AWS June Webinar Series - Getting Started: Amazon Redshift

Amazon Redshift is a fast, fully-managed petabyte-scale data warehouse service, for less than $1,000 per TB per year. In this presentation, you'll get an overview of Amazon Redshift, including how Amazon Redshift uses columnar technology, optimized hardware, and massively parallel processing to deliver fast query performance on data sets ranging in size from hundreds of gigabytes to a petabyte or more. Learn how, with just a few clicks in the AWS Management Console, you can set up with a fully functional data warehouse, ready to accept data without learning any new languages and easily plugging in with the existing business intelligence tools and applications you use today. This webinar is ideal for anyone looking to gain deeper insight into their data, without the usual challenges of time, cost and effort. In this webinar, you will learn: • Understand what Amazon Redshift is and how it works • Create a data warehouse interactively through the AWS Management Console • Load some data into your new Amazon Redshift data warehouse from S3 Who Should Attend • IT professionals, developers, line-of-business managers

















































AWS June Webinar Series - Getting Started: Amazon Redshift
- 1. © 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Pavan Pothukuchi June 17, 2015 Amazon Redshift Getting Started
- 2. Introduction
- 3. Petabyte scale Massively parallel Relational data warehouse Fully managed; zero admin Amazon Redshift a lot faster a lot cheaper a whole lot simpler
- 5. Selected Amazon Redshift Customers
- 7. Benefits
- 8. Amazon Redshift Architecture Leader Node • SQL endpoint, JDBC/ODBC • Stores metadata • Coordinates query execution Compute Nodes • Local, columnar storage • Execute queries in parallel • Load, backup, restore via Amazon S3 • Load from Amazon DynamoDB or SSH Two hardware platforms • Optimized for data processing • DS2: HDD; scale from 2TB to 2PB • DC1: SSD; scale from 160GB to 326TB 10 GigE (HPC) Ingestion Backup Restore JDBC/ODBC
- 9. Amazon Redshift dramatically reduces I/O Column storage Data compression Zone maps Direct-attached storage Large data block sizes ID Age State Amoun t 123 20 CA 500 345 25 WA 250 678 40 FL 125 957 37 WA 375
- 10. Amazon Redshift dramatically reduces I/O Column storage Data compression Zone maps Direct-attached storage Large data block sizes ID Age State Amoun t 123 20 CA 500 345 25 WA 250 678 40 FL 125 957 37 WA 375
- 11. Amazon Redshift dramatically reduces I/O Column storage Data compression Zone maps Direct-attached storage Large data block sizes analyze compression listing; Table | Column | Encoding ---------+----------------+---------- listing | listid | delta listing | sellerid | delta32k listing | eventid | delta32k listing | dateid | bytedict listing | numtickets | bytedict listing | priceperticket | delta32k listing | totalprice | mostly32 listing | listtime | raw
- 12. Amazon Redshift dramatically reduces I/O Column storage Data compression Zone maps Direct-attached storage Large data block sizes • Track of the minimum and maximum value for each block • Skip over blocks that don’t contain the data needed for a given query • Minimize unnecessary I/O
- 13. Amazon Redshift dramatically reduces I/O Column storage Data compression Zone maps Direct-attached storage Large data block sizes • Use direct-attached storage to maximize throughput • Hardware optimized for high performance data processing • Large block sizes to make the most of each read • Amazon Redshift manages durability for you
- 14. Amazon Redshift Node Types • Optimized for I/O intensive workloads • High disk density • On demand at $0.85/hour • As low as $1,000/TB/Year • Scale from 2TB to 2PB DS2.XL: 31 GB RAM, 2 Cores 2 TB compressed storage, 0.5 GB/sec scan DS2.8XL: 244 GB RAM, 16 Cores 16 TB compressed, 4 GB/sec scan • High performance at smaller storage size • High compute and memory density • On demand at $0.25/hour • As low as $5,500/TB/Year • Scale from 160GB to 326TB DC1.L: 16 GB RAM, 2 Cores 160 GB compressed SSD storage DC1.8XL: 256 GB RAM, 32 Cores 2.56 TB of compressed SSD storage
- 15. Priced to let you analyze all your data Price is nodes times hourly cost No charge for leader node 3x data compression on avg Price includes 3 copies of data DS2 (HDD) Price Per Hour for DW1.XL Single Node Effective Annual Price per TB compressed On-Demand $ 0.850 $ 3,725 1 Year Reservation $ 0.500 $ 2,190 3 Year Reservation $ 0.228 $ 999 DC1 (SSD) Price Per Hour for DW2.L Single Node Effective Annual Price per TB compressed On-Demand $ 0.250 $ 13,690 1 Year Reservation $ 0.161 $ 8,795 3 Year Reservation $ 0.100 $ 5,500
- 16. Built-in Security • Load encrypted from S3 • SSL to secure data in transit; ECDHE perfect forward security • Encryption to secure data at rest • All blocks on disks & in Amazon S3 encrypted • Block key, Cluster key, Master key (AES-256) • On-premises HSM & CloudHSM support • Audit logging & AWS CloudTrail integration • Amazon VPC support • SOC 1/2/3, PCI-DSS Level 1, FedRAMP 10 GigE (HPC) Ingestion Backup Restore Customer VPC Internal VPC JDBC/ODBC
