Azure Lowlands: An intro to Azure Data Lake
•Download as PPTX, PDF•
1 like•1,570 views

These are the slides for my talk "An intro to Azure Data Lake" at Azure Lowlands 2019. The session was held on Friday January 25th from 14:20 - 15:05 in room Santander.
Report
Share










































Azure Lowlands: An intro to Azure Data Lake
- 1. Thank you to our sponsors! Gold Sponsors Silver Sponsors Community Sponsors
- 2. An intro to Azure Data Lake Rick van den Bosch M +31 (0)6 52 34 89 30 r.van.den.bosch@betabit.nl
- 3. Calendar Data Lakes About Azure Data Lake Azure Data Lake Store - DEMO Azure Data Lake HDInsights - DEMO Azure Data Lake Analytics - DEMO Power BI - DEMO Resources
- 4. Rick van den Bosch Cloud Solutions Architect @rickvdbosch rickvandenbosch.net r.van.den.bosch@betabit.nl
- 5. Data Lakes
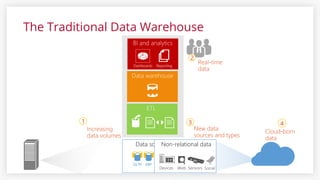
- 6. The Traditional Data Warehouse 6 Data sourcesNon-relational data
- 7. Ingest all data regardless of requirements Store all data in native format without schema definition Do analysis Hadoop, Spark, R, Azure Data Lake Analytics (ADLA) Interactive queries Batch queries Machine Learning Data warehouse Real-time analytics Devices Designed for the questions you don’t yet know! The Data Lake Approach
- 8. About Azure Data Lake 8
- 9. Azure Data Lake • Store and analyze petabyte-size files and trillions of objects • Develop massively parallel programs with simplicity • Debug and optimize your big data programs with ease • Enterprise-grade security, auditing, and support • Start in seconds, scale instantly, pay per job • Built on YARN, designed for the cloud 9
- 11. HDFS Compatible REST API ADL Store .NET, SQL, Python, R scaled out by U-SQL ADL Analytics Open Source Apache Hadoop ADL Client Azure DataBricks HDInsight Hive • Performance at scale • Optimized for analytics • Multiple analytics engines • Single repository sharing Why Azure Data Lake? an on-demand, real-time stream processing service with no-limits data lake built to support massively parallel analytics
- 12. Azure Data Lake Store
- 13. Store • Enterprise-wide hyper-scale repository • Data of any size, type and ingestion speed • Operational and exploratory analytics • WebHDFS-compatible API • Specifically designed to enable analytics • Tuned for (data analytics scenario) performance • Out of the box: security, manageability, scalability, reliability, and availability 15
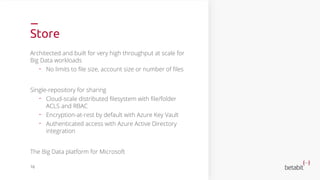
- 14. Store Architected and built for very high throughput at scale for Big Data workloads - No limits to file size, account size or number of files Single-repository for sharing - Cloud-scale distributed filesystem with file/folder ACLS and RBAC - Encryption-at-rest by default with Azure Key Vault - Authenticated access with Azure Active Directory integration The Big Data platform for Microsoft 16
- 15. Key capabilities Built for Hadoop Unlimited storage, petabyte files Performance-tuned for big data analytics Enterprise-ready: Highly-available and secure All data
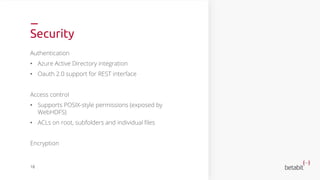
- 16. Security Authentication • Azure Active Directory integration • Oauth 2.0 support for REST interface Access control • Supports POSIX-style permissions (exposed by WebHDFS) • ACLs on root, subfolders and individual files Encryption 18
- 17. Compatibility 19
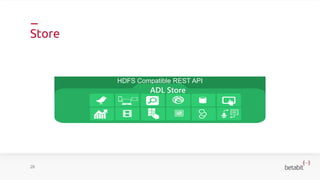
- 18. Store 20 HDFS Compatible REST API ADL Store
