Data Mesh
•
10 likes•5,322 views

Presentation on Data Mesh: The paradigm shift is a new type of eco-system architecture, which is a shift left towards a modern distributed architecture in which it allows domain-specific data and views “data-as-a-product,” enabling each domain to handle its own data pipelines.










Data Mesh
- 1. Data Mesh on Azure Piethein Strengholt 20 January 2022
- 2. Introduction Piethein Strengholt • Former Principal Data Architect at a large bank • Author of the book Data Management at Scale • 10+ Consultancy experience
- 3. Trends which transform our data landscapes Massive increase of computing power driven by hardware innovation (SSD storage, in- Memory, GPU) let us move the data to the compute. Cloud, API’s make it easier to integrate. Software & Platform as a Service (SAAS, PAAS) offerings will push the connectivity and API usage even further. Explosion of tools New (open source) concepts are introduced, such as NoSQL database types, Block chain, new database designs, distributed models (Hadoop), new analytical, etc. Exponential growth of data; especially external (open data, social), internal, structured, unstructured can all be used for delivering more insight. Eco-system connectivity Exponential growth of (outside) data Increase of computing power Stronger regulatory requirements, such as GDPR and BCBS 239. Data Quality and Data Lineage becomes more important. Increased regulatory attention The read/write ratio changes because of intensive data consumption. Data is read much more, increased real-time consumption, more search. The read/write ratio increases
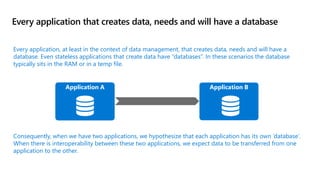
- 4. Every application that creates data, needs and will have a database Application A Application B Consequently, when we have two applications, we hypothesize that each application has its own ‘database’. When there is interoperability between these two applications, we expect data to be transferred from one application to the other. Every application, at least in the context of data management, that creates data, needs and will have a database. Even stateless applications that create data have “databases”. In these scenarios the database typically sits in the RAM or in a temp file.
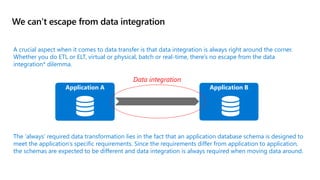
- 5. We can’t escape from data integration Application A Application B The ‘always’ required data transformation lies in the fact that an application database schema is designed to meet the application’s specific requirements. Since the requirements differ from application to application, the schemas are expected to be different and data integration is always required when moving data around. A crucial aspect when it comes to data transfer is that data integration is always right around the corner. Whether you do ETL or ELT, virtual or physical, batch or real-time, there’s no escape from the data integration* dilemma. Data integration
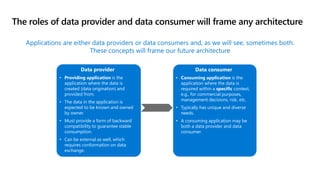
- 6. The roles of data provider and data consumer will frame any architecture Applications are either data providers or data consumers and, as we will see, sometimes both. These concepts will frame our future architecture Data provider • Providing application is the application where the data is created (data origination) and provided from. • The data in the application is expected to be known and owned by owner. • Must provide a form of backward compatibility to guarantee stable consumption. • Can be external as well, which requires conformation on data exchange. Data consumer • Consuming application is the application where the data is required within a specific context, e.g., for commercial purposes, management decisions, risk, etc. • Typically has unique and diverse needs. • A consuming application may be both a data provider and data consumer.
