20131212 - Sydney - Garvan Institute - Human Genetics and Big Data
•
4 likes•950 views

This document discusses using machine learning and big data techniques in human genetics and biomedicine. It provides examples of how different data types like genotypes, phenotypes, gene expressions, and samples can be related through co-occurrence and similarity analyses. Dimensionality reduction techniques are used to classify samples by sex and ancestry. Genome-wide association studies are also discussed as a way to link genetic variations to traits.





























































20131212 - Sydney - Garvan Institute - Human Genetics and Big Data
- 1. Human Genetics & Big Data
- 2. Human Genetics & Big Data Human Genetics & Ethics Today we talk about technology and methodology
- 3. Me, Us • Allen Day, Principal Data Scientist, MapR Human Genetics PhD, UCLA School of Medicine 6 years Hadoop, 10 years R (Genetics/Biostatistics) • MapR Distributes open source components for Hadoop Adds major technology for performance, HA, industry standard API’s • See Also – @allenday @mapR – http://slideshare.net/allenday – “allenday” most places (twitter, github, maprtech.com, etc.)
- 4. What Does Machine Learning Look Like?
- 5. What Does Machine Learning Look Like Under the Covers? é T é A A ù é A A ù=ê 2 û ë 1 2 û ë 1 ê ë é =ê ê ë é r ù é ê 1 ú=ê ê r2 ú ê ë û ë O(κ k d + k3 d) = O(k2 d log n + k3 d) for small k, high quality O(κ d log k) or O(d log κ log k) for larger k, looser quality Here’s how to keep it simple yet powerful… T ù A1 úé A1 AT úë 2 û A2 ù û ù T T A1 A1 A1 A 2 ú AT A1 AT A 2 ú 2 2 û ù T T A1 A1 A1 A 2 úé h1 ê T T úê h 2 A 2 A1 A 2 A 2 ûë é é T ùê h1 T r1 = ê A1 A1 A1 A 2 ú ë ûê h 2 ë ù ú ú û ù ú ú û
- 6. Behavior of a crowd helps us understand what individuals will do HOW RECOMMENDATIONS WORK
- 7. Recommendations Alice Charles Alice got an apple and a puppy Charles got a bicycle
- 8. Recommendations Alice Bob Charles Alice got an apple and a puppy Bob got an apple Charles got a bicycle
- 9. Recommendations Alice Bob Charles ? What else would Bob like?
- 10. Recommendations Alice Bob Charles A puppy, of course!
- 11. Recommendations Alice What if everybody gets a pony? Bob Charles ? Now what does Bob want?
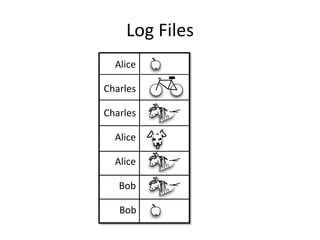
- 14. Log Files and Dimensions u1 t1 u2 t2 u2 t3 Things t1 u1 t4 t2 u1 t3 t3 u3 t3 t4 u3 t1 Users u1 Alice u2 Charles u3 Bob
- 18. Indicator Matrix ✔ id: t4 title: puppy desc: The sweetest little puppy ever. keywords: puppy, dog, pet indicators: (t1)
- 19. Problems with Raw Co-occurrence • Very popular items co-occur with everything – Welcome document – Elevator music – Everybody wants a pony • That isn’t interesting – We want anomalous co-occurrence
- 20. Recommendation Basics • Co-occurrence t3 not t3 t1 2 1 not t1 1 1
- 22. Spot the Anomaly A not A B 13 1000 not B 1000 100,000 A not A B 1 0 not B 0 10,000 0.90 4.52 A not A B 1 0 not B 0 2 A not A B 10 0 not B 0 100,000 1.95 14.3 • LLR (log likelihood ratio) is roughly like standard deviations
