













































Building Streaming Applications with Apache Kafka
- 1. 1 Building Streaming Applications with Apache Kafka Cliff Gilmore
- 3. 3 The Vision Search NewSQL / NoSQL RDBMS Monitoring Document StoreReal-time Analytics Data Warehouse Mobile Apps Legacy Apps Hadoop Streaming Platform
- 4. 4 A Typical Architecture Today - What a Mess! Search Security Application User Tracking Operational Logs Operational Metrics Hadoop Data Warehouse MySQL Cassandra Oracle App Databases Storage Interfaces Monitoring App Databases Storage Interfaces
- 5. 5 A Typical Architecture Today - What a Mess! Search Security Application User Tracking Operational Logs Operational MetricsMySQL Cassandra Oracle Hadoop Streams API App Streams API Monitoring App Data Warehouse Apache Kafka
- 6. 6 Streaming Data vs Big Data Stream Data is The Faster the Better Stream Data can be Big or Fast (Lambda) Stream Data will be Big AND Fast (Kappa) Apache Kafka is the Enabling Technology of this Transition Big Data was The More the Better ValueofData Age of Data Speed Table Batch Table Database Streams Hadoop Job 1 Job 2 Streams Table 1 Table 2 Database ValueofData Volume of Data
- 7. 7 Kafka Architecture – Think of a Log!
- 10. 10 Simplifying Real Time Processing Streams API Your App Kafka Cluster Key Benefits of Apache Kafka’s Streams API • Build Apps, Not Clusters: no additional cluster required • Elastic, highly-performant, distributed, fault-tolerant, secure • Equally viable for small, medium, and large-scale use cases • “Run Everywhere”: integrates with your existing deployment strategies such as containers, automation, cloud Part of open source Apache Kafka, introduced in 0.10+ • Powerful client library to build stream processing apps • Apps are standard Java applications that run on client machines • https://github.com/apache/kafka/tree/trunk/streams
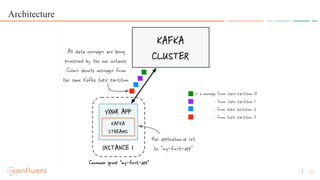
- 11. 11 Architecture
- 12. 12 Architecture
- 13. 13 • API option 1: Kafka Streams DSL (declarative) KStream<Integer, Integer> input = builder.stream("numbers-topic"); // Stateless computation KStream<Integer, Integer> doubled = input.mapValues(v -> v * 2); // Stateful computation KTable<Integer, Integer> sumOfOdds = input .filter((k,v) -> v % 2 != 0) .selectKey((k, v) -> 1) .groupByKey() .reduce((v1, v2) -> v1 + v2, "sum-of-odds"); The preferred API for most use cases. The DSL particularly appeals to users: • When familiar with Spark, Flink • When fans of Scala or functional programming
- 14. 14 • API option 2: Processor API (imperative) class PrintToConsoleProcessor implements Processor<K, V> { @Override public void init(ProcessorContext context) {} @Override void process(K key, V value) { System.out.println("Received record with " + "key=" + key + " and value=" + value); } @Override void punctuate(long timestamp) {} @Override void close() {} } Full flexibility but more manual work The Processor API appeals to users: • When familiar with Storm, Samza • Still, check out the DSL! • When requiring functionality that is not yet available in the DSL
- 15. 15 Motivating example: continuously compute current users per geo-region 4 7 5 3 2 8 Real-time dashboard “How many users younger than 30y, per region?” alice Asia, 25y, … bob Europe, 46y, … … … user-locations (mobile team) user-prefs (web team)