- 17. Durability and Availability – Managed Replication within the cluster and backup to Amazon S3 to maintain multiple copies of data at all times Backups to Amazon S3 are continuous, automatic, and incremental • Designed for eleven nines of durability Continuous monitoring and automated recovery from failures of drives and nodes Able to restore snapshots to any Availability Zone within a region Easily enable backups to a second region for disaster recovery
- 18. Use cases
- 19. Common Customer Use Cases Reduce costs by extending DW rather than adding HW Migrate completely from existing DW systems Respond faster to business Improve performance by an order of magnitude Make more data available for analysis Access business data via standard reporting tools Add analytic functionality to applications Scale DW capacity as demand grows Reduce HW & SW costs by an order of magnitude Traditional Enterprise DW Companies with Big Data SaaS Companies
- 20. • 10s of million ads/day • Stores 18 months of data • Analyzes ad opportunities, clicks and experiments • 250M mobile events/day • Stores 3 wk. granular and 4 yr. of aggregate data • Analyzes new feature usage and A/B testing
- 21. Create and Scale
- 24. Select Security Settings and Provision
- 25. Point and click resize
- 26. Resize • Resize while remaining online • Provision a new cluster in the background • Copy data in parallel from node to node • Only charged for source cluster
- 27. Load data
- 28. AWS CloudCorporate Data center Amazon S3 Amazon Redshift Flat files Data loading options
- 29. AWS CloudCorporate Data center ETL Source DBs Amazon Redshift Amazon Redshift Data loading options
- 31. Demo for loading data
- 32. Use the COPY command Each slice can load one file at a time A single input file means only one slice is ingesting data Instead of 100MB/s, you’re only getting 6.25MB/s Use multiple input files to maximize throughput
- 33. Use the COPY command You need at least as many input files as you have slices With 16 input files, all slices are working so you maximize throughput Get 100MB/s per node; scale linearly as you add nodes Use multiple input files to maximize throughput
- 34. Load lineorder table from single file copy lineorder from 's3://awssampledb/load/lo/lineorder-single.tbl' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=>key>' gzip compupdate off region 'us-east-1';
- 35. Load lineorder table from multiple files copy lineorder from 's3://awssampledb/load/lo/lineorder-multi.tbl' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=>key>' gzip compupdate off region 'us-east-1';
- 36. Query
- 37. JDBC/ODBC Amazon Redshift Amazon Redshift works with your existing analysis tools
- 42. Resources Pavan Pothukuchi | pavanpo@amazon.com | Detail Pages • http://aws.amazon.com/redshift • https://aws.amazon.com/marketplace/redshift/ Best Practices • http://docs.aws.amazon.com/redshift/latest/dg/c_loading-data-best-practices.html • http://docs.aws.amazon.com/redshift/latest/dg/c_designing-tables-best-practices.html • http://docs.aws.amazon.com/redshift/latest/dg/c-optimizing-query-performance.html Deep Dive Webinar Series in July • Migration and Loading Data • Optimizing Performance • Reporting and Advanced Analytics
- 43. AWS Summit – Chicago: An exciting, free cloud conference designed to educate and inform new customers about the AWS platform, best practices and new cloud services. Details • July 1, 2015 • Chicago, Illinois • @ McCormick Place Featuring • New product launches • 36+ sessions, labs, and bootcamps • Executive and partner networking Registration is now open • Come and see what AWS and the cloud can do for you. • Click here to register: http://amzn.to/1RooPPL
- 44. Pavan Pothukuchi – pavanpo@amazon.com
- 45. Load part table using key prefix copy part from 's3://pp-redshift-webinar-demo/load/part-csv.tbl' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=<key>;' csv null as '000';
- 46. Load supplier table using gzip copy supplier from 's3://awssampledb/ssbgz/supplier.tbl' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=<key>' delimiter '|' gzip region 'us-east-1';
- 47. Load customer table using a manifest file copy customer from 's3://pp-redshift-webinar-demo/load/customer-fw-manifest' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=<key>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10 acceptinvchars as '^' manifest;
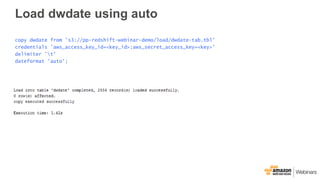
- 48. Load dwdate using auto copy dwdate from 's3://pp-redshift-webinar-demo/load/dwdate-tab.tbl' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=<key>' delimiter 't' dateformat 'auto';
- 49. Load lineorder table from single file copy lineorder from 's3://awssampledb/load/lo/lineorder-single.tbl' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=>key>' gzip compupdate off region 'us-east-1';
- 50. Load lineorder table from multiple files copy lineorder from 's3://awssampledb/load/lo/lineorder-multi.tbl' credentials 'aws_access_key_id=<key_id>;aws_secret_access_key=>key>' gzip compupdate off region 'us-east-1';