IIIF Introduction and Opportunities at Cornell
•Download as PPTX, PDF•
3 likes•1,087 views

Presentation on IIIF (International Image Interoperability Framework, <http: />) for the Cornell University Library, Visual Resources Working Group
Report
Share

















































IIIF Introduction and Opportunities at Cornell
- 1. What is IIIF? Why is it needed? What can it enable? Where is it going? And how can we use it to improve the services we offer? Simeon Warner, Cornell University Library with plenty of help, and slides, from other IIIF participants, including Michael Appleby (Yale University), Robert Sanderson (Stanford University), Jon Stroop (Princeton University), Stuart Snydman (Stanford University), and Benjamin Albritton (Stanford University)
- 2. IIIF – the International Image Interoperability Framework – has the following goals: • To give scholars an unprecedented level of uniform and rich access to image-based resources hosted around the world. • To define a set of common application programming interfaces that support interoperability between image repositories. • To develop, cultivate and document shared technologies, such as image servers and web clients, that provide a world-class user experience in viewing, comparing, manipulating and annotating images.
- 3. Why is IIIF needed? A motivating example
- 4. Otto Ege - Biblioclast Ege slides from Ben Albritton, Stanford University Libraries
- 5. Otto Ege, Manuscript 1 - 1940
- 6. Otto Ege, MS 1 - 2014
- 7. So, how do I work with Ege MS 1 ?
- 8. What does IIIF enable?
- 9. Stanford Leaves of Ege MS 1 http://guillaumedemachaut.com/mirador/index_ege.html
- 10. Partial Reconstruction of Ege MS 1 Mirador viewer showing images from 16 institutions, each serving their own images
- 11. Facing pages at different institutions
- 12. Even when some images are missing
- 13. Detailed comparison between pages at different institutions
- 14. Zoom to compare details
- 15. Creation of new interactive presentations
- 16. John Constable (1776-1837) Stonehenge – Making a Masterpiece Sketch (1820): V&A Watercolour Sketch: BM Watercolour (1835) Victoria and Albert Museum Watercolour Sketch: V&A + Letters + Exhibitions + Essays + Related Works + Bibliography
- 17. Why is IIIF needed? Take two
- 18. I am locked into my image delivery software
- 19. I need a newer, faster image server (and I can’t spend much time or money on it)
- 20. I want deep zoom (and I want it on mobile too)
- 21. I want to allow users to visually compare objects in the collection…
- 22. …with images of objects from other collections
- 23. I want to make it easy for my users to cite and share my images and regions of those images
- 24. I want to allow embedding of my images in blogs and web pages
- 25. I want to allow users to annotate images online (and share, or not share, those annotations)
- 26. And I shouldn’t have to invent any of it.
- 27. IIIF Vision • from participating institution can be delivered in a standard way • via compatible image server • for display, manipulation and annotation in application, • to user on the Web, • in combination of elements. Create a global framework by which image- based resources (images, books, maps, scrolls, manuscripts, musical scores, etc.)
- 28. IIIF Vision, continued • with of image-based resources • backed by a consortium of • supported by a rich and growing suite of • incorporating the , and
- 29. What is IIIF? (Now that we know what is needed)
- 31. 1. Two APIs Get images via a simple, RESTful, web service. Support for tiles needed for pan-zoom viewers. Just enough metadata to drive a remote viewing experience. (e.g. sequence, labels, attribution, license) Image API Presentation API
- 32. 2. Compatible Software IIP Image IIP Moo Viewer digilib FSI Viewer FSI Server Wellcome Player Mirador Internet Archive Book Reader Image Server s Image Clients Image Apps
- 33. 3. Community National Libraries • British Library • France • Denmark • Israel • New Zealand • Norway • Poland • Serbia • Wales Research Institutons •C2RMF (France) •Cornell University •Johns Hopkins Univ. •Harvard University •Oxford University •Princeton University •Stanford University •Wellcome Library •Yale University Projects • Biblissima • e-codices • TPEN • TextGrid Aggregators • Artstor • DPLA • Europeana Museums • YCBA • British Museum
- 34. Grain elevators, Caldwell, Idaho, by Lee Russell, 1941. http://www.loc.gov/pictures/resource/fsac.1a34206/
- 35. Why standardize APIs? Without shared standards we have silos
- 36. Insert standard APIs Technology becomes interchangeable
- 37. Facilitate distributed access over standard APIs Content becomes shareable
- 38. http(s)://{server}{/prefix}/{id}/info.json http(s)://{server}{/prefix}/{id}/{region}/{size}/{rotation}/{quality}.{fmt} Image API 1. Information Request o (Just Enough) Technical Metadata o Server Capabilities 2. Image Requests o Get the Pixels Enough to support single image access, pan-zoom viewers, region extraction, etc.