- 16. 16 Motivating example: continuously compute current users per geo-region 4 7 5 3 2 8 Real-time dashboard “How many users younger than 30y, per region?” alice Europe user-locations alice Asia, 25y, … bob Europe, 46y, … … … user-locations (mobile team) user-prefs (web team)
- 17. 17 Motivating example: continuously compute current users per geo-region 4 7 5 3 2 8 Real-time dashboard “How many users younger than 30y, per region?” alice Europe user-locations user-locations (mobile team) user-prefs (web team) alice Asia, 25y, … bob Europe, 46y, … … … alice Europe, 25y, … bob Europe, 46y, … … …
- 18. 18 Motivating example: continuously compute current users per geo-region 4 7 5 3 2 8 4 7 6 3 2 7 Alice Real-time dashboard “How many users younger than 30y, per region?” alice Europe user-locations alice Asia, 25y, … bob Europe, 46y, … … … alice Europe, 25y, … bob Europe, 46y, … … … -1 +1 user-locations (mobile team) user-prefs (web team)
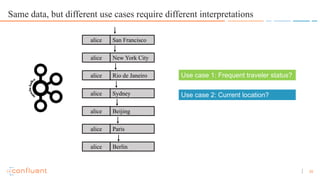
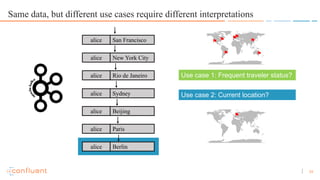
- 19. 19 Same data, but different use cases require different interpretations alice San Francisco alice New York City alice Rio de Janeiro alice Sydney alice Beijing alice Paris alice Berlin
- 20. 20 Same data, but different use cases require different interpretations alice San Francisco alice New York City alice Rio de Janeiro alice Sydney alice Beijing alice Paris alice Berlin Use case 1: Frequent traveler status? Use case 2: Current location?
- 21. 21 Same data, but different use cases require different interpretations “Alice has been to SFO, NYC, Rio, Sydney, Beijing, Paris, and finally Berlin.” “Alice is in SFO, NYC, Rio, Sydney, Beijing, Paris, Berlin right now.” ⚑ ⚑ ⚑⚑ ⚑ ⚑ ⚑ ⚑ ⚑ ⚑⚑ ⚑ ⚑ ⚑ Use case 1: Frequent traveler status? Use case 2: Current location?
- 22. 22 Same data, but different use cases require different interpretations alice San Francisco alice New York City alice Rio de Janeiro alice Sydney alice Beijing alice Paris alice Berlin Use case 1: Frequent traveler status? Use case 2: Current location? ⚑ ⚑ ⚑⚑ ⚑ ⚑⚑ ⚑
- 23. 23 Same data, but different use cases require different interpretations alice San Francisco alice New York City alice Rio de Janeiro alice Sydney alice Beijing alice Paris alice Berlin Use case 1: Frequent traveler status? Use case 2: Current location? ⚑ ⚑ ⚑⚑ ⚑ ⚑⚑ ⚑
- 24. 24 Same data, but different use cases require different interpretations alice San Francisco alice New York City alice Rio de Janeiro alice Sydney alice Beijing alice Paris alice Berlin Use case 1: Frequent traveler status? Use case 2: Current location? ⚑ ⚑ ⚑⚑ ⚑ ⚑⚑ ⚑
- 25. 25 Streams meet Tables record stream When you need… so that the topic is interpreted as a All the values of a key KStream then you’d read the Kafka topic into a Example All the places Alice has ever been to with messages interpreted as INSERT (append)
- 26. 26 Streams meet Tables record stream changelog stream When you need… so that the topic is interpreted as a All the values of a key Latest value of a key KStream KTable then you’d read the Kafka topic into a Example All the places Alice has ever been to Where Alice is right now with messages interpreted as INSERT (append) UPSERT (overwrite existing)
- 27. 27 Same data, but different use cases require different interpretations “Alice has been to SFO, NYC, Rio, Sydney, Beijing, Paris, and finally Berlin.” “Alice is in SFO, NYC, Rio, Sydney, Beijing, Paris, Berlin right now.” ⚑ ⚑ ⚑⚑ ⚑ ⚑ ⚑ ⚑ ⚑ ⚑⚑ ⚑ ⚑ ⚑ Use case 1: Frequent traveler status? Use case 2: Current location? KStream KTable
