

























ADV Slides: Building and Growing Organizational Analytics with Data Lakes
- 1. Building and Growing Organizational Analytics with Data Lakes Presented by: William McKnight “#1 Global Influencer in Data Warehousing” Onalytica President, McKnight Consulting Group An Inc. 5000 Company in 2018 and 2017 @williammcknight www.mcknightcg.com (214) 514-1444 Second Thursday of Every Month, at 2:00 ET #AdvAnalytics
- 2. William McKnight President, McKnight Consulting Group • Frequent keynote speaker and trainer internationally • Consulted to Pfizer, Scotiabank, Fidelity, TD Ameritrade, Teva Pharmaceuticals, Verizon, and many other Global 1000 companies • Hundreds of articles, blogs, benchmarks and white papers in publication • Focused on delivering business value and solving business problems utilizing proven, streamlined approaches to information management • Former Database Engineer, Fortune 50 Information Technology executive and Ernst&Young Entrepreneur of Year Finalist • Owner/consultant: 2018 & 2017 Inc. 5000 Data Strategy and Implementation consulting firm • Brings 25+ years of information management and DBMS experience
- 3. Implementation McKnight Consulting Group Offerings Strategy Training Strategy Trusted Advisor Action Plans Roadmaps Tool Selections Program Management Training Classes Workshops Implementation Data/Data Warehousing/Business Intelligence/Analytics Master Data Management Governance/Quality Big Data 3
- 5. Right-Fitting Analytic Platforms • The Enterprise Data Warehouse • A Dependent Data Mart • The Enterprise Data Lake • A Big Data Cluster • An Independent Data Mart 5
- 6. What Makes it a Data Lake? 6
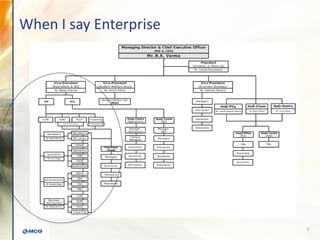
- 7. When I say Enterprise 7
- 8. HDFS vs Cloud Storage • Cloud Storage is more scalable and persistent • Cloud Storage is backed up and supports compression, making the cost of big data less • HDFS has better query performance • Cloud Storage has object size and single PUT limits that need workarounds 8
- 9. Leveraging Cloud Storage for Data Lakes • More Achievable separate compute and storage architecture • Compute resources (Map/Reduce, Hive, Spark, etc.) can be taken down, scaled up or out, or interchanged without data movement • Storage can be centralized, but compute can be distributed • Major players have mechanism to ensure consistency to achieve ACID-like compliance for remote data changes • Some vendors also have remote data replication to ensure redundancy and recovery • Most of the query execution is processing time, and not data transport, so if cloud compute and storage are in the same cloud vendor region, performance is hardly impacted 9
- 10. Data Lakes (Cloud Storage) vs Data Warehouses (RDBMS) Usually no pre-specified data model A Data Lake is great for history data A Data Lake easily accepts all data types Fewer users More exploration and discovery Lighter data governance Limitless big data
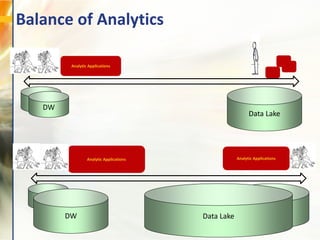
- 11. Balance of Analytics Analytic Applications DW Data Lake Analytic Applications DW Data Lake Analytic Applications DW Data Lake DW
- 12. The Builders Role 12 Data Warehouse Data Lake
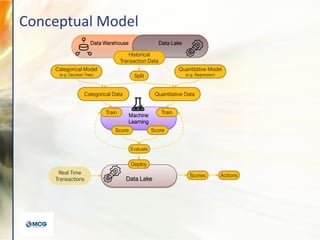
- 13. Data Lake Data Warehouse Data Lake Machine Learning Categorical Model (e.g. Decision Tree) Categorical Data Quantitative Data Split Quantitative Model (e.g. Regression) Train Train Score Score Evaluate Historical Transaction Data Deploy Scores Real Time Transactions Actions Conceptual Model
- 14. 14 Full Stack Comparison: Azure, AWS
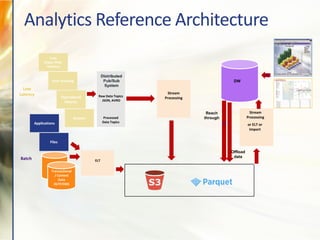
- 15. Analytics Reference Architecture Logs (Apps, Web, Devices) User tracking Operational Metrics Offload data Raw Data Topics JSON, AVRO Processed Data Topics Sensors Transactional / Context Data OLTP/ODS ELTBatch Low Latency Applications Files Reach through or ELT or Import Stream Processing Stream Processing Q Q DW
- 16. RDBMS MySQL, PostgreSQL … Cassandra, Key/Value DB Schema Enforce d ETL (Flattened, Modeled Tables) Hive, Spark, Presto, Notebooks Recent Data Applications: • ETL/Modelin g • CityOps • Machine Learning • Experiments Ad Hoc Analytics: • CityOps • Data Scientists Batch Low Latency Ingestion EL (Extract, Load) Visualization / Reporting / Application Distributed Pub/Sub System Data Sources Large- Scale Storage ETL – Extract, Transform, Load MPP Analytics / Machine Learning Example Architecture
- 17. Using the Data Lake
