AWS re:Invent 2014 | (ARC202) Real-World Real-Time Analytics

Working with big volumes of data is a complicated task, but it's even harder if you have to do everything in real time and try to figure it all out yourself. This session will use practical examples to discuss architectural best practices and lessons learned when solving real-time social media analytics, sentiment analysis, and data visualization decision-making problems with AWS. Learn how you can leverage AWS services like Amazon RDS, AWS CloudFormation, Auto Scaling, Amazon S3, Amazon Glacier, and Amazon Elastic MapReduce to perform highly performant, reliable, real-time big data analytics while saving time, effort, and money. Gain insight from two years of real-time analytics successes and failures so you don't have to go down this path on your own.































AWS re:Invent 2014 | (ARC202) Real-World Real-Time Analytics
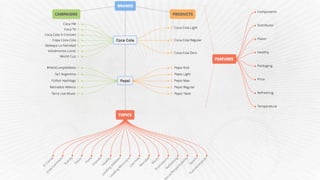
- 1. • SaaS Company – since 2008 • Social Media Analytics track and measure activity of brands and personality, providing information to market research & brand comparison • Multi Language Technology (English, Portuguese and Spanish) • Leader in Latin America, with operations in 5 countries, customers in LatAm and US • 1 out of 34 Twitter Certified Program Worldwide
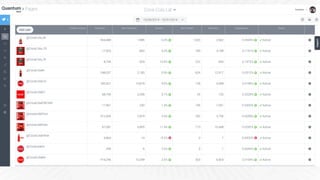
- 5. Ranking Brand 1 Brand 2 Brand 3 Q2 Q3 Q2 Q3 Q2 Q3 1° Flavor Breakfast Flavor Flavor Advertising Flavor 2° Healthy Flavor Packaging Brand I love Flavor Breakfast 3° Components Components Healthy Packaging Healthy Healthy 4° Advertising Healthy Components Addiction Components Advertising 5° Enquires Desire Prices Consumption Prices Components TOTAL 1.401 8.189 463 5.519 1.081 2.445 Share of Topics Which conversation my brand and my competitors are driving?
- 7. Challenges
- 8. Challenges: Variety • Different data sources • Different API • SLA • Method (Pull or Push) • Rate-Limit, Backoff strategy
- 9. Challenges: Velocity • Updates every second • Top users, top hashtags each minute • After event analysis are made with batch over complete dataset • Spikes of 20,000+ tweets per minute Last TV Debate Results Announced
- 10. Challenges: Meaning • Disambiguation • Data Enrichment – Demographics – Sentiment – Influencers • Human Analysis PAN Orange Telecom Oi Telecom Hi!
- 11. Challenges: Alert & Report • Clear & Understandable UI • Slice-dice for business (not BI experts) • Real-time Alerts for Anomalies
- 13. Drivers for Architecture Evolution • More customers, bigger customers • Add new features • Keep costs under control
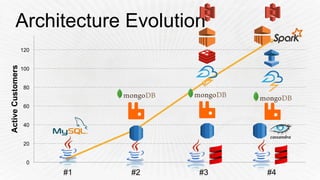
- 14. Architecture Evolution 0 20 40 60 80 100 120 #1 #2 #3 #4 ActiveCustomers
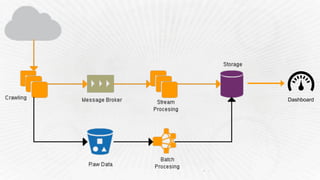
- 15. Architecture – 1st iteration What we needed: • Complete data isolation • Trying different solutions/offerings
- 16. Architecture – 1st iteration What we did: • All-in-one approach • Multi instance architecture • Simple vertical scalability • MySQL performance tunning
- 17. Architecture – 1st iteration What we've learned: • Multi-instance is harder to administrate, but minimize instability impact on customers • Vertical scalability: poor resource management • MySQL schema changes translates into downtime
