
























Clustering
- 1. Machine Learning: Unsupervised Classification Dr. Muhammad Shaheen
- 2. © M. Shahbaz – 2006Dr.Muhammad.Shahbaz@gmail.com Clustering
- 3. © M. Shahbaz – 2006Dr.Muhammad.Shahbaz@gmail.com Lecture Outline • What is Clustering • Supervised and Unsupervised Classification • Types of Clustering Algorithms • Most Common Techniques • Areas of Applications • Discussion • Result
- 4. Clustering - Definition ─ Process of grouping similar items together ─ Clusters should be very similar to each other but… ─ Should be very different from the objects of other clusters/ other clusters ─ We can say that intra-cluster similarity between objects is high and inter-cluster similarity is low ─ Important human activity --- used from early childhood in distinguishing between different items such as cars and cats, animals and plants etc.
- 5. Supervised and Unsupervised Classification ─ What is Classification? ─ What is Supervised Classification/Learning? ─ What is Unsupervised Classification/Learning? ─ SOM – Self Organizing Maps
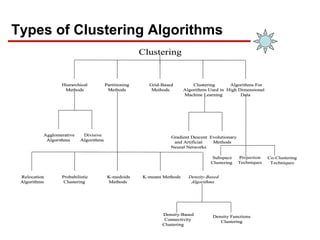
- 6. Types of Clustering Algorithms ─ Clustering has been a popular area of research ─ Several methods and techniques have been developed to determine natural grouping among the objects Jain, A. K., Murty, M. N., and Flynn, P. J., Data Clustering: A Survey. ACM Computing Surveys, 1999. 31: pp. 264-323. Jain, A. K. and Dubes, R. C., Algorithms for Clustering Data. 1988, Englewood Cliffs, NJ: Prentice Hall. 013022278X
- 7. Types of Clustering Algorithms Hierarchical Methods Partitioning Methods Grid-Based Methods Clustering Algorithms Used in Machine Learning Algorithms For High Dimensional Data Agglomerative Algorithms Divisive Algorithms Relocation Algorithms Probabilistic Clustering K-medoids Methods K-means Methods Density-Based Algorithms Density-Based Connectivity Clustering Density Functions Clustering Gradient Descent and Artificial Neural Networks Evolutionary Methods Subspace Clustering Co-Clustering Techniques Projection Techniques Clustering Hierarchical Methods Partitioning Methods Grid-Based Methods Clustering Algorithms Used in Machine Learning Algorithms For High Dimensional Data Hierarchical Methods Partitioning Methods Grid-Based Methods Clustering Algorithms Used in Machine Learning Algorithms For High Dimensional Data Agglomerative Algorithms Divisive Algorithms Agglomerative Algorithms Divisive Algorithms Relocation Algorithms Probabilistic Clustering K-medoids Methods K-means Methods Density-Based Algorithms Relocation Algorithms Probabilistic Clustering K-medoids Methods K-means Methods Density-Based Algorithms Density-Based Connectivity Clustering Density Functions Clustering Density-Based Connectivity Clustering Density Functions Clustering Gradient Descent and Artificial Neural Networks Evolutionary Methods Gradient Descent and Artificial Neural Networks Evolutionary Methods Subspace Clustering Co-Clustering Techniques Projection Techniques Clustering
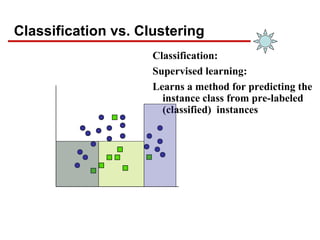
- 8. Classification vs. Clustering Classification: Supervised learning: Learns a method for predicting the instance class from pre-labeled (classified) instances
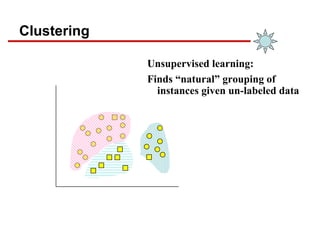
- 9. Clustering Unsupervised learning: Finds “natural” grouping of instances given un-labeled data
- 10. Clustering Evaluation • Manual inspection • Benchmarking on existing labels • Cluster quality measures –distance measures –high similarity within a cluster, low across clusters
- 11. The Distance Function • Simplest case: one numeric attribute A – Distance(X,Y) = A(X) – A(Y) • Several numeric attributes: – Distance(X,Y) = Euclidean distance between X,Y • Are all attributes equally important? – Weighting the attributes might be necessary