- 28. 28 Motivating example: continuously compute current users per geo-region 4 7 5 3 2 8 4 7 6 3 2 7 Alice Real-time dashboard “How many users younger than 30y, per region?” alice Europe user-locations alice Asia, 25y, … bob Europe, 46y, … … … alice Europe, 25y, … bob Europe, 46y, … … … -1 +1 user-locations (mobile team) user-prefs (web team)
- 29. 29 Motivating example: continuously compute current users per geo-region KTable<UserId, Location> userLocations = builder.table(“user-locations-topic”); KTable<UserId, Prefs> userPrefs = builder.table(“user-preferences-topic”);
- 30. 30 Motivating example: continuously compute current users per geo-region alice Europe user-locations alice Asia, 25y, … bob Europe, 46y, … … … alice Europe, 25y, … bob Europe, 46y, … … … KTable<UserId, Location> userLocations = builder.table(“user-locations-topic”); KTable<UserId, Prefs> userPrefs = builder.table(“user-preferences-topic”); // Merge into detailed user profiles (continuously updated) KTable<UserId, UserProfile> userProfiles = userLocations.join(userPrefs, (loc, prefs) -> new UserProfile(loc, prefs)); KTable userProfilesKTable userProfiles
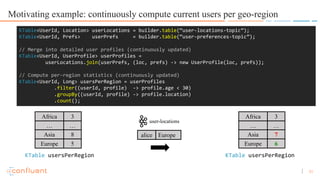
- 31. 31 Motivating example: continuously compute current users per geo-region KTable<UserId, Location> userLocations = builder.table(“user-locations-topic”); KTable<UserId, Prefs> userPrefs = builder.table(“user-preferences-topic”); // Merge into detailed user profiles (continuously updated) KTable<UserId, UserProfile> userProfiles = userLocations.join(userPrefs, (loc, prefs) -> new UserProfile(loc, prefs)); // Compute per-region statistics (continuously updated) KTable<UserId, Long> usersPerRegion = userProfiles .filter((userId, profile) -> profile.age < 30) .groupBy((userId, profile) -> profile.location) .count(); alice Europe user-locations Africa 3 … … Asia 8 Europe 5 Africa 3 … … Asia 7 Europe 6 KTable usersPerRegion KTable usersPerRegion
- 32. 32 Motivating example: continuously compute current users per geo-region 4 7 5 3 2 8 4 7 6 3 2 7 Alice Real-time dashboard “How many users younger than 30y, per region?” alice Europe user-locations alice Asia, 25y, … bob Europe, 46y, … … … alice Europe, 25y, … bob Europe, 46y, … … … -1 +1 user-locations (mobile team) user-prefs (web team)
- 33. 33 Streams meet Tables – in the Kafka Streams DSL
- 34. 34 KSQL
- 35. 35 KSQL from Confluent A Developer Preview of KSQL An Open Source Streaming SQL Engine for Apache KafkaTM
- 36. 36 KSQL: a Streaming SQL Engine for Apache Kafka™ from Confluent • Enables stream processing with zero coding required • The simplest way to process streams of data in real-time • Powered by Kafka: scalable, distributed, battle-tested • All you need is Kafka–No complex deployments of bespoke systems for stream processing Ksql>
- 37. 37 CREATE STREAM possible_fraud AS SELECT card_number, count(*) FROM authorization_attempts WINDOW TUMBLING (SIZE 5 SECONDS) GROUP BY card_number HAVING count(*) > 3; KSQL: the Simplest Way to Do Stream Processing
- 38. 38 KSQL Concepts ● STREAM and TABLE as first-class citizens ● Interpretations of topic content ● STREAM - data in motion ● TABLE - collected state of a stream • One record per key (per window) • Current values (compacted topic) ● STREAM – TABLE Joins
- 39. 39 KSQL Deployment Models – Local, or Client/Server
- 40. 40 Streaming ETL, powered by Apache Kafka and Confluent Platform KSQL
