Introduction to Apache ZooKeeper | Big Data Hadoop Spark Tutorial | CloudxLab
•
1 like•851 views

Big Data with Hadoop & Spark Training: http://bit.ly/2kvXlPd This CloudxLab Introduction to Apache ZooKeeper tutorial helps you to understand ZooKeeper in detail. Below are the topics covered in this tutorial: 1) Data Model 2) Znode Types 3) Persistent Znode 4) Sequential Znode 5) Architecture 6) Election & Majority Demo 7) Why Do We Need Majority? 8) Guarantees - Sequential consistency, Atomicity, Single system image, Durability, Timeliness 9) ZooKeeper APIs 10) Watches & Triggers 11) ACLs - Access Control Lists 12) Usecases 13) When Not to Use ZooKeeper
Report
Share

















































Introduction to Apache ZooKeeper | Big Data Hadoop Spark Tutorial | CloudxLab
- 2. ZooKeeper What is Race Condition?
- 3. ZooKeeper What is Race Condition? Bank Person A Person B
- 4. ZooKeeper What is a Deadlock?
- 5. ZooKeeper What is a Deadlock?
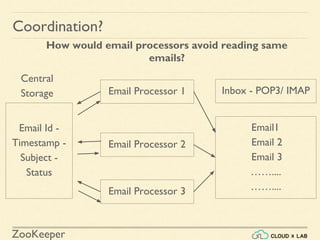
- 6. ZooKeeper Coordination? How would email processors avoid reading same emails? Email Processor 1 Email Processor 2 Email Processor 3 Email1 Email 2 Email 3 …….... …….... Inbox - POP3/ IMAP Email Id - Timestamp - Subject - Status Central Storage
- 7. ZooKeeper ZooKeeper Introduction A Distributed Coordination Service for Distributed Applications • Exposes a simple set of primitives • Very easy to program to • Uses a data model like directory tree
- 8. ZooKeeper ZooKeeper Introduction - Contd. A Distributed Coordination Service for Distributed Applications • Used for • Synchronisation • Locking • Maintaining configuration • Failover management • Coordination service that does not suffer from • Race conditions • Dead locks
- 9. ZooKeeper Data Model • Think of it as highly available file system • znode - can have data • JSON data • No append operation • Data access (read/write) is atomic - either full or error • znode - can have children • znodes form a hierarchical namespace
- 10. ZooKeeper Data Model - Contd. / /zoo /zoo/duck /zoo/goat /zoo/cow
- 11. ZooKeeper • Persistent • Ephemeral • Sequential Data Model - Znode - Types
- 12. ZooKeeper Data Model - Persistent Znode • Remains in ZooKeeper until deleted • create /mynode my_json_data
- 13. ZooKeeper Data Model - Ephemeral Znode • Deleted by Zookeeper as session ends or timeout • Though tied to client’s session but visible to everyone • Can not have children, not even ephemeral ones • create -e /apr9/myeph this-will-disappear
- 14. ZooKeeper Data Model - Sequential Znode • Creates a node with a sequence number in the name • The number is automatically appended create -s /zoo v Created /zoo0000000004 create -s /zoo/ v Created /zoo/0000000005 create -s /zoo/ v Created /zoo/0000000007 create -s /xyz v Created /xyz0000000006
- 15. ZooKeeper Architecture Runs in two modes • Standalone: • There is single server • For Testing • No High Availability • Replicated: • Run on a cluster of machines called an ensemble • Uses Paxos Algorithm • HA • Tolerates as long as majority
- 16. ZooKeeper • Phase 1: Leader election (Paxos Algorithm) • The machines elect a distinguished member - leader • The others are termed followers • This phase is finished when majority sync their state with leader • If leader fails, the remaining machines hold election within 200ms • If the majority is not available at any point of time, the leader steps down Ensemble Architecture
- 17. ZooKeeper Architecture - Phase 2 Client Leader Follower Follower Follower Follower Write Write Successful 3 out of 4 have saved
- 18. ZooKeeper • The protocol for achieving consensus is atomic like two-phase commit • Machines write to disk before in-memory Architecture - Phase 2 - Contd.
