20090914 Petamedia Irp5
•Download as PPT, PDF•
1 like•378 views

The document outlines a plan to develop a common dataset from social media sources for research purposes. It discusses acquiring video data from sources like Blip.tv and Flickr that have Creative Commons licensing. It also discusses obtaining social data by crawling links shared on platforms like Delicious, Digg, and Twitter that mention or tag those videos. Preliminary results showed over 10,000 videos obtained along with social mentions and links from those other sources. The plan is to further analyze the data and create a public repository if legally possible.















20090914 Petamedia Irp5
- 1. IRP5: Social Media Data Acquisition Presented by: Arjen P. de Vries
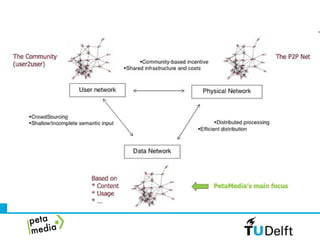
- 2. PROBLEM Each of us can think of many research questions related to the Petamedia objective of integrating the data network, the user network and the physical network...
- 4. PROBLEM ... but, today, these three networks are mostly disparate – they do not overlap! So, how to evaluate the effectiveness of our ideas?!
- 5. IRP5 OBJECTIVES Develop a common data-set that is large enough to allow meaningful research, and contains video content as well as explicit information generated by a social network of sufficient density Organize a PetaMedia ‘data-set yellow pages’ irp5petamedia.pbworks.com Functions also as crawling code repository!
- 7. DATASET REQUIREMENTS Availability of video data Creative Commons (CC) licenced data only Data sources with developer-friendly APIs only Availability of social data Users creating the data should be organized in a social network, and provide feedback about their preferences in relation to the data (comments, ratings, ...)
- 8. CANDIDATE DATA SOURCES Blip.tv high quality, 25-60% CC, poor social data Revver.com Medium quality, 100% CC, poor social data Flickr.com 200K CC, No API for access to video content
- 9. DECISIONS 1) Join Blip.tv and revver.com with Del.icio.us, digg and Twitter to get richer social data 2) Crawl links to videos, as well as the social networks of users creating those links, up to 4 levels of social network but only 2 levels of metadata (bookmarks/posts/profiles) 3) Crawl Flickr irrespective of missing API Comments, User info, Friend info Video data blip.tv revver.com Social ‘mention’ in Digg Del.icio.us Twitter
- 10. FLICKR Outline: Video data acquired through scraping the mobile flickr site ( m.flickr.com ) At most 90 seconds each Only mp4 (no flv) Metadata acquired through API Typical download rate: 1 video with metadata per minute Approach: Query for travel-related tags; 10 videos per tag Leads to 211 videos from 162 uploaders; Leads to 4143 videos in total from these uploaders Leads to 17598 videos from their 32K contacts
- 11. BLIP+REVVER Most popular videos: Blip-10,000 and Revver-10,000 data sets Social mentions of additional videos: 175 blip.tv and 45 revver.com downloadable videos mentioned at Del.icio.us (out of 5GB of social data, reached by starting with ‘joshua’ – its founder – and recursively following network fan links) 1250 blip.tv and 9198 revver.com video clips digg- ed (by 3602 unique users) ~850 blip.tv links posted by Twitter users per week
- 12. PRELIMINARY RESULTS Del.icio.us (now delicious.com) is better queried over the TU Berlin DAI-Labor lab collection (bookmarks from 2003-2007) 14K distinct links to blip.tv (from 22K bookmarks) 4K distinct links to revver (from 10K bookmarks) Reason: API truncates results to only 100 per item
- 13. PRELIMINARY RESULTS Twitter is better ‘crawled’ through Topsy, a search engine over Tweets 27K links to blip (from 42K indexed by Topsy) 300 links to revver (from ~1200 indexed by Topsy) Reason: API usage limited to #queries per IP address, but, more importantly, API access only to msgs at most 7 days old BTW: Topsy has been queried using ~2100 ‘popular’ `travel-related’ tags, to circumvent 500 results per query limitation
- 14. NEXT Crawl actual social network data and tweets corresponding to the Twitter V2 and Del.icio.us V2 links, by re-using QMUL and EPFL code
- 15. TO BE DONE Analyse data and methods Useful? Complete? Create data repository Legal check for public sharing Twitter data Flickr data html-scraped Advertise data sets (SIGIR-Forum?)
- 16. TEAM TUD: Pavel Serdyukov (coordination, Del.icio.us V2 , Twitter V2 ) Stevan Rudinac (blip.tv, revver.com) Ronald Poppe (blip.tv, revver.com) Maarten Clements (blip.tv, revver.com) Arjen P. de Vries (coordination) TUB: Sebastian Schmiedeke (flickr.com) EPFL: Ivan Ivanov (Twitter V1) UEP: David Chudan (Digg) Tomas Kliegr (Digg) QMUL: Naeem Ramzan (Del.icio.us V1) Muhammad Akram (Del.icio.us V1)