- 12. Simple Clustering: K-means Works with numeric data only 1) Pick a number (K) of cluster centers (at random) 2) Assign every item to its nearest cluster center (e.g. using Euclidean distance) 3) Move each cluster center to the mean of its assigned items 4) Repeat steps 2,3 until convergence (change in cluster assignments less than a threshold)
- 13. K-means example, step 1 k1 k2 k3 X Y Pick 3 initial cluster centers (randomly)
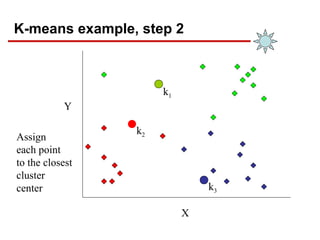
- 14. K-means example, step 2 k1 k2 k3 X Y Assign each point to the closest cluster center
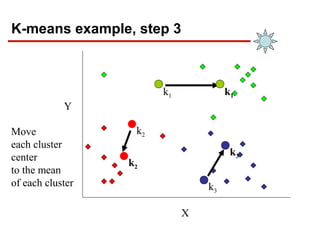
- 15. K-means example, step 3 X Y Move each cluster center to the mean of each cluster k1 k2 k2 k1 k3 k3
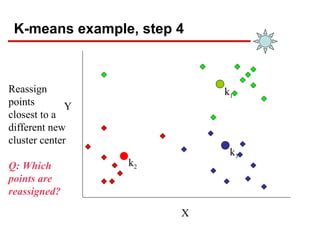
- 16. K-means example, step 4 X Y Reassign points closest to a different new cluster center Q: Which points are reassigned? k1 k2 k3
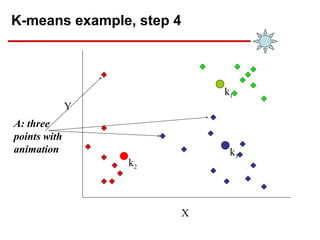
- 17. K-means example, step 4 … X Y A: three points with animation k1 k3 k2
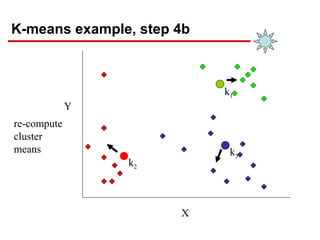
- 18. K-means example, step 4b X Y re-compute cluster means k1 k3 k2
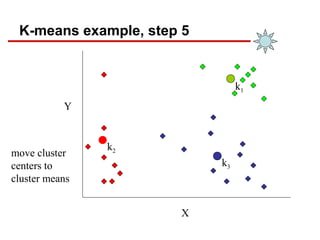
- 19. K-means example, step 5 X Y move cluster centers to cluster means k2 k1 k3
- 21. Pros and cons of K-Means
- 22. K-means variations • K-medoids – instead of mean, use medians of each cluster –Mean of 1, 3, 5, 7, 9 is –Mean of 1, 3, 5, 7, 1009 is –Median of 1, 3, 5, 7, 1009 is –Median advantage: not affected by extreme values • For large databases, use sampling 5 205 5
- 23. k-Medoids
- 25. Evaluating Cost of Swapping Medoids
- 26. Evaluating Cost of Swapping Medoids
- 27. Four Cases
- 28. Total Cost of Swap
- 29. K-means clustering summary Advantages • Simple, understandable • items automatically assigned to clusters Disadvantages • Must pick number of clusters before hand • All items forced into a cluster • Too sensitive to outliers since an object with an extremely large value may substantially distort the distribution of data
- 30. Hierarchical clustering • Agglomerative Clustering – Start with single-instance clusters – At each step, join the two closest clusters – Design decision: distance between clusters • Divisive Clustering – Start with one universal cluster – Find two clusters – Proceed recursively on each subset – Can be very fast • Both methods produce a dendrogram g a c i e d k b j f h
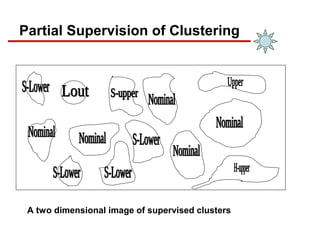
- 31. Partial Supervision of Clustering A two dimensional image of supervised clusters
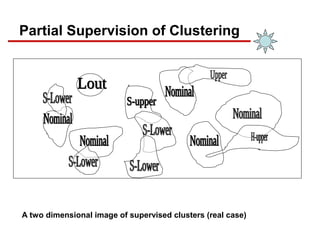
- 32. A two dimensional image of supervised clusters (real case) Partial Supervision of Clustering
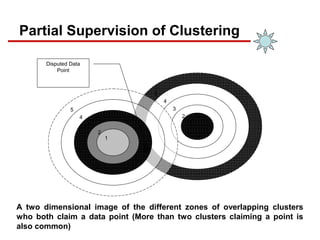
- 33. Partial Supervision of Clustering 5 4 3 2 1 5 4 3 2 1 Disputed Data Point A two dimensional image of the different zones of overlapping clusters who both claim a data point (More than two clusters claiming a point is also common)
- 34. Research Problems ─ Effective and Efficient methods of Clustering ─ Scalability ─ Handling different types of data ─ Handling complex multidimensional data ─ Complex shapes of clusters ─ Subspace Clustering ─ Cluster overlapping etc.
- 35. Examples of Clustering Applications • Marketing: discover customer groups and use them for targeted marketing and re-organization • Astronomy: find groups of similar stars and galaxies • Earth-quake studies: Observed earth quake epicenters should be clustered along continent faults • Genomics: finding groups of gene with similar expressions • …
- 36. Clustering Summary • unsupervised • many approaches –K-means – simple, sometimes useful • K-medoids is less sensitive to outliers –Hierarchical clustering – works for symbolic attributes –Can be used to fill in missing values
- 37. Questions ?