Big data apache spark + scala
•
15 likes•1,405 views

This document provides an overview of Spark, including: - Spark was developed in 2009 at UC Berkeley and open sourced in 2010, with over 200 contributors. - Spark Core is the general execution engine that other Spark functionality is built on, providing in-memory computing and supporting various programming languages. - Spark Streaming allows data to be ingested from sources like Kafka and Flume and integrated with Spark for advanced analytics on streaming data.




















































Big data apache spark + scala
- 1. diciembre 2010 Spark & Scala juantomas@aspgems.com
- 3. Spark,the elevator pitch Developed in 2009 at UC BerkeleyAMPLab, open sourced in 2010, Spark has since become one of the largest OSS communities in big data, with over 200 contributors in 50+ organizations “Organizations that are looking at big data challenges – including collection, ETL, storage, exploration and analytics – should consider Spark for its in-memory performance and the breadth of its model.! It supports advanced analytics solutions on Hadoop clusters, including the iterative model required for machine learning and graph analysis.”! Gartner, Advanced Analytics and Data Science (2014) spark.apache.org 3
- 4. Spark, the elevator pitch 4
- 5. Spark,the elevator pitch circa 2010: a unified engine for enterprise data workflows, based on commodity hardware a decade later… Spark: Cluster Computing withWorking Sets! Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica people.csail.mit.edu/matei/papers/2010/hotcloud_spark.pdf! ! Resilient Distributed Datasets:A Fault-Tolerant Abstraction for! In-Memory Cluster Computing! Matei Zaharia, Mosharaf Chowdhury,Tathagata Das,Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica! usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf 5
- 6. Spark,the elevator pitch Spark Core is the general execution engine for the Spark platform that other functionality is built atop:! ! • • in-memory computing capabilities deliver speed! general execution model supports wide variety of use cases! ease of development – native APIs in Java, Scala, Python (+ SQL, Clojure, R)• 6
- 7. 7
- 8. Spark,the elevator pitch Sustained exponential growth, as one of the most active Apache projects ohloh.net/orgs/apache 8
- 10. TL;DR: Smashing The Previous Petabyte Sort Record databricks.com/blog/2014/11/05/spark-officially- sets-a-new-record-in-large-scale-sorting.html 9
- 19. ecause Machine Data! Why Streaming? B I <3 Logs Jay Kreps O’Reilly (2014)! shop.oreilly.com/product/ 0636920034339.do 11
- 20. Why Streaming? Because Google! MillWheel: Fault-Tolerant Stream Processing at Internet Scale! Tyler Akidau, Alex Balikov, Kaya Bekiroglu, Slava Chernyak, Josh Haberman, Reuven Lax, Sam McVeety, Daniel Mills, Paul Nordstrom, Sam Whittle! Very Large Data Bases (2013)! research.google.com/pubs/ pub41378.html 12
- 21. hy Streaming? Because IoT! kickstarter.com/projects/1614456084/b4rm4n- be-a-cocktail-hero W 13
- 22. hy Streaming? Because IoT! (exabytes/day per sensor) bits.blogs.nytimes.com/2013/06/19/g-e-makes-the- machine-and-then- uses-sensors-to-listen-to-it/ W 14
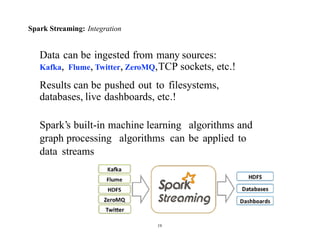
- 26. Spark Streaming: Integration Data can be ingested from many sources: Kafka, Flume, Twitter, ZeroMQ,TCP sockets, etc.! Results can be pushed out to filesystems, databases, live dashboards, etc.! Spark’s built-in machine learning algorithms and graph processing algorithms can be applied to data streams 19