- 18. Architecture – 2nd iteration What we needed: • Separation of Responsabilities (crawling, processing) • Horizontal Scalability • Fast Provisioning • Costs reduction
- 19. Architecture – 2nd iteration What we changed: • Migrated to AWS • RabbitMQ (Single Node) • Replace MySQL for RDS • Cloud Formation • Auto Scaling Groups
- 20. Architecture – 2nd iteration What we've learned: • PIOPs à • Tuning the auto scaling policies can be hard • Cloud Formation: great for migration, not enough for daily ops
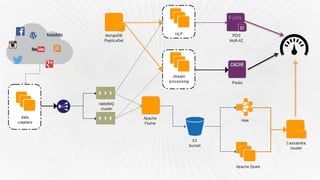
- 21. Architecture – 3rd iteration What we needed: • Deliver new features (NRT, more complex analytics) • Scale Fast • Be resilient against failure • Adding and improving data-sources • Keep costs under control (always)
- 22. Architecture – 3rd iteration What we changed: • Apache Storm • RabbitMQ HA • EMR (Hadoop/Hive) • CloudFormation + Chef • Glacier + S3 lifecycles policies
- 23. Architecture – 3rd iteration What we've learned: • Spot instances + Reserved instances • Hive = SQL à SQL scripts are hard to test • Bulk upserts on RDS can be expensive (PIOPS) • DynamoDB is great, but expensive (for our use-case)
- 24. Dashboard
- 25. Architecture – 4th iteration What we needed: • Monitor millions of social media profiles • Make data accessible (exploration, PoC) • Improve UI response times • Testing our data pipelines • Reprocessing (faster)
- 26. Architecture – 4th iteration What we changed: • Cassandra (DSE) • MongoDB MMS • Apache Spark
- 27. What we've learned: • Leverage on AWS ecosystem • Datastax AMI + Opscenter integration • MongoDB MMS: automation magic! • Apache Spark unit testing + ec2 launch scripts • EMR doesn’t have the latest stable versions Architecture – 4th iteration
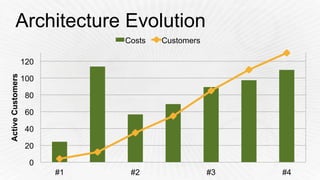
- 29. Architecture Evolution - 20 40 60 80 100 120 140 160 0 20 40 60 80 100 120 #1 #2 #3 #4 ActiveCustomers Costs Customers
- 30. Lessons Learned
- 31. Lessons Learned • Automate since day 1 (cloudformation + chef) • Monitor systems activity, understand your data patterns. eg: LogStash (ELK) • Always have a Source of Truth (S3 + Glacier) • Make your Source of Truth Searchable
- 32. Lessons Learned (II) • Approximation is a good thing: HLL, CMS, Bloom • Write your pipelines considering reprocessing needs • Avoid at all costs framework explosion • AWS ecosystem allows rapid prototype
- 34. Architecture Evolution 0 20 40 60 80 100 120 #1 #2 #3 #4 ActiveCustomers
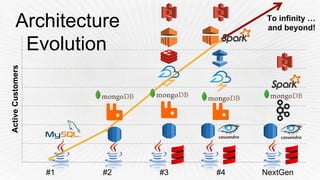
- 35. Architecture NextGen • Reduce moving parts • Apache Spark as central processing framework – Realtime (Micro-batch) – Batch-processing • Kafka (Message Broker) • Cassandra (Time-series storage) • ElasticSearch (Content Indexer)
- 36. To infinity … and beyond!Architecture Evolution 0 20 40 60 80 100 120 #1 #2 #3 #4 NextGen ActiveCustomers
- 37. Gustavo Arjones, CTO @arjones | gustavo@socialmetrix.com Sebastian Montini, Solutions Architect @sebamontini | sebastian@socialmetrix.com Let’s talk at Venetian-Titian Hallway Feedback and Q&A
- 38. Please give us your feedback on this presentation © 2014 Amazon.com, Inc. and its affiliates. All rights reserved. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon.com, Inc. Join the conversation on Twitter with #reinvent ARC202 Thank you!