
















Apache con 2012 taking the guesswork out of your hadoop infrastructure
- 1. Taking the guesswork out of your Hadoop Infrastructure Steve Watt HP Hadoop Chief Technologist Paul Denzinger HP Hadoop Performance Lead © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 2. Agenda – Clearing up common misconceptions Web Scale Hadoop Origins Single Socket 1.8 GHz 4-8 GB RAM 2-4 Cores 1x 1GbE NIC (2-4) x 1 TB SATA Drives Commodity in 2012 Dual Socket 2+ GHz 24-48 GB RAM 4-6 Cores (2-4) x 1GbE NICs (4-14) x 2 TB SATA Drives The enterprise perspective is also different 2 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 3. You can quantify what is right for you Balancing Performance and Storage Capacity with Price $ PRICE STORAGE PERFORMANCE CAPACITY 3 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 4. “We’ve profiled our Hadoop applications so we know what type of infrastructure we need” Said no-one. Ever. © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 5. Profiling your Hadoop Cluster High Level Design goals Its pretty simple: 1) Instrument the Cluster 2) Run your workloads 3) Analyze the Numbers Don’t do paper exercises. Hadoop has a way of blowing all your hypothesis out of the water. Lets walk through a 10 TB TeraSort on Full 42u Rack: - 2 x HP DL360p (JobTracker and NameNode) - 18 x HP DL380p Hadoop Slaves (18 Maps, 12 Reducers) 64 GB RAM, Dual 6 core Intel 2.9 GHz, 2 x HP p420 Smart ArrayHewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. 5 © Copyright 2012 Controllers, 16 x 1TB SFF Disks, 4 x 1GbE Bonded NICs
- 6. Instrumenting the Cluster The key is to capture the data. Use whatever framework you’re comfortable with Analysis using the Linux SAR Tool - Outer Script starts SAR gathering scripts on each node. Then starts Hadoop Job. - SAR Scripts on each node gather I/O, CPU, Memory and Network Metrics for that node for the duration of the job. - Upon completion the SAR data is converted to CSV and loaded into MySQL so we can do ad-hoc analysis of the data. - Aggregations/Summations done via SQL. - Excel is used to generate charts. 6 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 7. Examples Performed for each node – results copied to repository node sadf csv files: ssh wkr01 sadf -d sar_test.dat -- -u > repos wkr01_cpu_util.csv ssh wkr01 sadf -d sar_test.dat -- -b > wkr01_io_rate.csv ssh wkr01 sadf -d sar_test.dat -- -n DEV > wkr01_net_dev.csv wkr01_cpu_util.csv wkr01_io_rate.csv ssh wkr02 sadf -d sar_test.dat -- -u > wkr01_net_dev.csv wkr02_cpu_util.csv ssh wkr02 sadf -d sar_test.dat -- -b > wkr02_io_rate.csv wkr02_cpu_util.csv File name is prefixed with node name (i.e., “wrknn”) ssh wkr02 sadf -d sar_test.dat -- -n DEV > wkr02_io_rate.csv wkr02_net_dev.csv wkr02_net_dev.csv 7 …Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. ©
- 8. I/O Subsystem Test Chart I/O Subsystem has only around 10% of Total Throughput Utilization RUN the DD Tests first to understand what the Read and Write throughput capabilities of your I/O Subsystem -X axis is time -Y axis is MB per second TeraSort for this server design is not I/O bound. 1.6 GB/s is upper bound, this is less than 10% utilized. 8 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 9. CPU Subsystem Test Chart CPU Utilization is High, I/O Wait is low – Where you want to be Each data point is taken every 30 seconds Y axis is percent utilization of CPUs X axis is timeline of the run CPU Utilization is captured by analyzing how busy each core is and creating an average IO Wait (1 of 10 other SAR CPU Metrics) measures percentage of time CPU is waiting on I/O 9 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
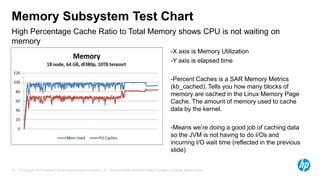
- 10. Memory Subsystem Test Chart High Percentage Cache Ratio to Total Memory shows CPU is not waiting on memory -X axis is Memory Utilization -Y axis is elapsed time -Percent Caches is a SAR Memory Metrics (kb_cached). Tells you how many blocks of memory are cached in the Linux Memory Page Cache. The amount of memory used to cache data by the kernel. -Means we’re doing a good job of caching data so the JVM is not having to do I/Os and incurring I/O wait time (reflected in the previous slide) 10 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 11. Network Subsystem Test Chart Network throughput utilization per server less than a ¼ of capacity A 1GbE NICs can drive up to 1Gb/s for Reads and 1Gb/s for Writes which is roughly 4 Gb/s or 400 MB/s total across all bonded NICs -Y axis is throughput -X axis is elapsed time Rx = Received MB/sec Tx = Transmitted MB/sec Tot = Total MB/sec 11 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 12. HBase Testing – Results still TBD YCSB Workload A and C unable to Drive the CPU CPU Utilization Network Usage 2 Workloads Tested: 100 300 - YCSB workload “C” : 100% read- Axis Title only requests, random access to MB/sec 200 50 100 DB, using a unique primary key %busy Tx MB/sec 0 - value %iowait Rx MB/sec 1 3 5 7 9 1 4 7 10131619 11 13 15 17 19 21 - YCSB workload “A” : 50% read and Minutes Minutes 50% updates, random access to DB, using a unique primary key value Disk Usage Memory Usage 300 100 -When data is cached in HBase MB/sec Axis Title 200 50 cache, performance is really good 100 0 %memused and we can occupy the CPU. Ops - Write MB/sec 1 5 8 throughput (and hence CPU 12 15 19 %cached 1 4 6 9 Read MB/sec 11 14 16 19 21 Utilization) dwindles when data Minutes Minutes exceeds HBase cache but is 12 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. available in Linux cache. Resolution TBD – Related JIRA HDFS-2246