- 19. ZooKeeper If you have three nodes A, B, C with A as Leader. And A dies. Will someone become leader? A B C A B C Leader Election Demo ?
- 20. ZooKeeper If you have three nodes A, B, C with A as Leader. And A dies. Will someone become leader? A B C A B C Leader A B C Leader A B C OR Leader Election Demo
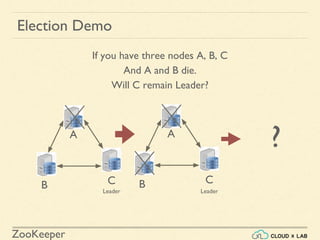
- 21. ZooKeeper If you have three nodes A, B, C with C as a leader And A and B die. Will C remain leader? A B C A B C Leader C will step down. No one will be the Leader as majority is not available. Majority Demo
- 22. ZooKeeper Imagine We have an ensemble spread over two data centres. A B C D E F Leader Data Center - 1 Data Center - II Why Do We Need Majority?
- 23. ZooKeeper Imagine The network between data centres got disconnected. If we did not need majority for electing Leader, what will happen? A B C D E F Leader Data Center - 1 Data Center - II Why Do We Need Majority?
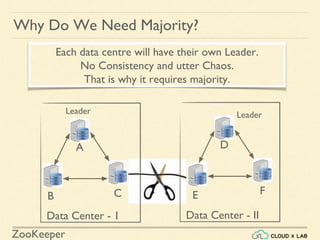
- 24. ZooKeeper A B C D E F Leader Data Center - 1 Data Center - II Leader Each data centre will have their own Leader. No Consistency and utter Chaos. That is why it requires majority. Why Do We Need Majority?
- 25. ZooKeeper Question An ensemble of 10 nodes can tolerate a shutdown of how many nodes? 4
- 26. ZooKeeper • A client has list of servers in the ensemble • It tries each until successful • Server creates a new session for the client • A session has a timeout period - decided by caller Sessions
- 27. ZooKeeper • If the server hasn’t received a request within the timeout period, it may expire the session • On session expiry, ephemeral nodes are deleted • To keep sessions alive client sends pings (heartbeats) • Client library takes care of heartbeats Sessions - Continued
- 28. ZooKeeper • Sessions are still valid on switching to another server • Failover is handled automatically by the client • Application can't remain agnostic of server reconnections - because the ops will fail during disconnection Sessions - Continued
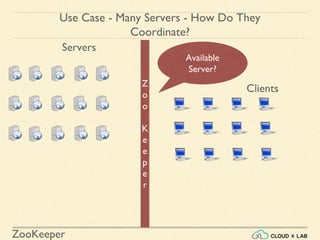
- 29. ZooKeeper Z o o K e e p e r Servers Available Server? Use Case - Many Servers - How Do They Coordinate? Clients
- 30. ZooKeeper create(“/servers/duck”, ephemeral node) create(“/servers/cow”, ephemeral node) ls /servers duck, cow ls /servers cow
- 31. ZooKeeper Sequential consistency Updates from any particular client are applied in the order Atomicity Updates either succeed or fail Single system image A client will see the same view of the system, The new server will not accept the connection until it has caught up Durability Once an update has succeeded, it will persist and will not be undone Timeliness Rather than allow a client to see very stale data, a server will shut down Guarantees
- 32. ZooKeeper OPERATION DESCRIPTION create Creates a znode (parent znode must exist) delete Deletes a znode (mustn’t have children) exists/ls Tests whether a znode exists & gets metadata getACL, setACL Gets/sets the ACL for a znode getChildren/ls Gets a list of the children of a znode getData/get, setData Gets/sets the data associated with a znode sync Synchronizes a client’s view of a znode with ZooKeeper
- 33. ZooKeeper • Batches together multiple operations together • Either all fail or succeed in entirety • Possible to implement transactions • Others never observe any inconsistent state Multi Update
- 34. ZooKeeper • Two core: Java & C • contrib: perl, python, REST • For each binding, sync and async available Sync: Async: APIs
- 35. ZooKeeper Watches • Watchers are triggered only once • For multiple notifications, re-register Clients to get notifications when a znode changes in some way
- 36. ZooKeeper Watch Triggers • The read ops exists, getChildren, getData may have watches • Watches are triggered by write ops: create, delete, setData • ACL operations do not participate in watches WATCH OF …ARE TRIGGERED WHEN ZNODE IS… exists created, deleted, or its data updated. getData deleted or has its data updated. getChildren deleted, or its any of the child is created or deleted
- 37. ZooKeeper ACLs - Access Control Lists Determines who can perform certain operations on it. • ACL is the combination • authentication scheme, • an identity for that scheme, • and a set of permissions • Authentication Scheme • digest - The client is authenticated by a username & password. • sasl - The client is authenticated using Kerberos. • ip - The client is authenticated by its IP address.