- 39. Image API – Image Request Region Size Mirror Rotation Quality
- 40. Presentation API Features • Metadata Labels and Values • Ordering Arrangement of Images and Other Content • E.g. page order, arrangement of fragments • Object Structure and Layout • Including Links to the Image API • Relationships to Related Resources • Attribution and Licensing • All described in RDF, expressed in JSON-LD • “Annotation ready” I’m skipping lots here, for see http://www.slideshare.net/jpstroop/iiif-specifications-overview
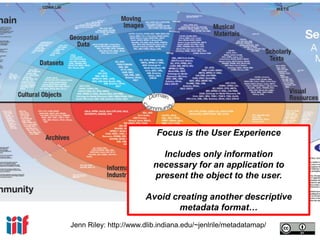
- 41. Jenn Riley: http://www.dlib.indiana.edu/~jenlrile/metadatamap/ Focus is the User Experience Includes only information necessary for an application to present the object to the user. Avoid creating another descriptive metadata format…
- 42. Structure example: page order and direction
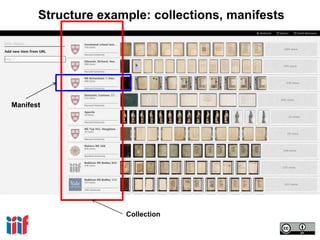
- 43. Structure example: collections, manifests Collection Manifest
- 44. Photo: Jeffrey Emanuel Thanks to Harvard’s Fogg Museum and Rashmi Singhal Not just scanned pages: Images of 3D objects
- 45. Where is IIIF going?
- 46. IIIF Roadmap • Authorization / Authentication o Top priority, sadly not everything can be open o Must cope with distributed content, and graded access rather than just binary yes/no • Search within (text and annotations) o Control scope to what is necessary – avoid complexities of generalized search across collections and federated search… o Search only within information related to known item(s) • Discovery of Manifest and Image Identifiers o How can we support discovery of IIIF resources and collections? • Add create/update/delete functions to API (complete CRUD) o Possibility of generic IIIF storage appliance and use of off- the-self software
- 47. How can we use IIIF to improve the services we offer?
- 48. IIIF at Cornell • Three threads: o Image access and viewers o Book readers o Flexible image re-use for commentary, discussion, exhibits • Key technology ties: o Artstor / SharedShelf will support IIIF (demo site already available to us) o Strong interest within Hydra community (so likely good tools that will be easy for us to adopt) so a good path for our Hydra-based DLXS replacements o Spotlight technologies are closely related to our D&A and Hydra projects
- 49. Silo IA page turner was state of the art…
- 50. Newly formed Hydra page turner IG “Whereas a year ago one might have been forgiven for thinking that the JavaScript Internet Archive Page Turner was the application of choice, the emergence of the IIIF Presentation API specification has significantly changed the landscape. A number of presentation tools have developed, or are developing, a version conformant with the new API specification. Thus, if an institution's Hydra head offered an IIIF Presentation endpoint, there would be a choice of tools (amongst them page turners) that could be layered over the top of it.” (Richard Green, Hull, UK)
- 51. Pointers • IIIF website: http://iiif.io/ • IIIF showcase: http://showcase.iiif.io/ • Discussion: iiif-discuss@googlegroups.com (and archives at https://groups.google.com/forum/#!forum/iiif-discuss) • IIIF code: https://github.com/iiif/
Editor's Notes
- What is IIIF? Why is it needed? What can it enable? Where is it going? And how can we use it to improve the services we offer? Talk by Simeon Warner for the Cornell University Library, Visual Resources Working Group. Slides borrow heavily from previous talks by other IIIF participants, including Michael Appleby (Yale University), Robert Sanderson (Stanford University), Jon Stroop (Princeton University), Stuart Snydman (Stanford University), and Benjamin Albritton (Stanford University). Source slide decks include http://www.slideshare.net/jpstroop/iiif-specifications-overview , http://www.slideshare.net/azaroth42/iiif-linked-data, and see presentations from MCN 2014 https://www.youtube.com/watch?v=10nSAljOTCk
- IIIF goals: unprecedented access, common APIs, culture of shared technologies
- Why is IIIF needed? A motivating example
- Story from Ben Albritton about biblioclast Otto Ege
- Noted biblioclast Otto Ege owned a glossed bible, likely French 12th century
- He broke up the manuscript in the 40s and 50s to include in one of his manuscript leaf portfolios, which were then sold throughout North America. In the intervening years, many leaves have appeared in collections, but many have also gone missing. We can identify 33 separate institutions owning pieces of this manuscript currently – but there are more institutions and individuals out there that have bits.
