3 46 61 57 4 50 57 53 그룹평균 48 57 54 구획 A B C 1 -5 4 1 2 -5 4 1 3 -5 4 1 4 -5 4 1 <그룹간 편차 = 그룹평균 - 전체평균> 구획 A B C 1 1 -1 -3 2 -1 -3 1 3 -2 4 3 4 2 0 -1 <그룹 내 편차 = 개별 데이터 값 - 그룹평균>
Editor's Notes
- 확률변수 : 일정한 확률을 가지고 발생하는 사건에 수치를 부여한 것
- 확률변수 : 일정한 확률을 가지고 발생하는 사건에 수치를 부여한 것
- 확률변수 : 일정한 확률을 가지고 발생하는 사건에 수치를 부여한 것
- 확률변수 : 일정한 확률을 가지고 발생하는 사건에 수치를 부여한 것
- 확률변수 : 일정한 확률을 가지고 발생하는 사건에 수치를 부여한 것
- 확률변수 X의 사례 : 동전의 앞면이 나오는 경우, A의 키 등
- 상대도수(relative frequency) a/n = 우리가 관심을 갖는 사건의 확률 어떤 사건이 나타날 확률은 실험을 무한에 가깝게 계속적으로 반복했을 때, 전체 시행횟수에서 그 사건이 나타나는 빈도수를 상대적으로 나타낸 것 (=대수의 법칙) 대수의 법칙 표본크기가 커질수록 표본평균의 분산은 작아짐. 즉, 확률밀도가 모평균으로 높아짐 모집단의 특성을 잘 알려면 가능한 큰 표본 추출 동전의 앞뒤면이 각각 나올 이론적인 확률 = 1:1 그러나 몇 번 던져서는 1:1이 안나옴 하지만 많이 던지면 던질수록 1:1로 수렴
- 확률변수 : 일정한 확률을 가지고 발생하는 사건에 수치를 부여한 것 신뢰구간 : P(점 추정치-허용오차=<모수=>점 추정치+허용오차) = 1-𝛼
- 점 추정(point estimation) 하나의 값으로 모수를 추정하는 과정 미지의 모수 𝜃를 추정하기 위한 추정량 T함수 구간 추정(interval estimation) 모수를 추정하기 위해 사용하는 값의 범위 또는 구간 신뢰구간(L, U) : L은 하한, U는 상한
- 확률변수 : 일정한 확률을 가지고 발생하는 사건에 수치를 부여한 것 신뢰구간 : P(점 추정치-허용오차=<모수=>점 추정치+허용오차) = 1-𝛼