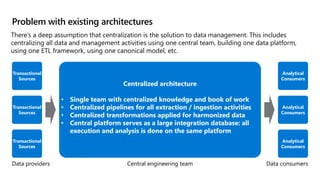
- 7. Problem with existing architectures There’s a deep assumption that centralization is the solution to data management. This includes centralizing all data and management activities using one central team, building one data platform, using one ETL framework, using one canonical model, etc. Transactional Sources Analytical Consumers Centralized architecture • Single team with centralized knowledge and book of work • Centralized pipelines for all extraction / ingestion activities • Centralized transformations applied for harmonized data • Central platform serves as a large integration database: all execution and analysis is done on the same platform Data providers Data consumers Central engineering team Transactional Sources Transactional Sources Analytical Consumers Analytical Consumers
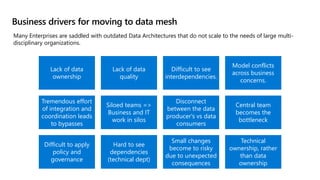
- 8. Business drivers for moving to data mesh Lack of data ownership Lack of data quality Difficult to see interdependencies. Model conflicts across business concerns. Tremendous effort of integration and coordination leads to bypasses Siloed teams => Business and IT work in silos Disconnect between the data producer's vs data consumers Central team becomes the bottleneck Difficult to apply policy and governance Hard to see dependencies (technical dept) Small changes become to risky due to unexpected consequences Technical ownership, rather than data ownership Many Enterprises are saddled with outdated Data Architectures that do not scale to the needs of large multi- disciplinary organizations.
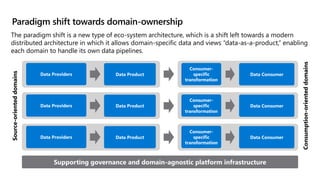
- 9. Paradigm shift towards domain-ownership The paradigm shift is a new type of eco-system architecture, which is a shift left towards a modern distributed architecture in which it allows domain-specific data and views “data-as-a-product,” enabling each domain to handle its own data pipelines. Supporting governance and domain-agnostic platform infrastructure Data Providers Data Product Data Providers Data Product Data Providers Data Product Source-oriented domains Consumer- specific transformation Data Consumer Consumer- specific transformation Data Consumer Consumer- specific transformation Data Consumer Consumption-oriented domains
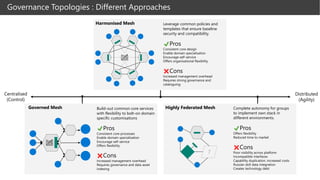
- 10. Governed Mesh Harmonised Mesh Highly Federated Mesh ? Build-out common core services with flexibility to bolt-on domain specific customisations ✔Pros Consistent core processes Enable domain specialisation Encourage self-service Offers flexibility ❌Cons Increased management overhead Requires governance and data asset indexing Complete autonomy for groups to implement own stack in different environments. ✔Pros Offers flexibility Reduced time to market ❌Cons Poor visibility across platform Incompatible interfaces Capability duplication, increased costs Russian doll data integration Creates technology debt Leverage common policies and templates that ensure baseline security and compatibility. ✔Pros Consistent core design Enable domain specialisation Encourage self-service Offers organisational flexibility ❌Cons Increased management overhead Requires strong governance and cataloguing Governance Topologies : Different Approaches Centralised (Control) Distributed (Agility)
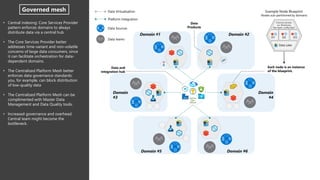
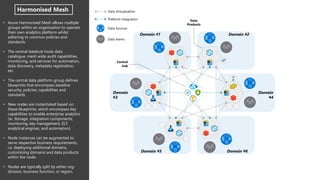
- 11. D1 D2 D3 • Central indexing: Core Services Provider pattern enforces domains to always distribute data via a central hub • The Core Services Provider better addresses time-variant and non-volatile concerns of large data consumers, since it can facilitate orchestration for data- dependent domains. • The Centralized Platform Mesh better enforces data governance standards: you, for example, can block distribution of low-quality data • The Centralized Platform Mesh can be complimented with Master Data Management and Data Quality tools. • Increased governance and overhead. Central team might become the bottleneck. Data Lake Example Node Blueprint Nodes sub-partitioned by domains Each node is an instance of the blueprint. Data and integration hub Domain #5 Domain #6 Data Products Data Virtualisation Platform Integration Data Sources Data teams Domain #3 Domain #2 Domain #4 Domain #1 Common services (i.e. Monitoring, Key mgmt., config repo) Governed mesh