- 41. 41 KSQL in action ksql> CREATE stream rental (rental_id INT, rental_date INT, inventory_id INT, customer_id INT, return_date INT, staff_id INT, last_update INT ) WITH (kafka_topic = 'sakila-rental', value_format = 'json'); Message ---------------- Stream created * Command formatted for clarity here. Linebreaks need to be denoted by in KSQL
- 42. 42 KSQL in action ksql> describe rental; Field | Type -------------------------------- ROWTIME | BIGINT ROWKEY | VARCHAR(STRING) RENTAL_ID | INTEGER RENTAL_DATE | INTEGER INVENTORY_ID | INTEGER CUSTOMER_ID | INTEGER RETURN_DATE | INTEGER STAFF_ID | INTEGER LAST_UPDATE | INTEGER
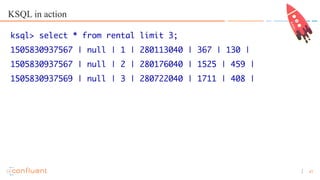
- 43. 43 KSQL in action ksql> select * from rental limit 3; 1505830937567 | null | 1 | 280113040 | 367 | 130 | 1505830937567 | null | 2 | 280176040 | 1525 | 459 | 1505830937569 | null | 3 | 280722040 | 1711 | 408 |
- 44. 44 KSQL in action SELECT rental_id , TIMESTAMPTOSTRING(rental_date, 'yyyy-MM-dd HH:mm:ss.SSS'), TIMESTAMPTOSTRING(return_date, 'yyyy-MM-dd HH:mm:ss.SSS') FROM rental limit 3; 1 | 2005-05-24 22:53:30.000 | 2005-05-26 22:04:30.000 2 | 2005-05-24 22:54:33.000 | 2005-05-28 19:40:33.000 3 | 2005-05-24 23:03:39.000 | 2005-06-01 22:12:39.000 LIMIT reached for the partition. Query terminated ksql>
- 45. 45 KSQL in action SELECT rental_id , TIMESTAMPTOSTRING(rental_date, 'yyyy-MM-dd HH:mm:ss.SSS'), TIMESTAMPTOSTRING(return_date, 'yyyy-MM-dd HH:mm:ss.SSS'), ceil((cast(return_date AS DOUBLE) – cast(rental_date AS DOUBLE) ) / 60 / 60 / 24 / 1000) FROM rental; 1 | 2005-05-24 22:53:30.000 | 2005-05-26 22:04:30.000 | 2.0 2 | 2005-05-24 22:54:33.000 | 2005-05-28 19:40:33.000 | 4.0 3 | 2005-05-24 23:03:39.000 | 2005-06-01 22:12:39.000 | 8.0
- 46. 46 KSQL in action CREATE stream rental_lengths AS SELECT rental_id , TIMESTAMPTOSTRING(rental_date, 'yyyy-MM-dd HH:mm:ss.SSS') , TIMESTAMPTOSTRING(return_date, 'yyyy-MM-dd HH:mm:ss.SSS') , ceil(( cast(return_date AS DOUBLE) – cast( rental_date AS DOUBLE) ) / 60 / 60 / 24 / 1000) FROM rental;
- 47. 47 KSQL in action ksql> select rental_id, rental_date, return_date, RENTAL_LENGTH_DAYS from rental_lengths; 3 | 2005-05-24 23:03:39.000 | 2005-06-01 22:12:39.000 | 8.0 4 | 2005-05-24 23:04:41.000 | 2005-06-03 01:43:41.000 | 10.0 7 | 2005-05-24 23:11:53.000 | 2005-05-29 20:34:53.000 | 5.0
- 48. 48 KSQL in action $ kafka-topics --zookeeper localhost:2181 --list RENTAL_LENGTHS $ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic RENTAL_LENGTHS | jq '.' { "RENTAL_DATE": "2005-05-24 22:53:30.000", "RENTAL_LENGTH_DAYS": 2, "RETURN_DATE": "2005-05-26 22:04:30.000", "RENTAL_ID": 1 }
- 49. 49 KSQL in action CREATE stream long_rentals AS SELECT * FROM rental_lengths WHERE rental_length_days > 7; ksql> select rental_id, rental_date, return_date, RENTAL_LENGTH_DAYS from long_rentals; 3 | 2005-05-24 23:03:39.000 | 2005-06-01 22:12:39.000 | 8.0 4 | 2005-05-24 23:04:41.000 | 2005-06-03 01:43:41.000 | 10.0
- 50. 50 Confluent: a Streaming Platform based on Apache Kafka™ Database Changes Log Events loT Data Web Events … CRM Data Warehouse Database Hadoop Data Integration … Monitoring Analytics Custom Apps Transformations Real-time Applications … Apache Open Source Confluent Open Source Confluent Commercial Confluent Platform Confluent Platform Apache Kafka™ Data Compatibility Schema Registry Monitoring & Administration Confluent Control Center Operations Replicator | Auto Data Balancing Development and Connectivity Clients | Connectors
- 51. 51 Thank You!