- 19. DEMO - Store 21
- 20. Ingest data – Ad hoc Local computer • Azure Portal • Azure PowerShell • Azure CLI • Using Data Lake Tools for Visual Studio Azure Storage Blob • Azure Data Factory • AdlCopy tool • DistCp running on HDInsight cluster 22
- 21. Ingest data Streamed • Azure Stream Analytics • Azure HDInsight Storm • EventProcessorHost Relational • Apache Sqoop • Azure Data Factory 23 Web server Upload using custom applications • Azure CLI • Azure PowerShell • Azure Data Lake Storage Gen1 .NET SDK • Azure Data Factory
- 22. Ingest data 24
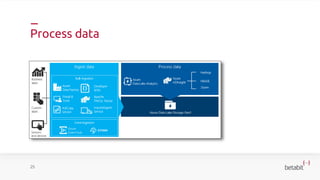
- 23. Process data 25
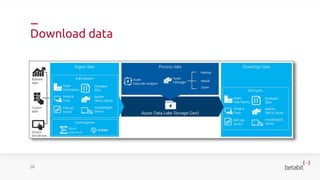
- 24. Download data 26
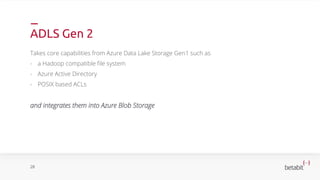
- 26. ADLS Gen 2 Takes core capabilities from Azure Data Lake Storage Gen1 such as - a Hadoop compatible file system - Azure Active Directory - POSIX based ACLs and integrates them into Azure Blob Storage 28
- 27. Additional benefits Unlimited scale and performance Performance improvements reading/writing individual objects (> throughput & concurrency) Removes need to decide a priority: run analytics or not at data ingestion time Data protection capabilities: encryption at rest Integrated network Firewall capabilities Durability options (Zone and Geo-Redundant Storage: high-availability and disaster recovery) Linux integration – BlobFUSE - mount Blob Storage from Linux VMs - interact using standard Linux shell commands. 29
- 28. Data Lake Storage Gen2 “In Data Lake Storage Gen2, all the qualities of object storage remain while adding the advantages of a file system interface optimized for analytics workloads.” 30
- 29. Known issues Blob Storage APIs and Azure Data Lake Gen2 APIs aren't interoperable Blob storage APIs not available Azure Storage Explorer >= 1.6.0 AZCopy >= v10 Event Grid doesn't receive events Soft Delete and Snapshots not available Object level storage tiers not available Diagnostic logs not available 31
- 30. Azure Data Lake HDInsight
- 31. HDInsight Cloud distribution of the (Hortonworks) Hadoop components Supports multiple Hadoop cluster versions (can be deployed any time) Hadoop • YARN for job scheduling & resource management • MapReduce for parallel processing • HDFS 33
- 33. HDInsight 35 Open Source Apache Hadoop ADL Client Azure DataBricks HDInsight Hive
- 35. Azure Data Lake Analytics
- 36. Analytics Dynamic scaling Develop faster, debug and optimize smarter using familiar tools U-SQL: simple and familiar, powerful, and extensible Integrates seamlessly with your IT investments Affordable and cost effective Works with all your Azure data 38
- 37. Analytics On-demand analytics job service to simplify big data analytics Can handle jobs of any scale instantly Azure Active Directory integration U-SQL 39
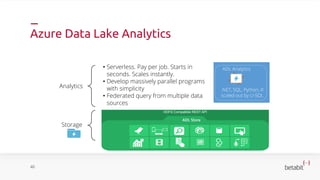
- 38. Azure Data Lake Analytics 40 Analytics Storage HDFS Compatible REST API ADL Store .NET, SQL, Python, R scaled out by U-SQL ADL Analytics• Serverless. Pay per job. Starts in seconds. Scales instantly. • Develop massively parallel programs with simplicity • Federated query from multiple data sources
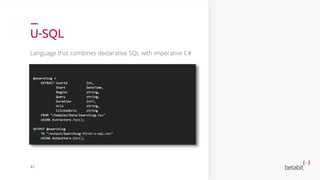
- 39. U-SQL Language that combines declarative SQL with imperative C# 41
- 40. U-SQL – Key concepts Rowset variables • Each query expression that produces a rowset can be assigned to a variable. EXTRACT • Reads data from a file & defines the schema on read * OUTPUT • Writes data from a rowset to a file * 42