- 27. 014! ! graduated (Spark 0.9) Spark Streaming: Timeline 2012! 2013! ! ! project started! alpha release (Spark 0.7)! project lead: Tathagata Das @tathadas 20 Discretized Streams:A Fault-Tolerant Model for Scalable Stream Processing! Matei Zaharia,Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, Ion Stoica! Berkeley EECS (2012-12-14)! www.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-259.pdf
- 28. Spark Streaming: Requirements Typical kinds of applications:! • • • • • datacenter operations! web app funnel metrics! ad optimization! anti-fraud! various telematics! and much much more! 21
- 29. Spark Streaming: Some Excellent Resources Programming Guide spark.apache.org/docs/latest/streaming- programming-guide.html! TD @ Spark Summit 2014 youtu.be/o-NXwFrNAWQ?list=PLTPXxbhUt- YWGNTaDj6HSjnHMxiTD1HCR! “Deep Dive into Spark Streaming” s l i d e s h a re . n e t / s p a r k - p ro j e c t / d e e p - divewithsparkstreaming- tathagatadassparkmeetup20130617! Spark Reference Applications databricks.gitbooks.io/databricks-spark- reference- applications/ 22
- 30. Quiz: name the bits and pieces… import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ // create val ssc = // create val lines a StreamingContext with a SparkConf configuration new StreamingContext(sparkConf, Seconds(10)) a DStream that will connect to serverIP:serverPort = ssc.socketTextStream(serverIP, serverPort) // split each line into words val words = lines.flatMap(_.split(" ")) // count each word in each batch! val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) // print a few of the counts to the console wordCounts.print() ssc.start() ssc.awaitTermination() 23
- 41. Spark Integrations: Insights cloud-based notebooks… ETL… the Hadoop ecosystem… widespread use of PyData… advanced analytics in streaming… rich custom search… web apps for data APIs… low-latency + multi-tenancy… 37 Discover Integrate With Many Other Systems Use Lots of Different Data Sources Run Sophisticated Analytics Clean Up Your Data
- 42. Spark Integrations: Advanced analytics for streaming use cases Kafka + Spark + Cassandra! datastax.com/documentation/datastax_enterprise/4.5/ datastax_enterprise/spark/sparkIntro.html! http://helenaedelson.com/?p=991! github.com/datastax/spark- cassandra-connector! github.com/dibbhatt/kafka-spark- consumer 38 columnar key-valuedata streams unified compute
- 43. Spark Integrations: Rich search, immediate insights Spark + ElasticSearch! databricks.com/blog/2014/06/27/application-spotlight- elasticsearch.html! elasticsearch.org/guide/en/elasticsearch/hadoop/current/ spark.html! spark-summit.org/2014/talk/streamlining-search- indexing-using- elastic-search-and-spark 39 document search unified compute
- 44. Spark Integrations: General Guidelines • • • use Tachyon as a best practice for sharing between two streaming apps! or write to Cassandra or HBase / then read back! design patterns for integration: spark.apache.org/ docs/latest/streaming- programming- guide.html#output- operations-on-dstreams 40
- 45. Examples 56
- 50. Resources 56
- 51. community: spark.apache.org/community.html video+slide archives: spark-summit.org events worldwide: goo.gl/2YqJZK resources: workshops: databricks.com/spark-training-resources databricks.com/spark-training 59
- 52. atei ZahariaO’Reilly (2015*) hop.oreilly.com/product/ 636920028512.do Holden Karau Packt (2013) shop.oreilly.com/product/ 9781782167068.do books: Learning Spark Holden Karau, Fast Data Processing with Spark Andy Konwinski, Spark in Action Chris Fregly Manning (2015*) sparkinaction.com/ 60
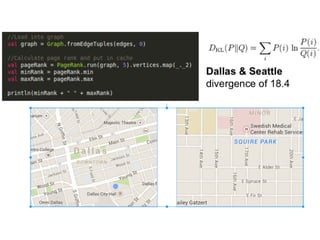
- 53. Paco Nathan ( @pacoid ) Spark Databricks Andy Petrella (@noootsab) Gerard Mass (@maasg) devoxx Los créditos de algunos de estos gráficos, tablas o logos son: