Big Data and Data Warehousing Together with Azure Synapse Analytics (SQLBits 2020)
•Download as PPTX, PDF•
1 like•782 views

SQLBits 2020 presentation on how you can build solutions based on the modern data warehouse pattern with Azure Synapse Spark and SQL including demos of Azure Synapse.
Report
Share



















Big Data and Data Warehousing Together with Azure Synapse Analytics (SQLBits 2020)
- 1. Big Data and Data Warehousing Together with Azure Synapse Analytics Michael Rys, Principal Program Manager Microsoft Azure Data @MikeDoesBigData
- 2. Agenda Modernize your big data workloads with the modern data warehouse pattern Capabilities of Azure Synapse Analytics Cost improvements with Azure Synapse Analytics Demo Summary & Call to Action
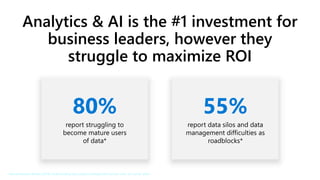
- 3. 80% 55% Analytics & AI is the #1 investment for business leaders, however they struggle to maximize ROI * Harvard Business Review (2019), Understanding why analytics strategies fall short for some, but not for others
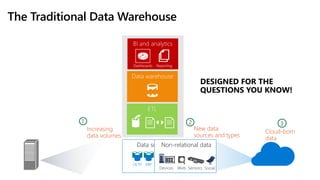
- 4. The Traditional Data Warehouse Data sourcesNon-relational data DESIGNED FOR THE QUESTIONS YOU KNOW!
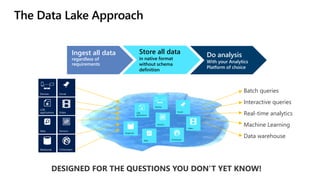
- 5. The Data Lake Approach Ingest all data regardless of requirements Store all data in native format without schema definition Do analysis With your Analytics Platform of choice Interactive queries Batch queries Machine Learning Data warehouse Real-time analytics Devices
- 6. Experimentation Fast exploration Semi-structured data Big Data & The Modern Data Warehouse Approach Proven security & privacy Dependable performance Operational data Relational Data Data Lake Data Warehouse
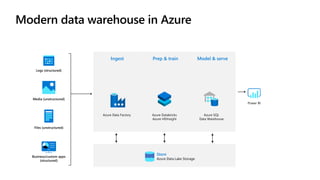
- 7. Modern data warehouse in Azure Logs (structured) Media (unstructured) Files (unstructured) Business/custom apps (structured) Ingest Prep & train Model & serve Store Azure Data Lake Storage Azure SQL Data Warehouse Azure Databricks Azure HDInsight Azure Data Factory Power BI
- 8. Modern data warehouse with Azure Synapse Analytics Logs (structured) Media (unstructured) Files (unstructured) Business/custom apps (structured) Azure Synapse Analytics Power BI Store Azure Data Lake Storage
- 9. Modern data warehouse with Azure Synapse Analytics Logs (structured) Media (unstructured) Files (unstructured) Business/custom apps (structured) Analytics runtimes SQL Common data estate Shared meta data Unified experience Synapse Studio Store Azure Data Lake Storage Power BI
- 10. At the core of all use cases is..Azure Synapse Analytics Real-time analytics Modern data warehousing Advanced analytics "We want to analyze data coming from multiple sources and in varied formats" "We want to leverage the analytics platform for advanced fraud detection" “We’re trying to get insights from our devices in real-time” Cloud-scale analytics
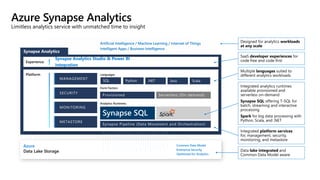
- 11. Azure Synapse Analytics Limitless analytics service with unmatched time to insight Platform Azure Data Lake Storage Common Data Model Enterprise Security Optimized for Analytics METASTORE SECURITY MANAGEMENT MONITORING Synapse Pipeline (Data Movement and Orchestration) Analytics Runtimes Provisioned Serverless (On-demand) Form Factors SQL Languages Python .NET Java Scala Experience Synapse Analytics Studio & Power BI integration Artificial Intelligence / Machine Learning / Internet of Things Intelligent Apps / Business Intelligence METASTORE SECURITY MANAGEMENT MONITORING
- 12. Azure Synapse Analytics • Workload Isolation (GA) • COPY Data Loading (GA) • Updatable Hash Key (GA) • Materialized View Improvement (GA) Public Preview • PREDICT Scoring • Bulk Load Wizard • Serverless Query Perf Enhancements • Pay-per-query consumption model • CSV Schema Inference • Access to Shared Spark Tables Private Preview • SQL MERGE support, DML Joins • Column Encryption • Multi-Column Hash Distribution Public Preview • Synapse Link HTAP for CosmosDB • OSS DeltaLake v0.6 • CDM Support • .NET for Apache Spark • Hyperspace Indexed Views • Share Tables with Synapse SQL • Built-in Samples • Template Code Gen for Notebooks Public Preview • Managed Virtual Networks • External Table Wizard • Increased Notebook Cell Features • SQL Pool Monitoring and Management • Spark Pool Monitoring and Management • Spark Job Graph Debugging • Statistical Sample Visualization of Data • More Granular Workspace RBAC Public Preview • Trusted Service for Azure Storage and Azure Key Vault (GA) • Managed Identity for Mapping Data Flows (GA) • Static IP ranges Azure Integration Runtime (GA) • Checkpoint and resume for binary file copy (GA) • Private Endpoint support via Managed Virtual Networks Private Preview • Data Flow CDM Support Query and analyze data with T-SQL using both provisioned and serverless models Quickly create notebooks with your choice of Python, Scala, SparkSQL, and .NET for Spark Build end-to-end workflows for your data movement and data processing scenarios Execute all data tasks with a simple UI and unified workspace environment Synapse SQL Apache Spark for Synapse Synapse Pipelines Synapse Studio
- 13. Synapse component cost benefits Existing tooling and skills No requirement for retraining or new tooling to work with familiar T-SQL environments .NET Support Reducing training costs for big data .NET developers Provisioned model • Workload Groups - maximize resource utilization • Materialized views and resultset cache – faster queries and smaller, cheaper clusters Apache Spark Synapse SQL Hyperspace materialized views • Faster queries • Requires smaller, cheaper clusters to achieve the same tasks Serverless model • Paying exactly for what you use - no overprovisioning • no clusters to monitor and manage - lower maintenance costs
- 14. Cost optimization with Azure Data Lake Storage Disaggregated compute and storage with shared metadata layer Lifecycle management for optimizing TCO Lower compute resources because of high performance
- 15. Azure Synapse and ADLS: Integration cost benefits Integrated workload monitoring Shared security Query Acceleration Shared metadata Single management portal Data stewards apply security policies only once Shared Managed Virtual Network Data owners define data model once only Faster Queries Smaller, cheaper clusters Reduced monitoring and diagnosis costs Lowers training costs
- 16. Synapse SQL - Serverless Shared Metadata Experience Spark Databases and Tables backed by Parquet become automatically available in: • Synapse SQL serverless • Synapse SQL provisioned as external tables of the same name. Spark Compute X Auto-Expose Metadata Objects CREATE DATABASE DBS1 CREATE SCHEMA $DBS1 CREATE DATABASE DBS1 CREATE TABLE DBS1.T1 CREATE EXTERNAL TABLE DBS1.dbo.T1 CREATE EXTERNAL TABLE $DBS1.T1 Auto-Expose Metadata Objects Benefits: • No need to run orchestration jobs to move data or meta data between computes • No duplication of data at the storage level SELECT * FROM DBS1.dbo.T1 SELECT * FROM DBS1.T1 SELECT * FROM $DBS1.T1 Synapse Hive Metastore Serverless SQL System Catalog Provisioned Synapse SQL DB Synapse SQL - Provisioned Instance (by Q4CY20)
- 17. Synapse integration with ADLS Query Acceleration Reduces total cost of ownership because analytics frameworks don’t need to parse and load as much data Delivers performance improvements due to less data transferred over network Optimize access to structured data by filtering data directly in the storage service Analytics queries typically require only ~20% of total data read Deeply integrated into Azure Synapse Analytics for improved performance and cost: • Spark Engine in Q4CY2020 • Synapse SQL in CY2021 AzureDataLakeStorage Query Acceleration 1 2 5 4 Data 3 Azure Synapse Analytics
- 18. Demo: Azure Synapse Analytics Analysis with interactive .NET for Spark Notebook Data prep with Spark Scala Twitter CSV files Seamless analysis with Synapse SQL What has Michael been up? Mentions Topics Who was interacting with Michael? Michael @MikeDoesBigData Using Query Acceleration Synapse Shared Meta Data
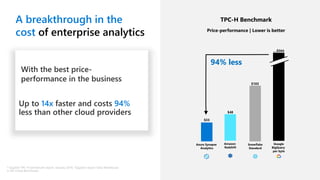
- 19. A breakthrough in the cost of enterprise analytics 94% less Up to 14x faster and costs 94% less than other cloud providers * GigaOm TPC-H benchmark report, January 2019, “GigaOm report: Data Warehouse in the Cloud Benchmark With the best price- performance in the business
- 20. A consistent version of data for everyone and all analytics use cases, but with zero management and maintenance, plus financially backed SLAs. Build end-to-end analytics solutions with a unified experience
- 21. Unlock powerful insights, get a multi- layered grasp of your business Integrated BI and machine learning drives insight for all users from the data scientist, coding with statistics, to the business user with Power BI.
