



















Amazon Product Sentiment review
- 1. Amazon Product Review Sentiment Analysis Lalit Jain: https://www.linkedin.com/in/lalit7jain Big Data Systems & Analytics
- 2. Agenda 1. Case Study 2. Scraping reviews 3. Sentiment analysis 4. Classification using Doc2Vec (Logistic, SGD, SVM) 5. Challenges
- 3. Case Study • Scrape the reviews of any website and perform sentiment analysis on the corpus • Using sentiment analysis result, once the document is classified appropriately use it to perform classification algorithm using doc2vec approach (SVM/ Deep Belief Network)
- 4. Scraping Reviews Programming Language used: R Libraries required: Rvest, dplyr, tm, quanteda, etc Approach: 1. From the main page of the product, navigate automatically to the review page 2. Loop through required number of pages to get the number of reviews required with an average of 10 reviews per page 3. Reviews need to be saved in the disk directly to save read only memory and take advantage of hard disk capacity Note: Both the “page link” and the “number of pages” can be passed as an argument callable to the script
- 5. Results
- 6. Corpus Operations Loading the documents using quanteda package Quanteda will create Document Frequency Matrix by function dfm(). This function essentially does this by series of operation including tokenizing, lowercasing, indexing, stemming, matching with dictionary Hu and Liu’s lexicon Using list of positive and negative words (dictionary) available from Hu and Liu’s lexicon with more than 6700+ words All operations in one line!
- 7. Result
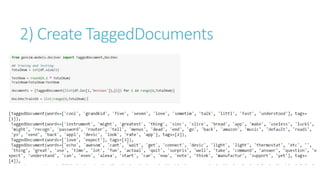
- 9. Classification Programming Language used: Python Libraries required: gensim, nltk, sklearn, etc. Approach: 1. Load the raw reviews and apply cleaning using nltk package (stop words, stemming, numbers,etc) 2. Create TaggedDocuments required for building Doc2Vev models (both DM and DBOW) 3. Train both the model 10 times with random shuffling of the documents 4. Split the dataset and apply classification algorithms
- 10. 1) Cleaning the loaded documents
- 12. DM and DBOW models dbow (distributed bag of words) It is a simpler model that ignores word order and training stage is quicker. The model uses no-local context/neighboring words in predictions dm (distributed memory) We treat the paragraph as an extra word. Then it is concatenated/averaged with local context word vectors when making predictions. During training, both paragraph and word embeddings are updated. It calls for more computation and complexity.
- 13. 3) Training the model
- 14. Checking the arrangements of Word vectors by both models
- 15. 4) Applying Classification Algorithm Testing Training
- 16. 4) Applying Classification Algorithm Testing Training
- 17. 4) Applying Classification Algorithm Testing Training
- 18. Deep Belief Network Trained only on 3000 documents Hyper parameters selected after 52 different combinations In terms of learn_rates, decays, epochs and hidden units Accuracy achieved of 89%
- 19. Conclusion Deep Belief Network works well even with 3000 documents. SVM performs poorly irrespective of the kernel and other hyper parameter Best Model: Deep Belief Network
- 20. Challenges 1. Deep Belief Network does not work on Python 3 2. Need to setup Python 2.7.3 virtual environment 3. “nolearn” library compatibility issues 4. Python memory issues when working on large corpus. Does not work on CPU and needs a GPU powered machine