- 13. Tuning from your Server Configuration baseline - We’ve established now that the Server Configuration we used works pretty well. But what if you want to Tune it? i.e. sacrifice some performance for cost or to remove an I/O, Network or Memory limitation? -Type (Socket R 130 W vs. -Types of Disks / Socket B 95 W) Controllers -Amount of Cores -Number of Disks / -Amount of Memory Channe Controllers - 4GB vs. 8GB DIMMS I/O SUBSYSTEM COMPUTE -Floor Space (Rack Density) - Power and - Type of Network Cooling Constraints - Amount of Server of DATA CENTER NETWORK NICs - Switch Port Availability - Deep Buffering 13 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 14. Balanced Hadoop Master and Slave Configurations NameNode and JobTracker Configurations - 1u, 64GB of RAM, 2 x 2.9 GHz 6 Core Intel Socket R Processors, 4 Small Form Factor Disks, RAID Configuration, 1 Disk Controller Hadoop Slave Configurations - 2u 48 GB of RAM, 2 x 2.4 GHz 6 Core Intel Socket B Processors, 1 High Performing Disk Controller with twelve 2TB Large Form Factor Data Disks in JBOD Configuration - 24 TB of Storage Capacity, Low Power Consumption CPU – Tpapi (Flickr) - Annual Power and Cooling Costs of a Cluster are 1/3 the cost of acquiring the cluster 14 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 15. Single Rack Config Single rack configuration 42u rack enclosure 1u 1GbE Switches 2 x 1GbE TOR switches This rack is the initial building block that 1u 2 Sockets, 4 Disks 1 x Management node configures all the key management services for a 2u 2 Sockets, 12 Disks 1 x JobTracker node production scale out cluster 1 x Name node to 4000 nodes. (3-18) x Worker nodes Open for KVM switch 2u 2 Sockets, 12 Disks Open 1u 15 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 16. Multi-Rack Config 1u Switches 2 x 10 GbE Aggregation switch Scale out configuration 1 or more 42u Racks The Extension building Single rack RA 1u 1GbE Switches 2 x 1GbE TOR switches block. One adds 1 or more racks of this block to the 2u 2 Sockets, 12 Disks 19 x Worker nodes single rack configuration to build out a cluster that Open for KVM switch scales to 4000 nodes. 2u 2 Sockets, 12 Disks Open 2u 16 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 17. System on a Chip and Hadoop Intel ATOM and ARM Processor Server Cartridges Hadoop has come full circle 4-8 GB RAM 4 Cores 1.8 GHz 2-4 TB 1 GbE NICs - Amazing Density Advances. 270 + servers in a Rack (compared to 21!). - Trevor Robinson from Calxeda is a member of our community working on this. He’d love some help: trevor.robinson@calxeda.com 17 © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
- 18. Thanks! Any Questions? Steve Watt swatt@hp.com @wattsteve Paul Denzinger paul.denzinger@hp.comzinger@hp.com S, Chief Technologist - Hadoop June 2012 hp.com/go/hadoop © Copyright 2012 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice.
Editor's Notes
- The average enterprise customers are running 1 or 2 Racks in Production. In that scenario, you have redundant switches in each RACK and you RAID Mirror the O/S and Hadoop Runtime and JBOD the Data Drives because losing Racks and Servers is costly. VERY Different to the Web Scale perspective.
- Hadoop Slave Server Configurations are about balancing the following: Performance (Keeping the CPU as busy as possible) Storage Capacity (Important for HDFS) Price (Managing the above at a price you can afford)Commodity Servers do not mean cheap. At scale you want to fully optimize performance and storage capacity for your workloads to keep costs down.
- So as any good Infrastructure Designer will tell you… you begin by Profiling your Hadoop Applications.
- But generally speaking, you design a pretty decent cluster infrastructure baseline that you can later optimize, provided you get these things right.
- In reality, you don’t want Hadoop Clusters popping up all over the place in your company. It becomes untenable to manage. You really want a single large cluster managed as a service.If that’s the case then you don’t want to be optimizing your cluster for just one workload, you want to be optimizing this for multiple concurrent workloads (dependent on scheduler) and have a balanced cluster.