- 12. • Azure Harmonised Mesh allows multiple groups within an organisation to operate their own analytics platform whilst adhering to common policies and standards. • The central datahub hosts data catalogue, mesh wide audit capabilities, monitoring, and services for automation, data discovery, metadata registration, etc. • The central data platform group defines blueprints that encompass baseline security, policies, capabilities and standards. • New nodes are instantiated based on these blueprints, which encompass key capabilities to enable enterprise analytics (ie. Storage, integration components, monitoring, key management, ELT, analytical engines, and automation) • Node instances can be augmented to serve respective business requirements, i.e. deploying additional domains, customising domains and data products within the node. • Nodes are typically split by either org- division, business function, or region. Harmonised Mesh Central hub Data Products Domain #5 Domain #6 Domain #3 Domain #2 Domain #4 Domain #1 Data Virtualisation Platform Integration Data Sources Data teams
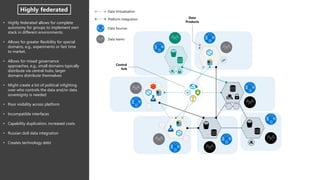
- 13. • Highly federated allows for complete autonomy for groups to implement own stack in different environments. • Allows for greater flexibility for special domains, e.g., experiments or fast time to market. • Allows for mixed governance approaches, e.g., small domains typically distribute via central hubs, larger domains distribute themselves • Might create a lot of political infighting over who controls the data and/or data sovereignty is needed • Poor visibility across platform • Incompatible interfaces • Capability duplication, increased costs • Russian doll data integration • Creates technology debt Highly federated Central hub Data Products Data Virtualisation Platform Integration Data Sources Data teams
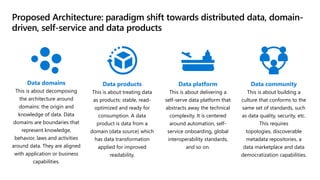
- 14. Proposed Architecture: paradigm shift towards distributed data, domain- driven, self-service and data products Data domains This is about decomposing the architecture around domains: the origin and knowledge of data. Data domains are boundaries that represent knowledge, behavior, laws and activities around data. They are aligned with application or business capabilities. Data products This is about treating data as products: stable, read- optimized and ready for consumption. A data product is data from a domain (data source) which has data transformation applied for improved readability. Data platform This is about delivering a self-serve data platform that abstracts away the technical complexity. It is centered around automation, self- service onboarding, global interoperability standards, and so on. Data community This is about building a culture that conforms to the same set of standards, such as data quality, security, etc. This requires topologies, discoverable metadata repositories, a data marketplace and data democratization capabilities.
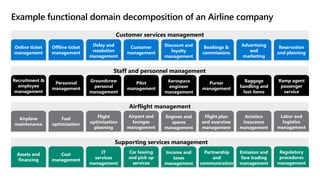
- 15. Example functional domain decomposition of an Airline company Online ticket management Discount and loyalty management Offline ticket management Bookings & commissions Delay and resolution management Advertising and marketing Customer management Reservation and planning Recruitment & employee management Aerospace engineer management Personnel management Purser management Groundcrew personal management Baggage handling and lost items Pilot management Ramp agent passenger service Airplane maintenance Engines and spares management Fuel optimization Flight plan and overview management Flight optimization planning Aviation insurance management Airport and lounges management Labor and logistics management Assets and financing Income and taxes management Cost management Partnership and communication IT services management Emission and fare trading management Car leasing and pick up services Regulatory procedures management Customer services management Staff and personnel management Airflight management Supporting services management
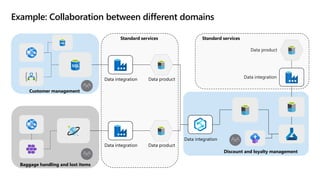
- 16. Example: Collaboration between different domains Data product Data product Data integration Data integration Data integration Data product Data integration Customer management Discount and loyalty management Baggage handling and lost items Standard services Standard services