- 23. Genes => Traits => Behaviors => Fitness
- 24. Typical Dimensions in Genetics/Medicine • • • • Genotype Gene Expression Samples Phenotypes
- 25. Incidence/Co-occurrence in Genetics/Medicine • Genotype * Phenotype • Genotype * Genotype (sample similarity) • Sample * Sample (gene expression similarity) – Known genes => Sample annotation – Expression Level * Expression Level (sample similarity) – Known samples => Gene annotation • Gene expression * Phenotype – Etiological subtypes & re-diagnosis • Phenotype * Phenotype – (expression distance OR genotype distance) Etiological reclassification
- 26. DTRA102-007 – Forensic DNA Analysis Kit for Genetic Intelligence • • • • • • • • Sex Blood type Ancestry Hair morphology Dimples Freckles Shoe size Flat-footedness • • • • • Vision correction Ear lobe attachment Ear lobe crease 5th digit clinodactyly Eye color, hair color, skin color • Height, handedness • Etc https://sbirsource.com/grantiq#/topics/85383
- 27. DTRA102-007: Sex and Ancestry
- 28. Genotype and Phenotypes & GWAS DTRA102-007: chr7 Earlobe Morphology
- 29. SNPs and SNPs HapMap: Genotype call / spatial ordering This is the essence of the HapMap Project
- 30. Samples and Samples Label sex based on expression ● ● ● ● ● ●● ● ●● ● ● ● ● ●● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ●● ●● ● ●● ● ● ●● ● ● ●● ● ● ● ●● ● ● ●● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ● ●●●● ●● ●● ● ● ● ● ●● ● ● ● ● ● ● ●●● ● ● ●● ●● ● ● ● ●● ● ●●● ●● ●● ● ●● ● ● ● ● ● ●●● ●● ● ● ● ● ● ●● ● ● ● ●● ● ● ●●●●●● ● ●● ● ● ●●●●● ● ●● ● ●●●●●● ●●●●●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●●● ●●●●●●●●●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●●● ● ● ● ● ● ● ●●●● ●●●● ●● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ●●●●●●●●●● ● ●● ●●● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●●● ●●● ● ● ●●● ●● ● ●● ●●● ● ● ●● ● ●●● ● ●● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ●●●●●●●● ●● ●●●●● ● ●●●●●●●●●●●●●●●●●●●●● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ●●●● ●●● ● ● ●●●●●●●●●●●●●● ● ●● ● ● ● ● ●● ● ● ●● ●● ●●● ●●● ● ● ● ● ●● ● ● ● ● ●●● ●●●●● ●●●●●●●●●●●●●● ● ● ● ●● ● ● ● ● ●● ●●●● ● ● ● ● ●●●●●●●●●●●●●●●●●● ●●● ● ●●● ●● ●● ●● ●● ● ● ● ● ●●●● ●● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ●●●● ● ●● ● ●● ●● ● ● ●● ●● ● ● ● ● ●● ●●●●● ●● ●● ●●●●● ● ● ● ●● ●● ● ● ● ● ●●●●●●●●● ●●● ●●●●●●●●●●● ● ● ● ● ● ● ● ● ● ●●●● ●●● ●●● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ●● ● ● ● ●●●●●●● ●● ● ●●● ●●●● ● ● ● ● ● ●●●● ●●●●●●●●●●● ●●●●● ●●● ● ●●●●● ●● ● ●●●● ●●● ● ●●●● ● ●● ● ●●●●● ● ● ●● ●● ● ● ●●● ● ● ● ● ●● ●● ● ●● ● ● ●● ●● ●● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ●● ● ●● ●● ● ● ●●●●● ●●●●●● ● ● ●●● ●●● ●●● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ●● ● ● ● ●● ●● ● ●●●●●●●●●● ●●● ●●●●● ●● ● ● ● ● ● ●● ●●●●●● ● ● ●● ●●●● ●● ●●● ● ● ●● ● ● ● ● ● ● ● ● ●●● ●● ● ● ● ● ● ●● ● ● ● ●● ●● ●●●● ●●●●● ● ●●● ●● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ●●●●●●●●●●●●●●●●●●● ●●●● ●●● ●● ● ● ●●● ● ●●●●●●●●●●●● ●● ● ● ● ● ●● ● ● ● ● ● ●●●● ●● ● ● ● ● ●●● ●●●●● ● ● ● ● ● ●● ● ● ●●●●●●●●●●●●●●●● ●●●● ● ● ● ● ● ●●●●●●●●●●●● ● ● ● ● ● ●●●● ●●●●●●●●●●● ●● ●● ● ● ● ●●●●● ●●●● ●● ●● ● ● ● ● ● ●● ● ●●●●●●●●●●●●●●●●●●●●●● ● ● ● ● ●● ●● ●●●● ●● ● ●●● ●●● ● ● ●● ● ● ●●● ●● ● ●● ●●● ● ●● ● ● ● ● ●●● ● ●●● ●●● ● ● ●● ●● ●●●●● ●●●●●●●●●● ●● ●● ● ● ● ●●●● ● ● ●●● ●● ● ● ● ● ● ● ● ●●●●●●●●●● ● ●●● ●●● ● ● ●● ● ● ● ● ● ● ● ●● ●● ●●●●●●●●●●●●●●● ● ● ● ● ● ● ●● ●●●●●●●●●●●● ●● ● ● ● ●●● ● ●● ● ●● ● ● ●●● ● ●● ●●●●●●●●●●●●●●● ●●●● ● ● ● ● ● ● ● ● ● ● ● ● ●●●●●●●●●●●●●●●●●●●●●●●●● ●●● ●●●●● ● ● ● ● ●●● ●●● ●●●●●● ●● ● ● ● ●● ●● ●●●●●●● ● ● ● ● ●● ● ● ●● ● ●●● ●● ● ● ● ●● ● ●●●●● ● ●● ●● ● ● ● ● ● ●● ● ● ● ● ● ●●● ● ●●●●●●●●● ● ● ● ●● ●● ●● ●●●●●●● ●●●●●●●●●●● ●●●● ●●●●● ●● ● ● ●●● ● ●●● ● ●● ● ●● ● ● ● ●● ●●● ● ●● ● ● ● ● ● ● ● ● ● ● ●●●●●● ●●●●●●●● ●● ●● ●●● ●● ●● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ●● ● ●●●●●●● ● ●● ● ● ● ● ●●●●●●●●●●●●●● ●● ● ● ●● ● ● ● ●● ●●●●●●● ●●●●● ● ● ● ● ● ● ● ●●● ● ● ● ● ● ● ●●● ●● ●●● ●● ● ●●● ●●●●●● ●●●●●● ● ● ● ● ● ● ● ● ●●●● ●●●●●●●●●●●● ● ●● ●●●● ● ● ● ● ● ●● ●●●●● ● ●● ●●●● ● ● ●●● ● ●●●●● ●● ●●● ● ● ● ● ● ●●●●●●●●●●●●●●●●● ●● ● ● ●● ● ● ● ●●●● ● ● ● ●●●●●●● ●●●● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ●● ● ● ●●●●● ●● ●●● ●● ●● ● ●●● ●● ● ● ● ●●●●●●●●●●●●●●●●●●●● ●● ●●● ● ● ●●●● ●● ● ●● ●●●●● ● ● ● ● ●● ●● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ●● ● ●●●●●● ● ●● ●● ●● ● ●●● ●● ● ● ● ● ● ●●●● ● ●●● ● ●●●●●● ●● ● ● ●● ● ● ● ● ● ●●● ● ● ●● ● ● ●● ●●●● ●●●●● ●●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ●●●●● ●● ● ● ● ● ●● ● ● ● ● ● ●●● ● ● ●● ●● ● ● ● ● ● ● ●● ● ●●● ● ● ●● ● ● ● ● ●● ● ● ● ● ●● ●●●●●●●● ● ●●●● ●●●●●●● ● ● ● ● ●● ●● ● ●● ●●●●●● ● ● ● ● ● ● ●● ●● ●● ●●● ● ● ● ●● ●● ● ●● ● ●●●● ●● ●●● ●● ●●● ●●●●●●● ●● ●● ● ● ● ●● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ●● ●● ● ● ●● ● ● ●●● ● ● ● ● ● ● ● ● ● ● ● ● ●●●●● ●● ●●●●●● ● ● ● ● ● ● ●● ● ● ● ●● ●● ●● ●●● ● ● ●● ● ●●●●●●●● ●●●● ●●●●● ● ● ● ● ●●●●●●●● ●●●●●●●●●●●● ● ● ● ●● ●● ●● ● ● ● ●● ● ● ●●● ● ● ● ● ● ●●●● ● ●●● ● ● ● ● ● ● ● ●● ● ● ●● ●● ● ●● ● ●●● ●● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ●●● ● ● ● ● ● ● ● ● ● ● ●● ● ●●●●●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●●● ●●● ●●●●●● ●●●● ●●●●● ● ● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ●● ● ●●●● ●●●●● ●● ●● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ●● ●●● ● ● ●● ●●●●● ● ●●●● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ●●●● ● ● ● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●●● ●● ● ● ● ● ● ●●● ● ●●●●●●●●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●●● ● ● ●●●●●●●●●● ●● ● ●● ● ● ● ● ● ●● ● ● ●● ● ● ●●●● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ● ● ●● ●● ● ● ● ● ● ●●●●●●● ● ● ● ● ●●●●● ● ●● ● ●● ● ● ● ● ●● ● ● ●● ● ● ● ●●● ●● ●● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●●●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ●●●●● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ●●● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ●● ●● ● ● ●● ● ●● ● ● ● ● ● ●●● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ●● ● ●● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ●● ● ●●● ● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●●●● ● ●● ●●● ● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ●● ● ● ●● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ●● ● ● ● ● ●● ● ●●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ● ●● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ●● ● ●● ● ● ● ● ●● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ●● ●● ●● ● ● ● ● ●● ● ● ● ●● ● ●●●● ● ● ●● ● ● ● ● ● ● ●● ● ● ●●● ● ●● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●●● ● ● ●● ● ●●● ● ●● ●● ● ● ● ● ●● ● ●● ●● ● ●●●● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●●● ●●● ● ●● ● ● ● ● ● ● ● ●● ●●● ● ●● ●● ●● ●●●● ● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●●● ● ● ●●● ● ● ● ●● ●● ● ● ● ●●●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ●●●●●● ● ● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ● ● ● ● ●● ● ● ●● ● ● ● ● ● ●●●●● ● ●● ●● ● ● ●●● ● ● ●● ●●● ● ●● ● ● ● ● ● ● ●● ●●● ● ● ● ●● ●● ●● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ●● ● ●● ● ● ● ● ●●● ● ●● ●●●●● ●● ● ● ● ● ●●● ● ●● ●● ● ● ● ● ●●●● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ●●● ●●●●● ● ● ● ● ● ●● ● ● ●● ● ● ● ●● ●● ● ● ● ● ● ●●● ● ● ● ● ●● ●●● ● ● ●● ● ● ● ● ● ●●● ● ● ● ● ● ●● ● ● ● ● ●● ●●● ●● ● ●●●●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ● ●● ● ● ● ●● ● ● ●● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ●● ●● ●●●●● ●● ●●● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●● ● ● ● ● ● ●● ● ●● ●● ●●● ●● ●● ● ● ●● ● ● ● ●● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ●● ●● ●● ●●● ● ● ●● ● ● ● ● ● ● ● ● ●● ●● ●● ●● ●● ● ● ● ● ● ●● ● ● ●●● ●●● ● ●●●●●●● ● ●● ● ●●●●●● ●● ● ● ●● ● ●●● ● ● ● ● ● ●●●●●● ●● ● ● ● ●● ● ● ● ● ● ● ●● ● ●● ● ●● ● ● ●●●●● ● ●●●●● ● ●● ● ● ● ● ● ● ●●● ● ● ● ● ● ●● ●● ● ● ● ● ●●● ● ●●●●● ● ● ● ● ●● ●● ● ● ● ● ● ●●● ● ● ●●● ● ● ● ● ● ● ●● ● ●● ●●● ● ●● ● ● ●●● ● ● ● ● ● ● ● ● ● ● ●●● ● ●● ● ● ● ●● ●● ●● ● ● ●●● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ●●● ● ●● ● ●● ● ● ● ●●● ●●● ● ●● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ●●●● ●●● ●● ●●●● ● ● ●● ● ● ●● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ●● ● ●●●● ● ● ● ● ● ●● ●● ●●●●● ●●●●●●● ●● ● ● ● ●●● ● ●● ●●●● ● ●● ● ●●● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ● ●●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ●● ● ●●●●●●●●●●●●●●● ●● ● ● ● ●●●●●● ●● ● ●●● ● ● ● ● ●● ●● ● ● ● ●● ● ● ● ●● ●● ● ●●● ●● ●●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ●● ● ● ●● ● ●● ● ● ● ●● ● ● ● ● ●● ● ●● ●●●●●●●●●●●●●● ● ●● ● ● ●● ●● ● ●● ● ● ●●● ●● ●●●● ● ● ● ● ● ● ● ● ● ● ● ●●● ●● ●●●● ●● ● ●●● ● ●●●●● ●● ●● ●● ● ●●● ● ● ● ● ● ●● ● ● ●●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ● ●● ●● ● ●● ●● ●● ● ● ● ● ● ● ●● ●●● ●●●●●● ● ● ● ● ● ●● ●● ● ● ●● ● ● ● ●●● ● ● ● ● ●● ● ●●●● ● ●●● ● ●● ● ●●●● ● ● ●●● ● ● ●● ●●●● ● ● ● ●●●●●● ●● ●●● ● ●●●●● ●● ● ●●● ●● ●●● ●●●●● ● ●● ●● ●● ●● ● ● ●● ● ● ● ● ● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ●● ●●●● ●●●●● ● ●● ●● ● ●● ● ● ● ● ● ● ● ●●●●●● ●●●●●●●●● ●●●● ●●● ● ●●●●● ●●●●●●●● ●●● ●●● ● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ●●● ●● ● ● ● ● ●● ●● ● ● ●●●●●●● ● ●●● ● ● ●●●●●●●●● ● ● ● ●●● ●●●● ●● ● ● ● ●●●● ●● ●●●●●● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ●● ●● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ●● ●●● ●●● ●●●● ● ●● ● ● ● ●●●●●●●● ●●●●●●● ●●● ●● ●●● ● ● ●● ● ● ● ● ●● ● ●●● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ●●● ● ●● ●●●●●● ●●●● ● ● ● ● ● ●● ● ●● ● ●● ●●●●● ●●● ● ● ● ● ●● ●● ● ●●● ● ● ● ● ● ●● ● ●●● ●●●● ● ● ●● ● ● ● ● ●● ● ● ●● ●●●●● ● ●● ● ● ●●● ● ● ●●● ● ●●● ●● ● ●● ●● ● ●●●●●●● ● ●●●●●●● ● ● ●●● ●●●●●●●● ●●●●● ●●●●●●●●●●● ●●●●●●● ● ● ●●● ● ●● ● ●● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ●●●● ●●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●●●● ● ●● ●●● ● ● ● ● ● ●● ● ● ●●● ●●● ● ● ●● ● ● ●●● ● ●● ●● ● ● ●●● ●●●● ● ● ● ● ●● ● ● ● ● ● ● ●●● ●● ● ● ●● ● ● ● ● ● ● ●● ● ●● ●● ● ●● ● ● ●● ● ●●● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ●● ● ●● ● ●●●● ●●●●● ●●●●● ●●● ● ● ●● ● ● ● ● ● ● ●●● ●●●●●●●● ●●●●●● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ●● ●● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ●●● ●●●●●●●●●●●●●●● ●● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●●● ● ● ●● ● ●●●● ●● ● ● ● ● ● ●●●●●●● ● ● ● ●●●●●● ● ●●● ●● ● ●●●●●●●● ● ● ●●●●●●●● ● ●● ● ●●●● ●●● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ●● ●● ● ●●●●● ● ● ● ●● ● ●● ● ● ●● ●●● ●● ●● ● ● ● ●●● ● ● ● ● ●● ●● ●● ●● ● ● ● ● ● ●● ● ● ● ● ●●●● ●● ● ● ● ● ●●● ●● ● ● ●● ●● ● ●● ●● ● ● ●●● ●● ● ● ● ● ● ●● ● ●●● ●●● ● ● ●● ●●●● ● ● ●●● ●●●●● ● ● ● ●● ● ●● ● ● ● ●● ● ● ● ●● ●●● ● ●● ● ● ● ●●●● ● ●●● ●●●● ●● ● ● ● ● ● ● ● ●●● ●●●●● ●● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●●●●●● ●●●●● ● ● ● ● ● ● ●● ● ● ● ● ● ●●●●● ●●●●● ●● ● ● ● ●● ●● ● ● ● ● ● ●● ● ● ●●● ● ●●● ● ● ●● ● ●●●●●●● ● ● ●● ●●●● ●● ● ● ● ● ● ●●●●● ●●● ●●●● ● ●●●●●●● ●●● ●● ●●●● ● ● ●●●●● ● ● ● ● ● ● ● ● ●● ● ● ● ● ●●●●● ●● ● ● ● ● ●● ●● ●● ● ● ● ● ● ●● ● ●● ● ● ● ● ●● ●● ● ●● ● ● ● ● ●● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ●●● ● ● ● ● ● ● ● ●● ●●● ● ● ●●● ● ●● ● ●●●●● ● ●●●●● ● ● ● ●● ●●●●●● ●●●● ● ●● ●●●● ● ● ●● ●●●●● ●● ●●● ● ●● ● ●● ●●●●●● ● ● ●●●●●●●●● ●● ● ● ● ● ● ●●●●●●●●●● ● ●● ● ● ●● ● ● ● ● ● ● ● ● ●●● ● ●●● ● ●● ● ● ● ●●● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ●● ●● ●●● ● ● ● ● ● ●● ● ●● ●● ●●●●● ● ●●● ● ●● ● ●●● ●●●●● ● ●● ● ● ●● ● ●● ● ● ●● ● ● ● ●● ● ● ●● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ●●●●●● ●●●● ● ● ● ● ● ● ●●● ● ●● ● ● ●●● ●●●●● ●● ●● ●● ● ● ●● ●●● ● ● ● ● ● ● ● ● ● ●● ● ● ●●● ● ●● ●●●● ●● ●● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ●● ●●●● ●● ●● ● ●●● ● ● ●●● ●● ● ● ● ● ●●●●● ● ● ● ● ●●● ●●●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●● ● ●● ● ●● ● ● ● ● ●●● ● ● ● ● ● ● ● ● ● ● ●● ● ●● ●● ●● ● ● ●● ● ● ●●● ● ● ●● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ●●●●● ●● ● ● ● ●● ●● ●● ●●●● ● ●●● ● ● ● ● ● ● ● ● ● ●●●● ● ●● ● ●● ● ● ● ● ● ● ● ● ● ●● ●● ●● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●●● ● ●●●●● ● ● ●●● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ●● ●● ●● ● ● ●● ● ● ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ●● ● ● ● ●● ● ● ●● ● ● ● ● ●● ● ● ● ●●● ● ● ● ● ● ●● ● ●●● ● ●● ● ● ● ● ● ● ● ●● ●● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ●● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ●● ● ● ● ● ● ●● ● ● ● ● ● ● ● 3.0 2.5 1.5 2.0 RPS4Y1 log(RMA) 3.5 ● ● 1.5 2.0 2.5 3.0 XIST log10(RMA) Celsius: a community resource for Affymetrix microarray data. http://www.ncbi.nlm.nih.gov/pubmed/17570842 3.5
- 31. FZD10 SLC28A3 HSPC159 BDKRB1 HAS2 XYLT1 RNF24 RNF24 SOD2 RELB RLF NUPL1 EIF2C2 FOSL1 RELA ETNK1 MMP12 AKR1C1 TNMD CYTL1 SOX5 MIA CHST3 PDLIM4 PDPN WISP1 C1QTNF3 THBS3 COL10A1 COL10A1 COL11A1 COL11A1 EPYC MATN3 MAST4 NGF EDIL3 ITGA10 HAPLN1 HAPLN1 MATN4 LECT1 MATN1 COL9A1 COL11A2 COL11A2 ACAN ACAN ACAN CSPG4 MMP13 NOS2A LIF MMP3 BMP2 BMP6 Expression and Expression (10K+ samples) Gene Annotation (co-expression) SLC28A3 HSPC159 BDKRB1 HAS2 XYLT1 RNF24 RNF24 SOD2 RELB RLF NUPL1 EIF2C2 FOSL1 RELA ETNK1 MMP12 AKR1C1 TNMD CYTL1 SOX5 MIA CHST3 PDLIM4 PDPN FZD10 WISP1 C1QTNF3 THBS3 COL10A1 COL10A1 COL11A1 COL11A1 EPYC MATN3 MAST4 NGF EDIL3 ITGA10 HAPLN1 HAPLN1 MATN4 ACAN ACAN ACAN LECT1 MATN1 COL9A1 COL11A2 COL11A2 CSPG4 MMP13 NOS2A LIF MMP3 BMP2 BMP6 Disease gene characterization through large-scale co-expression analysis. http://www.ncbi.nlm.nih.gov/pubmed/20046828
- 32. FZD10 SLC28A3 BDKRB1 HSPC159 HAS2 RNF24 XYLT1 RNF24 RELB SOD2 RLF EIF2C2 NUPL1 FOSL1 ETNK1 RELA MMP12 TNMD AKR1C1 CYTL1 MIA SOX5 CHST3 PDPN PDLIM4 WISP1 THBS3 C1QTNF3 COL10A1 COL11A1 COL10A1 COL11A1 MATN3 EPYC MAST4 EDIL3 NGF ITGA10 HAPLN1 HAPLN1 MATN4 MATN1 LECT1 COL11A2 COL9A1 COL11A2 ACAN ACAN ACAN MMP13 CSPG4 NOS2A MMP3 LIF BMP2 BMP6 Co-expression (10K samples) and Linkage Gene Annotation / Set Completion SLC28A3 HSPC159 BDKRB1 HAS2 XYLT1 RNF24 RNF24 SOD2 RELB RLF NUPL1 EIF2C2 FOSL1 RELA ETNK1 MMP12 AKR1C1 TNMD CYTL1 SOX5 MIA CHST3 PDLIM4 PDPN FZD10 WISP1 C1QTNF3 THBS3 COL10A1 COL10A1 COL11A1 COL11A1 EPYC MATN3 MAST4 NGF EDIL3 ITGA10 HAPLN1 HAPLN1 MATN4 ACAN ACAN ACAN LECT1 MATN1 COL9A1 COL11A2 COL11A2 CSPG4 MMP13 NOS2A LIF MMP3 BMP2 BMP6 + => Disease gene characterization through large-scale co-expression analysis. http://www.ncbi.nlm.nih.gov/pubmed/20046828
- 33. Typical Dimensions in Genetics/Medicine • • • • Genotype Gene Expression Samples Phenotypes (traits/behavior)
- 34. Typical Dimensions in Behavioral Data • • • • Genotype Gene Expression Samples Individuals Phenotype – Traits – Behaviors
- 35. Traits and Behaviors Content Topic Modeling / UX Personalization
- 36. Behaviors and Outcomes Economic Fitness (Korn/Ferry) => Allen Korn/Ferry ProSpective http://linkedin.kornferry.com