- 38. ZooKeeper Use Cases • Building a reliable configuration service • A Distributed lock service • Only single process may hold the lock
- 39. ZooKeeper When Not to Use? 1. To store big data because • The number of copies == number of nodes • All data is loaded in RAM too • Network load of transferring all data to all nodes 2. Extremely strong consistency
- 41. ZooKeeper Design Goals 1. Simple • A shared hierarchal namespace looks like standard file system • The namespace has data nodes - znodes (similar to files/dirs) • Data is kept in-memory • Achieve high throughput and low latency numbers. • High performance • Used in large, distributed systems • Highly available • No single point of failure • Strictly ordered access • Synchronisation
- 42. ZooKeeper 2. Replicated - HA The servers • Know each other • Keep in-memory image of State • Transaction Logs & Snapshots - persistent The client • Keeps a TCP connection • Gets watch events • Sends heart beats. • If connection breaks, • connect to different server. Design Goals
- 43. ZooKeeper 3. Ordered The number • Reflects the order of transactions. • used implement higher-level abstractions, such as synchronization primitives. ZooKeeper stamps each update with a number Design Goals
- 44. ZooKeeper 4. Fast Performs best where reads are more common than writes, at ratios of around 10:1. Design Goals At Yahoo!, where it was created, the throughput for a ZooKeeper cluster has been benchmarked at over 10,000 operations per second for write-dominant workloads generated by hundreds of clients
- 45. ZooKeeper r u ok? ruok Check server state. conf server configuration (from zoo.cfg). envi server environment, versions and other system properties. srvr statistics,znodes, mode (standalone, leader or follower). stat server statistics and connected clients srst Resets server statistics. isro is it in read-only (ro) mode? • Check connect to port 2181 • echo ruok | nc localhost 2181
- 46. ZooKeeper Connect(host, timeout, Watcher handle) okay. I will call you when needed. handle.process(WatchedEvent : Connected) create(“/servers/duck”, ephermal node); ls /servers duck,cow Duck Server Killed 5 seconds later ls /servers cow create(“/servers/cow”, ephermal node);
- 47. ZooKeeper States
- 48. ZooKeeper Election Demo If you have three nodes A, B, C And A and B die. Will C remain Leader? A B C A B C Leader ? Leader
- 49. ZooKeeper Coordination? How would Email Processors avoid reading same emails?
- 51. ZooKeeper Getting Started ● List the znodes at the top level: ls / ● List the children of a znode brokers: ls /brokers ● Get the details about the znode: get /brokers
- 52. ZooKeeper z o o k e e p e r Servers Which Server? Use Case - Many Servers - How Do They Coordinate? Can’t keep list on single node how to remove a failed server?
- 53. ZooKeeper Data Model - Continued • /a/./b != /a/b • /a/./b, /a/../b, /a//b is invalid
- 54. ZooKeeper • Phase 2: Atomic broadcast • All write requests are forwarded to the leader, • Leader broadcasts the update to the followers • When a majority have saved (persisted) the change: • The leader commits the update • The client gets success response Architecture