

































1. beyond mission critical virtualizing big data and hadoop
- 1. © 2009 VMware Inc. All rights reserved Beyond Mission Critical: Virtualizing Big-Data and Hadoop Michael West Global Architect Big Data and Storage Field Engineering, VMware
- 2. 2 Applications And Storage Are Becoming Increasingly Diverse Virtual Storage Arrays vSphere SAN/NAS Object / BLOB Traditional Applications • Traditional enterprise storage • HW-based resiliency, QoS Next Gen Cloud Apps • Scale out, flash, DAS • Application specific storage All SSD Array Server-side Flash
- 3. 3 The complexity enterprise IT and developers face today An Idea for a cool app Spec a server config Justify server costs Procurement process Wait for HW to arrive Wait for IT ops to Image the server Install a Database LOB Architecture approval Central IT Architectural approval Justify more server for scale testing Wait for more HW Configure ACLs and LBs New infrastructures New Languages and Frameworks New Devices and Domains New Data types and requirements
- 4. 4 Big Data: Not Just for the Web Giants – Now the Intelligent Enterprise
- 5. 5 Real-time analysis allows instant understanding of market dynamics. Retailers can have intimate understanding of their customers needs and use direct targeted marketing. Market Segment Analysis Personalized Customer Targeting`
- 6. 6 The Emerging Pattern of Big Data Systems: Retail Example Real-Time Streams Exa-scale Data Store Parallel Data Processing Real-Time Processing Machine Learning Data Science Cloud Infrastructure Analytics
- 7. 7 Storage: Plan for Peta-scale Data Storage and Processing 0.01 0.1 1 10 100 1000 2000 2003 2006 2009 2012 2015 Online Apps Analytics PB of Data Analytics Rapidly Outgrows Traditional Data Size by 100x
- 8. 8 Unprecedented Scale “Data transparency, amplified by Social Networks generates data at a scale never seen before” - The Human Face of Big Data We are creating an Exabyte of data every minute in 2013 Yottabyte by 2030
- 9. 9 A single GE Jet Engine produces 10 Terabytes of data in one hour – 90 Petabytes per year. Enabling early detection of faults, common mode failures, product engineering feedback. Post Mortem Proactively Maintained Connected Product
- 10. 10 Cloud Infrastructure Supports Mixed Big Data Workloads Machine Learning HadoopReal-Time Analytics Cloud Infrastructure Machine Learning Hadoop Real-Time Analytics Management Network/Security Storage/Availability Compute
- 11. 11 Cloud Infrastructure Supports Multiple Tenants Cloud Infrastructure Management Network/Security Storage/Availability Compute Web User Analytics Financial Analysis Historical Customer Behavior
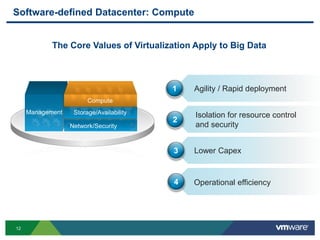
- 12. 12 Software-defined Datacenter: Compute Agility / Rapid deployment Lower Capex Isolation for resource control and security 1 2 3 Operational efficiency4 Management The Core Values of Virtualization Apply to Big Data Network/Security Storage/Availability Compute
- 13. 13 Virtualizing Hadoop Shrink and expand cluster on demand Independent scaling of Compute and data Strong multi-tenancy Elasticity & Multi-tenancy High availability for entire Hadoop stack One click to setup Battle-tested High Availability Rapid deployment One stop command center Easy to configure/reconfigure Operational Simplicity
- 14. 14 Serengeti Virtual Hadoop Manager (VHM) Hadoop Virtualization Extensions (HVE) Big Data Extensions: Core Components Core is Open Source Tool to simplify virtualized Hadoop deployment & operations Serengeti Virtualization changes for core Hadoop Contributed back to Apache Hadoop Advanced resource management on vSphere
- 15. 15 Strong Isolation between Workloads is Key Hungry Workload 1 Reckless Workload 2 Nosy Workload 3 Cloud Infrastructure
- 16. 16 Hadoop batch analysis Big Data Family of Frameworks File System/Data Store Host Host Host Host Host Host HBase real-time queries NoSQL Cassandra, Mongo, etc Big SQL Impala, Pivotal HawQ Compute layer Virtualization Host Other Spark, Shark, Solr, Platfora, Etc,…
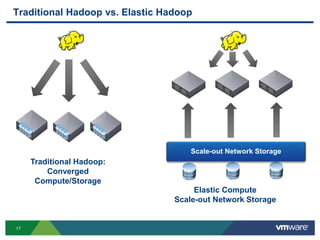