- 37. Behavior of a crowd helps us understand what individuals will do HOW CROSS-RECOMMENDATIONS WORK
- 38. Example Multi-modal Inputs • • • • Overlap in restaurant visits is useful Big spender cues Cuisine as an indicator Review text as an indicator
- 39. Too Limited • People do more than one kind of thing • Different kinds of behaviors give different quality, quantity and kind of information • We don’t have to do co-occurrence • We can do cross-occurrence • Result is cross-recommendation
- 40. For example • Users enter queries (A) – (actor = user, item=query) • Users view videos (B) – (actor = user, item=video) • ATA gives query recommendation – “did you mean to ask for” • BTB gives video recommendation – “you might like these videos”
- 41. The punch-line • BTA recommends videos in response to a query – (isn’t that a search engine?) – (not quite, it doesn’t look at content or meta-data)
- 42. Real-life example • Query: “Paco de Lucia” • Conventional meta-data search results: – “hombres del paco” times 400 – not much else • Recommendation based search: – Flamenco guitar and dancers – Spanish and classical guitar – Van Halen doing a classical/flamenco riff
- 44. Hypothetical Example • Want a navigational ontology? • Just put labels on a web page with traffic – This gives A = users x label clicks • Remember viewing history – This gives B = users x items • Cross recommend – B’A = label to item mapping • After several users click, results are whatever users think they should be
- 46. Detect similar content: 2 & 8 user1 user2 user3 user4 user5 1 2 3 4 5 6 7 8
- 47. Call to Action – Request Clicks user1 Show me more: user2 sports user3 comedy technology user4 user5 1 2 3 4 5 6 7 8 “Under Construction”
- 48. Guess Labels: 4=sports ; 2 & 8=comedy user1 Show me more: user2 sports user4 user5 1 2 3 4 5 6 7 8 comedy 2&8 technology user3 4 Under construction
- 50. Matrices A (U*Q) and B (U*V) Clicked Videos Users Query Term = Clicked Term Users Query Terms
- 51. Query Terms Join on dimension U… Users
- 52. Query Terms Relate Q to V Users
- 53. Relate Q to V Query Terms Clicked Videos
- 54. Medicine Forensics Job Performance Genes => Traits => Behaviors => Fitness Psychometrics Movie Preferences
- 56. (Traits/Behaviors) and Outcomes Reproductive Fitness (eHarmony) eHarmony @ Hadoop World: Data Science of Love http://eharmony.com
- 57. (Traits/Behaviors) and Outcomes Reproductive Fitness (eHarmony) eHarmony @ Hadoop World: Data Science of Love http://eharmony.com = 185cm Allen
- 58. (Traits/Behaviors) and Outcomes Reproductive Fitness (eHarmony) eHarmony @ Hadoop World: Data Science of Love http://eharmony.com = 185cm Allen
- 59. (Traits/Behaviors) and Outcomes Reproductive Fitness (eHarmony) eHarmony @ Hadoop World: Data Science of Love http://eharmony.com = 185cm Allen
- 60. Medicine Forensics Job Performance Genes => Traits => Behaviors => Fitness Psychometrics Movie Preferences Fitness Reproductive Outcomes
- 61. Thank You!!
- 62. Me, Us • Allen Day, Principal Data Scientist, MapR Human Genetics PhD, UCLA School of Medicine 6 years Hadoop, 10 years R (Genetics/Biostatistics) • MapR Distributes open source components for Hadoop Adds major technology for performance, HA, industry standard API’s • See Also – @allenday @mapR – http://slideshare.net/allenday – “allenday” most places (twitter, github, maprtech.com, etc.)
Editor's Notes
- Note to speaker: Move quickly through 1st two slides just to set the tone of familiar use cases but somewhat complicated under-the-covers math and algorithms… You don’t need to explain or discuss these examples at this point… just mention one or twoTalk track: Machine learning shows up in many familiar everyday examples, from product recommendations to listing news topics to filtering out that nasty spam from email….
- Talk track: Under the covers, machine learning looks very complicated. So how do you get from here to the familiar examples? Tonight’s presentation will show you some simple tricks to help you apply machine learning techniques to build a powerful recommendation engine.
- I suppressed slide and added a duplicate with arrow to show that the line from the indicator matrix goes into indicator field of the same Solr index that stores meta data for each item.
- Allen: I suppressed slide and added a duplicate with arrow to show that the line from the indicator matrix goes into indicator field of the same Solr index that stores meta data for each item.May want to explain that the model to produce indicator matrix can be done with Apache Mahout or other approaches. A nifty way to deploy it is to use Apache Solr (such as LucidWorks) to build an index for metadata for the items (shown here). Then the output of the ML model, the indicator data (also shown here) goes into a field in the same index. All this done offline ahead of time, so that makes the actual step of recommendation fast. A new user arrives, interacts and that event triggers a Solr search to find matching ID’s in indicator fields of different documents, hence the source of recommendation. Because only that part is done live, the response can be FAST
- Point out what matters is SIGNIFICANT or interesting co-occurrence (meaning anomalous co-occurrence). Ponies don’t help because everybody wants a pony
- Human HG-U133A CELs are automatically classified for sex of the tissue or cell line of origin. Orange points are manually curated as male and are also correctly classified as male. Red points are manually curated male that are falsely classified as female. Wheat points are classified as male but do not have manually curated results. These three types of points are also denoted by different shapes in the order of triangle, filled triangle, and circle respectively. All points are classified by assigning two clusters in five-dimensional probeset space, two of which are shown. x-axis, 221728_x_at, XIST; y-axis, 201909_at, RPS4Y1.
- The genomic position (x-axis) of probesets within a 6 megabase region centered at the location of TTN, a gene known to be associated with LMGD2, is plotted versus the Pearson correlation coefficient An external file that holds a picture, illustration, etc.Object name is pone.0008491.e023.jpg (y-axis) to a list of probesets targeting other genes known to be associated with LGMD2 (excluding TTN) across 11636 HG-U133_Plus_2 microarrays. Solid circles: probesets targeting TTN, An external file that holds a picture, illustration, etc.Object name is pone.0008491.e024.jpg: probesets that are for genes of unknown function and, open circles: probesets for known genes in interval.
- Allen: What do you plan to say about this? General example without anything proprietary?
- Allen: What do you plan to say about this? General example without anything proprietary?
- Allen: this is the transitional slide from talking about more than one input to one step further: cross recommendation. I doubt you want to use it as it, but I’ve included it FYI
- Allen: additional transitional slide
- Allen: What do you plan to say about this? General example without anything proprietary?
- Allen: What do you plan to say about this? General example without anything proprietary?
- Allen: What do you plan to say about this? General example without anything proprietary?
- Allen: What do you plan to say about this? General example without anything proprietary?