- 17. The following guidance ensures better data ownership, data usability and data platform usage: • Define data interoperability standards, such as protocols, file formats and data types. • Define required metadata: schema, classifications, business terms, attribute relationships, etc. • Define data filtering approach: reserved column names, encapsulated metadata, etc. • Determine level of granularity of partitioning (domain, application, component, etc.) • Setup conditions for onboarding new data: data quality criteria, structure of data, external data, etc. • Define data product guidance (grouping of data, reference data, data types, etc.) • Define requirements contract or data sharing repository • Define governance roles (data owner, application owner, data steward, data user, platform owner, etc.) • Establish capabilities for lineage ingestion + define procedure for lineage delivery + unique hash key for data lineage • Define lineage level of granularity (application, table, column) • Determine classifications, tags, scanning rules • Define conditions for data consumption (via secure views, secure layer, ETL, etc.) • How to organize data lake (containers, folders, sub-folders, etc.) • Define data profiling and life cycle management criteria (move after 7 years, etc.) • Define enterprise reference data (key identifiers, enrichment process, etc.) • Define approach for log and historical data processing: transactional data, master data, reference data • Define process for redeliveries and reconciliation process (data versioning) • Align with Enterprise Architecture on technology choices: what services are allowed by what domains; what services are reserved. There is long list of Data Governance-related tasks
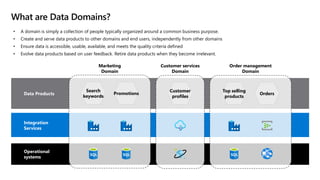
- 18. What are Data Domains? Search keywords Promotions Top selling products Orders Customer profiles Data Products Integration Services Operational systems Marketing Domain Customer services Domain Order management Domain • A domain is simply a collection of people typically organized around a common business purpose. • Create and serve data products to other domains and end users, independently from other domains • Ensure data is accessible, usable, available, and meets the quality criteria defined • Evolve data products based on user feedback. Retire data products when they become irrelevant.
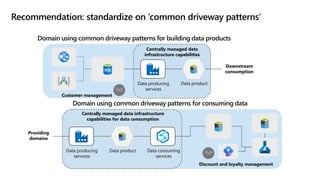
- 19. Recommendation: standardize on ‘common driveway patterns’ Data product Data producing services Centrally managed data infrastructure capabilities for data consumption Data consuming services Discount and loyalty management Providing domains Domain using common driveway patterns for consuming data Domain using common driveway patterns for building data products Data product Data producing services Customer management Centrally managed data infrastructure capabilities Downstream consumption
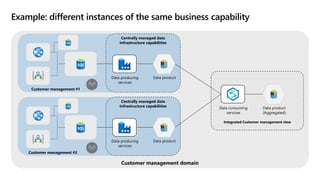
- 20. Data product Data producing services Customer management #1 Centrally managed data infrastructure capabilities Data product Data producing services Customer management #2 Centrally managed data infrastructure capabilities Data consuming services Integrated Customer management view Data product (Aggregated) Customer management domain Example: different instances of the same business capability
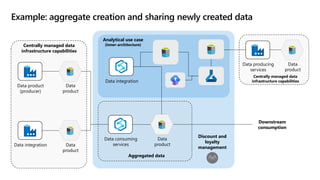
- 21. Data product Data product Data product (producer) Data integration Data consuming services Centrally managed data infrastructure capabilities Aggregated data Data integration Discount and loyalty management Data product Analytical use case (Inner-architecture) Downstream consumption Data product Data producing services Centrally managed data infrastructure capabilities Example: aggregate creation and sharing newly created data
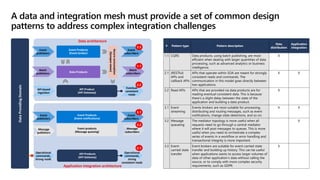
- 22. A data and integration mesh must provide a set of common design patterns to address complex integration challenges # Pattern type Pattern description Data distribution Application integration 1.1 CQRS Data products, using batch publishing, are most efficient when dealing with larger quantities of data processing, such as advanced analytics or business intelligence. X 2.1 (RESTful) APIs and callback APIs APIs that operate within SOA are meant for strongly consistent reads and commands. The communication in this model goes directly between two applications. X X 2.2 Read APIs APIs that are provided via data products are for reading eventual consistent data. This is because there’s a slight delay between the state of the application and building a data product. X 3.1 Event streaming Events brokers are most suitable for processing, distributing and routing messages, such as event notifications, change state detections, and so on. X X 3.2 Message queueing The mediator topology is more useful when all requests need to go through a central mediator where it will post messages to queues. This is more useful when you need to orchestrate a complex series of events in a workflow or error handling and transactional integrity is more important. X 3.3 Event- carried state transfer Event brokers are suitable for event-carried state transfer and building up history. This can be useful when applications wants to access larger