- 17. 17 Traditional Hadoop vs. Elastic Hadoop Scale-out Network Storage Traditional Hadoop: Converged Compute/Storage Elastic Compute Scale-out Network Storage
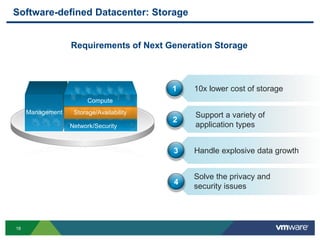
- 18. 18 Management Software-defined Datacenter: Storage Requirements of Next Generation Storage Network/Security Storage/Availability Compute 10x lower cost of storage Handle explosive data growth Support a variety of application types 1 2 3 Solve the privacy and security issues 4
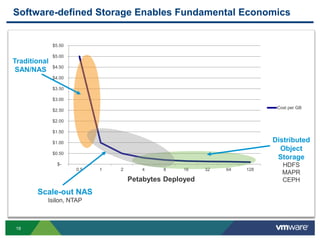
- 19. 19 Software-defined Storage Enables Fundamental Economics $- $0.50 $1.00 $1.50 $2.00 $2.50 $3.00 $3.50 $4.00 $4.50 $5.00 $5.50 0.5 1 2 4 8 16 32 64 128 Cost per GB Petabytes Deployed Traditional SAN/NAS Distributed Object Storage HDFS MAPR CEPH Scale-out NAS Isilon, NTAP
- 20. 20 HDFS Model ESX ESX ESX J T HDFS or MAPR VM HDFS or MAPR VM HDFS or MAPR VM Local Disks SAN/NAS Non-Hadoop VMs Hadoop Compute VMs JT: JobTracker TT: TaskTracker NN: NameNode VHM: Virtual Hadoop Manager N N T T T T T T VirtualCenter Management Server DRS DRS DRSDRS DRS VHM Hadoop HDFS VMs T T T T T T J T
- 21. 21 Virtual Hadoop Manager State, stats (Slots used, Pending work) Commands (Decommission, Recommission) Stats and VM configuration Serengeti Job Tracker vCenter DB Manual/Auto Power on/off Virtual Hadoop Manager (VHM) Job Tracker Task Tracker Task Tracker Task Tracker vCenter Server Serengeti Configuration VC state and stats Hadoop state and stats VC actions Hadoop actions Algorithms Cluster Configuration
- 22. 22 Big-Data using Local Disks Host Host Host Host Host Host Host Top of Rack Switch Servers with Local Disks 16-24 core server 12-24 SATA 2-4TB Disks 10 GbE adapter iSCSI/NFS for Shared Storage for vMotion etc,… High Performance 10GBE Switch per Rack
- 23. 23 Standard Deployment Configuration for D/C Separation Virtualization Host OS Image – VMDK Hadoop Virtual Node 1 Task- tracker Shared storage SAN/NAS Local disks OS Image – VMDK VMDK VMDK VMDK VMDK VMDK VMDK VMDK Hadoop Virtual Node 2 Datanode Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4Ext4 VMDK VMDK VMDK VMDK VMDK VMDK VMDK VMDKVMDK … …
- 24. 24 Big Data Storage Scale-out Network Storage Elastic Compute Scale-out Network Storage • Hadoop Protocol • Snapshots • Posix Apps • Full NFS Access • Replication • Erasure Coding
- 25. 25 Big Data with Scale-out-NAS Big-Data using Scale-out NAS Host Host Host Host Host Host Top of Rack Switch Scale-out NAS Host Host Host Host Host Host Top of Rack Switch Scale-out NAS Temp Data Shared Data Isilon Scale-out NAS Local Disk or SSD In each Host For Transient Data
- 26. 26 Hadoop Virtual Node 2 NN NN NN NN NN NN datanode Isilon Storage Configuration for Data/Compute Separation With Isilon Virtualization Host VMDKOS Image – VMDK Shared storage SAN/NAS OS Image – VMDK VMDK VMDK Hadoop Virtual Node 1 Ext4 Job- tracker Ext4 Temp OS Image – VMDK Ext4 Task- tracker Ext4 Hadoop Virtual Node 3 Ext4 Task- tracker Ext4
- 27. 27 Management Software-defined Datacenter: Network and Security Automate secure network provisioning Network & Security Requirements for Big Data Network/Security Storage/Availability Compute 3 New high bandwidth network designs 1 Leverage Software-defined network security 2
- 28. 28 Customer Success: Hadoop as a Service at FedEx Scale-out Isilon Cluster - Shared Data - NAS + Hadoop Elastic vSphere Cluster - Mixed Workloads - vSphere - Existing Rack Mount Servers
- 29. 29 Agile Big Data at FedEx • Trusted Isolation • Well known auditable platform Security • Deploy in minutes • Optimize for shift in workload characteristics Agility • Create true multi- tenancy • Mixed workloads Elasticity
- 30. 30 Breakthrough Use Cases Web Log Analysis Initial exploration was around detection of mobile devices accessing the website. Analysis of 570 billion web server log entries took approximately 9 minutes to complete on a small cluster. ZIP code Analysis Analysis of data to determine which ZIP codes are the highest source or destination for shipments. Shipment Analysis Analysis of shipment information to determine patterns that may delay a package.
