Ceph アーキテクチャ概説
•Download as PPTX, PDF•
89 likes•30,568 views

Gluster Community Day 2014 で発表した Ceph の解説スライドを、日本語に翻訳したものです。
Report
Share



























































Ceph アーキテクチャ概説
- 1. Ceph アーキテクチャ概説 Gluster Community Day, 20 May 2014 Haruka Iwao
- 2. もくじ Ceph とは何か Ceph のアーキテクチャ Ceph と OpenStack まとめ
- 3. Ceph とは何か
- 5. 頭足類?
- 8. Cephの歴史 2003 UCSCで開発開始 2006 オープンソース化 主要な論文が発表 2012 Inktank 創業 “Argonaut” がリリース UCSC: カリフォルニア大学サンタクルーズ校
- 11. Cephのアーキテクチャ
- 12. Cephの概略図
- 13. Cephのレイヤー RADOS = /dev/sda Ceph FS = ext4 /dev/sda ext4
- 15. RADOS (2) Cephの中核 すべてのデータはRADOSに保 存される Ceph FS が用いるメタデータを 含む mon と osd の2つから成る CRUSHアルゴリズムが特徴
- 16. OSD Object storage daemon 1ディスクにつき1OSD xfs/btrfs をバックエンドに使用 Btrfs のサポートは実験的 整合性担保と性能向上のため、 Write-aheadなジャーナルを利用 OSDの台数は3〜数万
- 17. OSD (2) DISK FS DISK DISK OSD DISK DISK OSD OSD OSD OSD FS FS FSFS btrfs xfs ext4
- 19. オブジェクトの配置 RADOS は “CRUSH” アルゴリズ ムを用いてオブジェクトを配置 オブジェクトの場所は100%計算の みで求められる メタデータサーバーが不要 SPoFなし 非常に良いスケーラビリティ
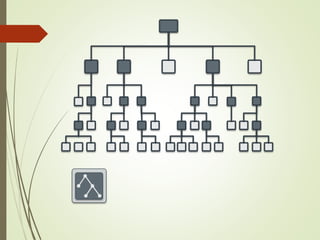
- 20. CRUSHについて 1. Placement group(PG) を割り当て PG = Hash(オブジェクト名) % PG数 2. OSD = CRUSH(PG, クラスタマップ, ルール) 1 2
- 22. オブジェクト配置の求め方 0100111010100111011 オブジェクト名: abc, プール: test Hash(“abc”) % 256 = 0x23 “test” = 3 Placement Group: 3.23
- 23. PG から OSDへの割り当て Placement Group: 3.23 CRUSH(PG 3.23, クラスタマップ, ルール) → osd.1, osd.5, osd.9 1 5 9
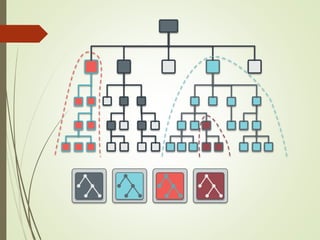
- 25. OSDがfailしたら OSDが“down”状態になる 5分後, “out”状態に変わる クラスタマップが更新される CRUSH(PG 3.23, クラスタマップ1, ルール) → osd.1, osd.5, osd.9 CRUSH(PG 3.23, クラスタマップ2, ルール) → osd.1, osd.3, osd.9
- 26. CRUSHまとめ オブジェクト名 + クラスタ マップ → オブジェクトの場所 決定的なアルゴリズム メタデータを完全に排除 計算はクライアント側で可能 クラスタマップはネットワー クの階層を反映
- 27. RADOSGW RADOS A reliable, autonomous, distributed object store comprised of self-healing, self-managing, intelligent storage nodes LIBRADOS A library allowing apps to directly access RADOS, with support for C, C++, Java, Python, Ruby, and PHP RBD A reliable and fully- distributed block device, with a Linux kernel client and a QEMU/KVM driver CEPH FS A POSIX-compliant distributed file system, with a Linux kernel client and support for FUSE RADOSGW A bucket-based REST gateway, compatible with S3 and Swift
- 28. RADOSGW S3 / Swift 互換なRADOS用の ゲートウェイ
- 29. RBD RADOS A reliable, autonomous, distributed object store comprised of self-healing, self-managing, intelligent storage nodes LIBRADOS A library allowing apps to directly access RADOS, with support for C, C++, Java, Python, Ruby, and PHP RBD A reliable and fully- distributed block device, with a Linux kernel client and a QEMU/KVM driver CEPH FS A POSIX-compliant distributed file system, with a Linux kernel client and support for FUSE RADOSGW A bucket-based REST gateway, compatible with S3 and Swift
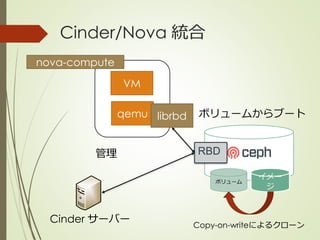
- 31. RBDの利用の仕方 直接マウントできる rbd map foo --pool rbd mkfs -t ext4 /dev/rbd/rbd/foo OpenStack 統合 CinderとGlanceから利用可能 後ほど詳しく説明
- 32. Ceph FS RADOS A reliable, autonomous, distributed object store comprised of self-healing, self-managing, intelligent storage nodes LIBRADOS A library allowing apps to directly access RADOS, with support for C, C++, Java, Python, Ruby, and PHP RBD A reliable and fully- distributed block device, with a Linux kernel client and a QEMU/KVM driver CEPH FS A POSIX-compliant distributed file system, with a Linux kernel client and support for FUSE RADOSGW A bucket-based REST gateway, compatible with S3 and Swift