volumes of data of other application’s data without calling the source, or to comply with more complex security requirements, such as GDPR. X Data Providing Domain Operational commands, strong reads API Products (API Gateway) Operational commands, strong consistent reads Event publishers Batch publishers API Product (API Gateway) Data Products Secure consumption (Synapse views) Event Products (Event broker) Eventual consistent reads Event subscribers Batch subscribers Event publishers Message publishers Message subscribers Event Products (Event notifications) Event products (Message queuing) Event subscribers API-based ingestion 2.1 2.2 3.3 1.1 3.1 3.2 Application integration architecture Data architecture
- 23. Best practises from the field: • The transition towards a domain-oriented structure is a transition. Instead of mapping out everything upfront, you can work out your domain list organically, as you are onboarding new providers and consumers into your architecture. • Domains should align with the business model, strategies and business processes. The best practise is to use business capabilities as a reference model, study common terminology (ubiquitous language) and overlapping data requirements. • When choosing application boundaries, be aware that the word application means different things to different people. Lastly, domain modelling and domain-driven design play a vital role in Enterprise Architecture (EA). • As a general principle, your domains should never directly talk to systems or applications from other domains. Always use anti-corruption layers: data products, API products or events. A best practice for enforcement is to apply isolation, for example network segregation • It’s the ubiquitous language, a formalized and agreed representation of the language, that both the engineers, the experts and the users share to understand each other. This language is typically stored in a central data catalogue. • Setting boundaries covers both the business granularity and technical granularity: • The business granularity starts with a top-down decomposition of the business concerns: the analysis of the highest- level functional context, scope (i.e., ‘boundary context’) and activities. These must be divided into smaller ‘areas’, use cases and business objectives. This exercise requires good business knowledge and expertise on how to divide efficiently business processes, domains, functions etc. • The technical granularity is performed towards specific goals such as: reusability, flexibility (easy adaptation to frequent functional changes), performance, security and scalability. The key point of balance is about making the right trade-offs. Business users might use the same data, but if the technical requirements are conflicting with each other, it might be better to separate concerns. For example, if one specific business task need to intensively aggregate data, and other to quickly select individual records, it can be better to separate these conflicting concerns. The same might apply for flexibility. One business task might require daily changes, the other one must remain stable for at least a quarter. Again, you should consider separating the concerns. Data Domain nuances and considerations
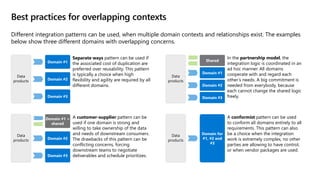
- 24. Best practices for overlapping contexts Data products Domain #1 Domain #2 Domain #3 Data products Domain #1 + shared Domain #2 Domain #3 Data products Shared Domain #2 Domain #3 Domain #1 Data products Domain for #1, #2 and #3 In the partnership model, the integration logic is coordinated in an ad hoc manner. All domains cooperate with and regard each other’s needs. A big commitment is needed from everybody, because each cannot change the shared logic freely. Separate ways pattern can be used if the associated cost of duplication are preferred over reusability. This pattern is typically a choice when high flexibility and agility are required by all different domains. A conformist pattern can be used to conform all domains entirely to all requirements. This pattern can also be a choice when the integration work is extremely complex, no other parties are allowing to have control, or when vendor packages are used. Different integration patterns can be used, when multiple domain contexts and relationships exist. The examples below show three different domains with overlapping concerns. A customer-supplier pattern can be used if one domain is strong and willing to take ownership of the data and needs of downstream consumers. The drawbacks of this pattern can be conflicting concerns, forcing downstream teams to negotiate deliverables and schedule prioritizes.