- Current discovery and access situation involves many different institutional services – terrible
- What does IIIF enable?
- 18 leaves, not previously recognized as belonging to the Ege book until Albritton began working on them in late 2013
- 16 institutions – each serving their own image
- In a continuous scroll view
- Provide placeholders and info about missing leaves
- Two images – one from Kenyon College, the other from Ohio State University. Perhaps worth reiterating here that the source images are being copied about here, just the derivative image tiles necessary for display
- Zoom to compare features from images provided by different institutions – to the detail of the letter
- Create new interactive presentations that mix overview images, descriptions, page views, detail views etc.
- Of course these facilities are not limited to manuscripts, one might bring together important sketches from a painter as a way to help understand the final work. In this case we imagine sketches for Constable’s “Stonehenge” which are held at different museums in London
- Why is IIIF needed? Take two
- A few statements many of us in the library community have made about our image and collection delivery environments – we are often locked into particular solution
- Periodic upgrades are required, maintenance often hard to fund
- Deep zoom is expected by users and they want it to work on their phone too
- Need to be able to compare items in collection
- ... and between collections
- Users should be able to share/link to items, and specific regions
- Embed in blogs and web pages
- Users should be able to annotate
- These are shared requirement so individual institutions should not have to re-invent these facilities
- With these requirements in mind, let’s revisit the IIIF vision: Create a global framework by which image-based resources (images, books, maps, scrolls, manuscripts, musical scores, etc.) - from any participating institution can be delivered in a standard way - via any compatible image server - for display, manipulation and annotation in any application, - to any user on the Web, in any combination of elements.
- IIF vision continued - with tens of millions of image-based resources - backed by a consortium of world-leading cultural heritage and research institutions - supported by a rich and growing suite of software tools - incorporating the best of current image delivery technology, and leveraging Web standards
- Again: What is IIIF? (Now that we know what is needed)
- Three things: 1.) APIs 2.) growing suite of compatible software 3.) community of adopters
- The two APIs are: Image API and Presentation API
- Three layer of compatible software: bottom up: image servers; image clients; image apps
- Strong IIIF community: national libraries, research institutions, museums, aggregators, projects
- And not to mention, our systems and website are like silos. Our image repositories web servers and asset management environments are configured as silos. Our front-end applications are one-offs. When moving from site to site, users have to relearn how to engage productively with images.
- Without standard APIs we are doomed to have silos, applications tied to specific servers. This ties the hands of service providers because they can mix-and-match technologies, and also of users
- Shared APIs make technologies interchangeable, giving us choices between different technologies in the different roles within our application stack
- Allowing distributed access over standard APIs allows users to reuse and remix content, and supports an ecosystem of applications
- The Image API provides just enough information (technical metadata) to allow clients to request derivative images for display. The image API defines URI syntax and packs all of the parameters into a clean path-based syntax. That said, having a tidy persistent URL for citations, annotations, web exhibitions, emailing, and other means of sharing can be quite useful.
- The Image API specifies how servers must interpret image requests. Servers must apply each transformation from left to right, i.e. in the order specified by the API URI. Servers don’t necessarily have to support all operations and this is expressed in the technical metadata (e.g. rotation is not necessary for common zoom-pan viewers)
- Presentation API: What it is: Metadata Labels and Values Ordering Arrangement of Images and Other Content Object Structure and Layout Including Links to the Image API Relationships to Related Resources Attribution and Licensing
- Presentation API: What it is not! It is not another metadata format
- Paging The API distinguishes between rtl, ltr, ttb, btt directionality There are also features for, e.g. indicating that a page should be skipped
- Again, back in the Mirador viewer we can see how collections and manifests relate to each other.
- Presentation API provides detail to interact with images of 3D works
- Where is IIIF going?
- IIIF Roadmap: Authorization / Authentication, Search within, Discovery of Manifest and Image Identifiers, CRUD
- How can we use IIIF to improve the services we offer at Cornell University Library?
- We can give better services for less effort by working with the IIIF infrastructure and tool suite. Three threads: Image access and viewers, Book readers, Flexible image re-use for commentary, discussion, exhibits
- Modified version of IA page turner now supports IIIF
- Significant enthusiasm for IIIF in the hydra community
- A few pointers, thanks for listening