- 18. Data Governance for the Data Lake • Data stewardship coverage • Data catalog coverage • Less transformation • Nulls, blanks • Date formatting • Data ranges, patterns, outliers • Relationships • Business rules • Data classification • Confidence scores 18 Full Data Governance Data Lake Data Governance
- 19. 1 9 Smart Buildings Health / EMR Analytics Ride Share Customer Analytics Network Optimization Predictive Maintenance Route Optimization Wearable Analytics Smart Agriculture Software Optimization Clickstream Analytics Security Analysis Uses of the Data Lake Successful implementations right now across dozens of industries and use cases
- 20. Deploying the Data Lake
- 21. Data Lake Setup • Managed deployments in the Hadoop family of products • External tables in Hive metastore that point at cloud storage (Amazon S3, Google Cloud Storage, Azure Data Lake Storage Gen 2) – To run SQL against the data – HiveQL and Spark SQL require entries in the metastore 21
- 22. Object Storage Instances • Object Storage instances/clusters have local storage, i.e., on the physical drives mounted to the instances themselves, that is HDFS and Hive • Object Storage technologies access their cloud vendor’s respective cloud storage—viz.: – Amazon EMR accesses S3 – Dataproc accesses Google Cloud Storage – HDI accesses Azure Data Lake Storage Gen2 • Local storage is used by the Object Storage platform for housekeeping 22
- 23. The Data Lake of the Future • Pair a lake with an analytical engine that charges only by what you use • If you have a ton of data that can sit in cold storage and only needs to be accessed or analyzed occasionally, store it in Amazon S3/Azure Blob Storage/Google Cloud Storage – Use a database (on-premise or in the cloud) that can create external tables that point at the storage – Analysts can query directly against it, or draw down a subset for some deeper/intensive analysis – The GB/month storage fee plus data transfer/egress fees will be much cheaper than leaving it in a data warehouse 23
- 24. Sample Cluster Configuration Google BigQuery Cloud Provider Google Cloud Platform Version 3.6 Hadoop Version 2.7.3 Hive Version 1.2.1 Spark Version 2.3.2 Instance Type n1-highmem-16 Head/Master Nodes 1 Worker Nodes 16 and 32 vCPUs (per node) 16 RAM (per node) 104 GB Compute Cost (per node per hour) $0.947 Platform Premium (per node per hour) $0.160 24
- 25. Tips • If possible, configure remote data to be stored in parquet format, as opposed to comma-separated or other text format • As new data sources are added to cloud storage, use a code distribution system—like Github—to distribute new table definitions to distributed teams • Use data partitioning to improve performance—but don’t forget new partitions have to be declared to the Hive metastore when they are added to the data • Co-locate compute and storage in the same region • Use encryption on cloud storage bucket to ensure encryption at-rest • Drop commonly used data in the lake, like master data from MDM 25
- 26. The Data Science Lab Role of the Data Lake
- 27. All Data is AI Data • Call center recordings and chat logs • Streaming sensor data, historical maintenance records and search logs • Customer account data and purchase history • Email response metrics • Product catalogs and data sheets • Public references • YouTube video content audio tracks • User website behaviors • Sentiment analysis, user-generated content, social graph data, and other external data sources 27
- 28. Artificial Intelligence and Machine Learning • Looming on the horizon is an injection of AI/ML into every piece of software • Consider the domain of data integration – Predicting with high accuracy the steps ahead – Fixing its bugs • Machine learning is being built into databases so the data will be analyzed as it is loaded – I.e., Python with TensorFlow and Scala on Spark. • The split of the necessary AI/ML between the "edge" of corporate users and the software itself is still to be determined 28
- 29. Training Data for Machine Learning & Artificial Intelligence • You must have enough data to analyze to build models • Your data determines the depth of AI you can achieve -- for example, statistical modeling, machine learning, or deep learning -- and its accuracy 29
- 30. Building and Growing Organizational Analytics with Data Lakes Presented by: William McKnight “#1 Global Influencer in Data Warehousing” Onalytica President, McKnight Consulting Group An Inc. 5000 Company in 2018 and 2017 @williammcknight www.mcknightcg.com (214) 514-1444 Second Thursday of Every Month, at 2:00 ET #AdvAnalytics