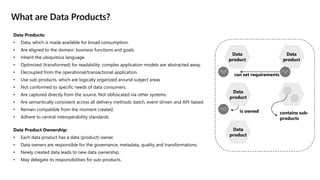
- 25. Data Products: • Data, which is made available for broad consumption. • Are aligned to the domain: business functions and goals. • Inherit the ubiquitous language. • Optimized (transformed) for readability: complex application models are abstracted away. • Decoupled from the operational/transactional application. • Use sub-products, which are logically organized around subject areas • Not conformed to specific needs of data consumers. • Are captured directly from the source. Not obfuscated via other systems. • Are semantically consistent across all delivery methods: batch, event-driven and API-based. • Remain compatible from the moment created. • Adhere to central interoperability standards. Data Product Ownership: • Each data product has a data (product) owner. • Data owners are responsible for the governance, metadata, quality and transformations. • Newly created data leads to new data ownership. • May delegate its responsibilities for sub-products. What are Data Products? Data product Data product Data product Data product is owned contains sub- products can set requirements
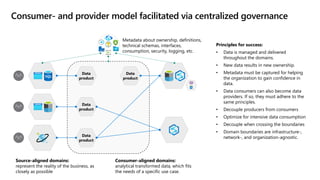
- 26. Metadata about ownership, definitions, technical schemas, interfaces, consumption, security, logging, etc. Source-aligned domains: represent the reality of the business, as closely as possible Consumer-aligned domains: analytical transformed data, which fits the needs of a specific use case. Principles for success: • Data is managed and delivered throughout the domains. • New data results in new ownership. • Metadata must be captured for helping the organization to gain confidence in data. • Data consumers can also become data providers. If so, they must adhere to the same principles. • Decouple producers from consumers • Optimize for intensive data consumption • Decouple when crossing the boundaries • Domain boundaries are infrastructure-, network-, and organization-agnostic. Consumer- and provider model facilitated via centralized governance Data product Data product Data product Data product
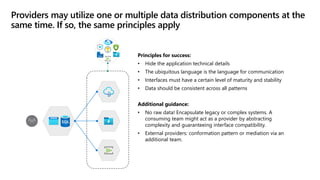
- 27. Principles for success: • Hide the application technical details • The ubiquitous language is the language for communication • Interfaces must have a certain level of maturity and stability • Data should be consistent across all patterns Providers may utilize one or multiple data distribution components at the same time. If so, the same principles apply Additional guidance: • No raw data! Encapsulate legacy or complex systems. A consuming team might act as a provider by abstracting complexity and guaranteeing interface compatibility. • External providers: conformation pattern or mediation via an additional team.
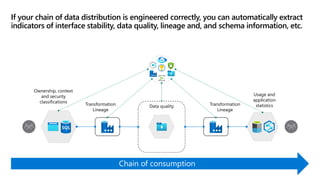
- 28. If your chain of data distribution is engineered correctly, you can automatically extract indicators of interface stability, data quality, lineage and, and schema information, etc. Ownership, context and security classifications Transformation Lineage Transformation Lineage Usage and application statistics Data quality
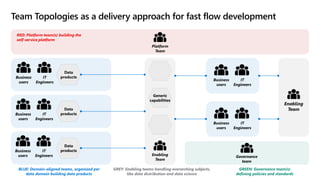
- 29. Team Topologies as a delivery approach for fast flow development Platform Team Enabling Team Business users IT Engineers Business users IT Engineers Business users IT Engineers Governance team Data products Data products Data products Enabling Team BLUE: Domain-aligned teams, organized per data domain building data products GREY: Enabling teams handling overarching subjects, like data distribution and data science RED: Platform team(s) building the self-service platform GREEN: Governance team(s) defining policies and standards Generic capabilities Business users IT Engineers Business users IT Engineers
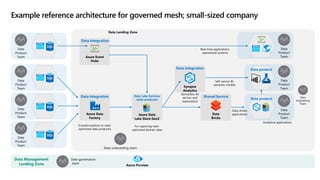
- 30. Azure Event Hubs Azure Data Lake Store Gen2 For capturing read- optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Management Landing Zone Data governance team Azure Purview Data Lake Services (data products) Azure Data Factory (Transformations to read- optimized data products) Data integration Data integration Data Landing Zone Data Bricks Shared Service Data-driven applications Data product Data product Example reference architecture for governed mesh; small-sized company
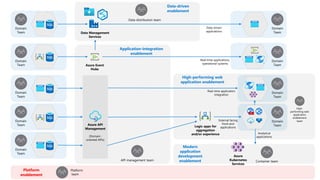