- 31. 31 Agility: Automation of Hadoop Cluster Management Deploy Resize Elastic scaling Customize Incorporate best practices Manage Tune configuration Run Execute jobs Access HDFS
- 32. 32 Monitoring Agility: Ease of Management Due to Consolidation Cluster setup and provisioning Monitoring HW procurement and sizing Cluster setup and provisioning HW procurement and sizing
- 33. 33 Elasticity: Mixed Workloads on a Shared Platform Production Test Experimentation Dept A: recommendation engine Dept B: ad targeting Production Test Experimentation Log files Social data Transaction data Historical cust behavior
- 34. 34 Customer Success: Identified ROI in 2 Months Company Profile: Recruiting through Social Media Search • Big Data Shop: Acquire and classify data, then present to customers Hadoop Virtualization Stages: • Stage 1: Used AWS EMR to quickly spin up clusters and shutdown to save cost • Stage 2: Need to run Hadoop jobs 24/7. EMR too expensive and spikey performance based on VM and backing storage they are assigned. • Stage 3: Cut costs with On Premise Virtual Hadoop with BDE • 1 hour to read the doc and 30 node cluster available in a few minutes • Stage 4: Mix Physical and Virtual: • Physical servers with Local spinning disks for Compute and HDFS • VMs with HA for support nodes (Zookeeper, Namenode, Jobtracker, Journal, Clients) • Stage 5: Compute Nodes in VMs for CPU intensive workloads • Summary: 192 cores, 1 TB RAM, 96 Spindles, 288 TB storage
- 35. 35 Summary
- 36. 36 Customers Winning from Consolidated Big Data Platforms “Dedicated hardware makes no sense” “Software-defined Datacenter enables rapid deployment multiple tenants and labs” “Our mixed workloads include Hadoop, Database, ETL and App-servers” “Any performance penalties are minor”Management Network/Security Storage/Availability Compute
- 37. 37 Cloud Infrastructure is Ready for Big Data – Are you? Cloud Infrastructure
- 38. 38 Q&A
Editor's Notes
- Figure shows a bunch of ESX hosts with local disks or SAN/NAS attached to them. We don’t need to have both local-disks and SAN/NAS. These hosts are managed by a VC with one or more DRS clusters We split data and compute into different VMs – note that we have one data vm per host to act as a conduit for getting data from the underlying datastore This along with NameNode constitutes the data layer of Hadoop We have one compute cluster shown in orange with JobTracker and a bunch of task-trackers. Similarly we have another one shown in green. The compute clusters are put in different DRS resource pools and we can set limits, reservations, and shares/relative priorities for each cluster. To manage these different clusters and act as a glue between DRS and Hadoop scheduler, we built a system that we internally call VHM or Virtual Hadoop Manager. Now, let’s say work starts arriving on the green cluster. The green TTs start executing tasks. Depending on the resource needs of the green cluster, some VMs from the idle orange cluster get powered off. Now lets say work starts arriving on the orange cluster and it is of higher priority than the green cluster We now notice that some VMs from the green cluster get powered-off to satisfy the resource requests of the higher priority cluster. Now lets look at a little more detail into what the Virtual Hadoop Manger composes of.
- There are a number of characteristics that define true network and security virtualization, with the four key points being: Completely decouples virtual networks from physical network hardware Faithfully reproduces the physical network and security model in the virtual network space, workloads see no difference Automation, from both a cloud operations and network operations perspective. And, a platform that preserves choice
- Price / Performance: Consolidation yields benefits from both consolidation (hardware, data, and CPU pooling) as well as performance improvements (Time-to-Insight) Agility: Flexibility to re-configure Hadoop cluster post-facto for I/O, CPU or mixed workloads. Reduce OPEX with fewer clusters to manage with more flexibility Elasticity: create true multi-tenancy through separation of data and compute. Enables mixed workload usage.
- ----- Meeting Notes (2/4/13 11:32) ----- Case 1: numbers of cores per disk is doubling every couple of months. Abundance of CPU… constrained by storage. 3:2 is the common data coefficient. What types of isolation and sharing do we need? Hbase - tricky on resource isolation side. This slide is just talking about MR and for balanced workloads Assumes