- 35. Ceph FS と OSD MDS OSDOSDOSD POSIX メタデータ (ツリー, 時間, 所有者など) MDS メタデータの変更を記録 データの読み書き メタデータはメモリ上で管理
- 41. Ceph FS はまだ実験的
- 43. ローリングアップグレード サービスを止めずにバージョ ンアップが可能 デーモンを一つずつstop/start mon → osd → mds → radowgw の順で実施
- 44. Erasure coding レプリケーションの代わりに、 Erasure coding(消失訂正符号) を用いてデータを保護 アクセス頻度の少ないデータ に適している Erasure Coding レプリケーション 容量オーバーヘッド (2台の故障に耐える) およそ40% 200% CPU負荷 高い 低い レイテンシ 高い 低い
- 45. 階層化キャッシュ キャッシュtier 例) SSD ベースtier 例) HDD, erasure coding librados クライアントには透過的 読み書き キャッシュミス時の 読み込み キャッシュミス時のfetch ベースtierへフラッシュ
- 48. OpenStack 統合
- 49. OpenStack と Ceph
- 53. を で用いるメリット イメージとボリュームに単一 のストレージを提供 Copy-on-writeによるクロー ンとスナップショットの利用 qemu, KVMのネイティブサ ポートによる高い性能
- 55. まとめ
- 56. Ceph とは 高いスケーラビリティを持つ ストレージ オブジェクト、ブロック、 POSIXファイルシステムすべて に単一のアーキテクチャ OpenStackとの統合はすでに 実績がある
- 57. Ceph と GlusterFS の比較 Ceph GlusterFS データ配置 オブジェクト単位 ファイル単位 ファイルの場所 決定的なアルゴリ ズムによる (CRUSH) 分散ハッシュテー ブル, xattrに保存 レプリケーション サーバーサイド クライアントサイ ド 主な使い道 オブジェクト/ブ ロックストア POSIX互換のファイ ルシステム 課題 POSIXファイルシス テムに改善が必要 オブジェクト/ブ ロックストアに改 善が必要
- 58. 参考資料 Ceph Documents https://ceph.com/docs/master/ Well documented. Sébastien Han http://www.sebastien-han.fr/blog/ An awesome blog. CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data http://ceph.com/papers/weil-crush-sc06.pdf CRUSH algorithm paper Ceph: A Scalable, High-Performance Distributed File System http://www.ssrc.ucsc.edu/Papers/weil-osdi06.pdf Ceph paper Ceph の覚え書きのインデックス http://www.nminoru.jp/~nminoru/unix/ceph/
- 59. One more thing
- 60. Calamariがオープンソース化 “Calamari, the monitoring and diagnostics tool that Inktank has developed as part of the Inktank Ceph Enterprise product, will soon be open sourced.” http://ceph.com/community/red-hat-to-acquire-inktank/#sthash.1rB0kfRS.dpuf
- 61. Calamariの画面
- 62. Thank you!
Editor's Notes
- Cephalapod is a kind of animals. It is something like octopus. Well, let’s talk about the software.
- Ceph is… Sounds familiar? It is really similar to GlusterFS, and has many features in common. The goal of Ceph is to provide cheap, fast and reliable storage as free software.
- The development of Ceph was started in 2003 by Sage Weil. He open-sourced the source code in 2006. Also some important papers were published in 2006. He later founded a company called Inktank to continue development of Ceph and provide commercial support. In 2012, the first stable release “Argonaut” was released.
- In April 2014, something big has happened. Red Hat acquired Inktank and Ceph.
- Major releases of Ceph happen every three months. The code names goes in alphabet order, and the latest release is Firefly. The next release will be Giant release that is coming in July.
- Next I am going to talk about the architecture of Ceph. Ceph has very simple but robust architecture.
- This figure represents each block in Ceph. RADOS, RADOSGW, RBD, CEPH FS are all important keyword when talking about Ceph. I will explain them one by one later. The important thing is Ceph has a layered architecture, and RADOS is the base of all systems.
- This is similar to ordinary file system. RADOS is analogous to block storage, something like /dev/sda, and Ceph FS for example is the ext4 file system. By using this architecture, Ceph is simple and easy to expand.