



























Alpha zero - London 2018
- 1. From Alpha Go to Alpha Zero Google London March 2018
- 2. Juantomás García • Data Solutions Manager @ OpenSistemas • GDE (Google Developer Expert) for cloud Others • Co-Author of the first Spanish free software book “La Pastilla Roja” • President of Hispalinux (Spanish Linux User Group) • Organizer of the Machine Learning Spain and GDG Cloud Madrid. Who I am
- 3. • People interested in Machine Learning • Wants to know more about what’s is Alpha Go • With a good technical background. Who are the Audience
- 4. • I love Machine Learning. • There are a lot of takeaways from this project. • I wish to divulge it Why I did this presentation
- 5. • Alpha Go: the epic project • AlphaGo Zero: re-evolution version • Alpha Zero: Looking for general solutions • DIY: Alpha Zero Connect 4 • Takeaways Outline
- 6. A brief introduction • Deep Blue was about brute force • They were emulating how humans play chess
- 7. A brief introduction • A very huge Search Space Chess -> Opening 20 possible moves Go -> Opening 361 possible moves
- 8. Alpha Go Main Concepts • Policy Neural Network “To decide which are the most sensible moves in a particular board position”.
- 9. Alpha Go Main Concepts • Value Neural Network “How great is a particular board arrangements”. “How likely you are to win the game with this position”.
- 10. Alpha Go Main Concepts
- 11. Alpha Go First Approach: SL • Just train both networks using human games. • Just old and ordinary supervised learning. • With this: AlphaGo just play with like a weak human. • It like the approach of deep blue: just emulating human chess players
- 12. Alpha Go First Approach: SL
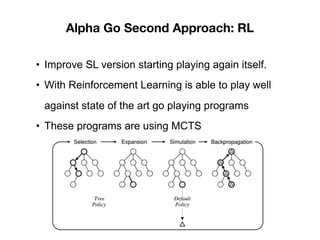
- 13. Alpha Go Second Approach: RL • Improve SL version starting playing again itself. • With Reinforcement Learning is able to play well against state of the art go playing programs • These programs are using MCTS
- 14. Alpha Go Second Approach: RL
- 15. Alpha Go Second Approach: RL • It is not 2 NN vs Monte Carlo Tree Search • Is a better MCTS thanks to the NNs.
- 16. Alpha Go Second Approach: RL • Optimal Value Function V*(s) “Determine the outcome of the game from every board position (s is the state)”. Brute force solution is impossible: Chess: 35 ** 80 Go: 250 ** 150
- 17. Alpha Go Second Approach: RL • Two solutions for reduce the effective search space: Truncate the tree subtree search: V(s) like V*(s) Reducing the breadth of the search with the policy: P(a|s) We MCTS rollout the moves choose by the policy function and evaluate with the optimal value function.
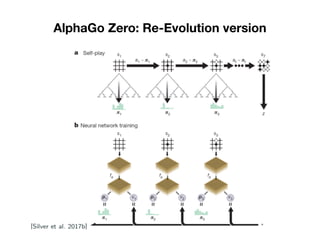
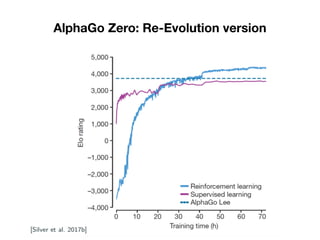
- 19. AlphaGo Zero: Re-Evolution version • Just trained with Reinforcement Learning • Choose the less out different moves: u(s,a) • Just one neural network for policy and value. • Every time a search is done the neural network is retrained.
- 20. AlphaGo Zero: Re-Evolution version • Human games was noisy and not reliable. • Don’t use rollouts for predict who will win.
- 21. AlphaGo Zero: Re-Evolution version
- 22. AlphaGo Zero: Re-Evolution version
- 23. Alpha Zero: New Challenges AlphaGo Zero VS AlphaZero: • Binary outcome (win / loss) × expected outcome (including • 3 draws or potentially other outcomes) • Board positions transformed before passing to neural networks (by randomly selected rotation or redirection) × no data augmentation • Games generated by the best player from previous iterations (margin of 55 %) × continual update using the latest parameters (without the evaluation and selection steps) • Hyper-parameters tuned by Bayesian optimisation × reused the same hyper-parameters without game-specific tuning
- 24. Alpha Zero
- 26. Takeaways RL is more than Atari Games and GO
- 27. Takeaways AI discovery new ways to play. Think about new projects like proteins fold.
- 28. Takeaways We’re living awesome times. Sharing AI papers, tools, models, etc. More than any time before.
- 29. Takeaways As Ms Fei Fei said: “It’s about democratizing AI”
- 30. Takeaways Watch this Documentary Film about Alpha Go:
- 31. Thank You