- 22. We protect sensitive data in real time, monitoring and responding to threats as they arise, with industry-leading security and privacy features at no extra cost to you. Rigorous assurance of safe-keeping with the most advanced security and privacy features
- 23. Introducing Azure Synapse Analytics A limitless analytics service with unmatched time to insight, that delivers insights from all your data, across data warehouses and big data analytics systems, with blazing speed Simply put, Azure Synapse is Azure SQL Data Warehouse evolved We have taken the same industry leading data warehouse and elevated it to a whole new level of performance and capabilities Azure Synapse Analytics
- 24. Call to action Check out other SQLBits content: Big Data Processing with .NET and Spark by Michael Rys Introduce to Azure Data Lake Storage – https://aka.ms/adls Get started with Azure Synapse – https://aka.ms/azuresynapse Leverage Informatica + Microsoft - DW migration offer: https://aka.ms/SynapseInformaticaPOV Connect with me: Tweet me: @MikeDoesBigData - Tag with: #SQLBits #AzureSynapse Find slides also at https://www.slideshare.net/MichaelRys
- 25. © Copyright Microsoft Corporation. All rights reserved. Synapse SQL Apache Spark for Synapse Synapse Pipelines Synapse Studio Azure Synapse Analytics
Editor's Notes
- HBR Report: https://azure.microsoft.com/en-us/resources/why-analytics-strategies-fall-short-for-some-but-not-others/
- Pay for consumption model Compute elasticity Data evolves ‘in place’ within ubiquitous storage service
- Encapsulates the MDW pattern within the Synapse service Retain benefits of pay for consumption & ubiquitous store
- Unified experience leveraging heterogenous set of tools/frameworks Shared meta data service means that table definitions do not need to be restated as pipeline flows
- All the customers we spoke about in the slides before used cloud scale analytics to achieve their goals. For example, we have customers who leverage our Modern Data Warehouse track to ingest and analyze varied data sources or customers performing fraud detection analysis. While we talk of all these use cases and how customers are benefitting from them, notice at the core of all these use cases is the Azure Synapse Analytics.
- Spark - .NET for Spark is included by default SQL Serverless pay for use only – means no under-utilized clusters running No clusters == reduced maintenance costs Cost control features – caps for usage to avoid cost blowout Provisioned Workload groups provide query isolation with maximum utilization Workload – prioritize queries Materialized Views, Indexing, and Resultset cache are critically important for minimizing IO, less data read, less data cached, less data processed == smaller cheaper clusters
- Talk about the benefits of the tight integration between Synapse & ADLS: Reduced retraining costs due to use of familiar T-SQL environment & single pane of glass Only need to apply metadata once (metastore + access control) Accelerated IO integration with QA - improved performance == improved cost
- Analytics workloads require you to work with huge amounts of data. But the data typically used is 20% of the total data. So you end up processing more data than you should. With Query Acceleration for ADLS, the filtering is done on the storage layer itself, which helps save cost and improve performance. Query acceleration has been used a lot of customers and is generally available in all regions now.
- GigaOm benchmark: https://azure.microsoft.com/mediahandler/files/resourcefiles/data-warehouse-in-the-cloud-benchmark/FINAL%20data-warehouse-cloud-benchmark.pdf
- Same industry leading data warehouse: https://azure.microsoft.com/en-ca/blog/analytics-in-azure-is-up-to-14x-faster-and-costs-94-less-than-other-cloud-providers-why-go-anywhere-else/