- 41. U-SQL – Scalar variables DECLARE @in string = "/Samples/Data/SearchLog.tsv"; DECLARE @out string = "/output/SearchLog-scalar-variables.csv"; @searchlog = EXTRACT UserId int, ClickedUrls string FROM @in USING Extractors.Tsv(); OUTPUT @searchlog TO @out USING Outputters.Csv(); 43
- 42. U-SQL – Transform rowsets @searchlog = EXTRACT UserId int, Region string FROM "/Samples/Data/SearchLog.tsv" USING Extractors.Tsv(); @rs1 = SELECT UserId, Region FROM @searchlog WHERE Region == "en-gb"; OUTPUT @rs1 TO "/output/SearchLog-transform-rowsets.csv" USING Outputters.Csv(); 44
- 43. U-SQL – Extractor parameters delimiter encoding escapeCharacter nullEscape quoting rowDelimiter silent skipFirstNRows charFormat
- 44. U-SQL – Outputter parameters delimiter dateTimeFormat encoding escapeCharacter nullEscape quoting rowDelimeter charFormat outputHeader
- 45. U-SQL Built-in extractors and outputters: Text Csv Tsv A (for instance) CSV Extractor or Outputter is EXACTLY THAT
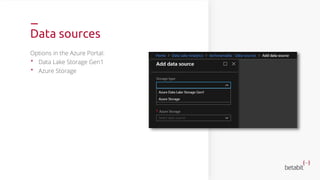
- 46. Data sources Options in the Azure Portal: • Data Lake Storage Gen1 • Azure Storage
- 48. DEMO - Power BI
- 49. Resources
- 50. Resources Basic example Advanced example Create Database (U-SQL) & Create Data Source (U-SQL) This example HDInsight quickstart Azure blog Azure roadmap
- 51. Bedankt voor je aandacht
- 52. Track 1 15:35 – 16:20 Skynet Is Talking - Microsoft Bot Framework Kris van der Mast Track 2 15:35 – 16:20 Enter The Matrix: Securing Azure's Assets Mike Martin
Editor's Notes
- WebHDFS means Hadoop & HDInsight compatibility
- Apache Hadoop file system compatible with Hadoop Distributed File System (HDFS) and works with the Hadoop ecosystem It does not impose any limits on account sizes, file sizes, or the amount of data that can be stored in a data lake. Data is stored durably by making multiple copies and there is no limit on the duration of time The data lake spreads parts of a file over a number of individual storage servers. This improves the read throughput when reading the file in parallel for performing data analytics. Redundant copies, enterprise-grade security for the stored data Data in native format, loading data doesn’t require a schema, structured, semi-structured, and unstructured data
- including multi-factor authentication, conditional access, role-based access control, application usage monitoring, security monitoring and alerting, etc. Do not enable encryption. Use keys managed by Data Lake Storage Gen1 Use keys from your own Key Vault.
- You can use Azure HDInsight and Azure Data Lake Analytics to run data analysis jobs on the data stored in Data Lake Storage Gen1.
- Apache Sqoop, Azure Data Factory, Apache DistCp Custom script / application Azure CLI, Azure PowerShell, Azure Data Lake Storage Gen1 .NET SDK
- Because Azure Data Lake Storage Gen2 is integrated into the Azure Storage platform, applications can use either the BLOB APIs or Azure Data Lake Storage Gen2 file system APIs for accessing data. BLOB APIs allow you to leverage your existing investments in BLOB Storage and continue to take advantage of the large ecosystem of first and third party applications already available while the Azure Data Lake Storage Gen2 file system APIs are optimized for analytics engines like Hadoop and Spark.
- Storage Explorer in portal WILL NOT WORK, Blob Viewing Tool partial support