- 31. Azure Event Hubs Data Management Services Domain Team Domain Team Domain Team Domain Team Domain Team API management team Data distribution team Data-driven enablement Application-integration enablement Domain Team Domain Team Azure API Management (Domain- oriented APIs) Logic apps for aggregation and/or experience Container team Domain Team Domain Team Data-driven applications Real-time applications, operational systems External facing front-end applications Analytical applications Azure Kubernetes Services High- performing web application enablement team High-performing web application enablement Platform enablement Platform team Modern application development enablement Real-time application integration
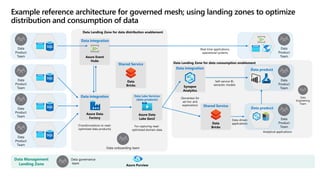
- 32. Azure Event Hubs Azure Data Lake Gen2 For capturing read- optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Landing Zone for data consumption enablement Data Management Landing Zone Data governance team Azure Purview Data Lake Services (data products) Azure Data Factory (Transformations to read- optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service Data-driven applications Data product Data product Data Bricks Shared Service Example reference architecture for governed mesh; using landing zones to optimize distribution and consumption of data
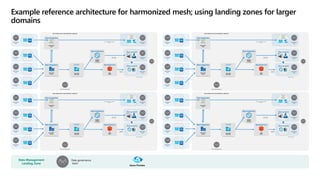
- 33. Data Management Landing Zone Data governance team Azure Purview Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimizeddomain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hocandexploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimizeddata products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service Data-driven applications Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimizeddomain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hocandexploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimizeddata products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service Data-driven applications Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimizeddomain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hocandexploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimizeddata products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service Data-driven applications Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimizeddomain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hocandexploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimizeddata products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service Data-driven applications Data product Data product Example reference architecture for harmonized mesh; using landing zones for larger domains
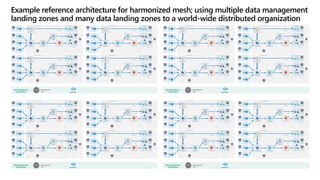
- 34. Data Management Landing Zone Data governance team Azure Purview Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Data Management Landing Zone Data governance team Azure Purview Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Data Management Landing Zone Data governance team Azure Purview Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Data Management Landing Zone Data governance team Azure Purview Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Azure Event Hubs Azure Data Lake Gen2 For capturing read-optimized domain data Data Product Team Data Product Team Data Product Team Data Product Team Data-onboarding team Data integration Synapse Analytics (Serverless for ad-hoc and exploration) Data Product Team Data Product Team Data Product Team Real-time applications, operational systems Self-service BI, semantic models Analytical applications Data Engineering Team Data Lake Services (data products) Azure Data Factory (Transformations to read-optimized data products) Data integration Data integration Data Landing Zone for data distribution enablement Data Bricks Shared Service D a t a - d ri v e n a p p li c a ti o n s Data product Data product Example reference architecture for harmonized mesh; using multiple data management landing zones and many data landing zones to a world-wide distributed organization
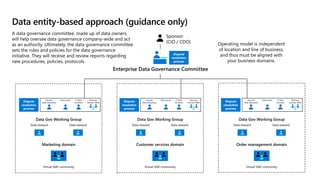
- 35. Data entity-based approach (guidance only) Customer Orders Product Enterprise Data Governance Committee A data governance committee, made up of data owners, will help oversee data governance company-wide and act as an authority. Ultimately, the data governance committee sets the rules and policies for the data governance initiative. They will receive and review reports regarding new procedures, policies, protocols. Dispute resolution process Operating model is independent of location and line of business, and thus must be aligned with your business domains. Sponsor (CIO / CDO) Domain Data Steward(s) Business Domain SMEs IT Data Architect Data owner Dispute resolution process Domain Data Steward(s) Business Domain SMEs IT Data Architect Data owner Dispute resolution process Domain Data Steward(s) Business Domain SMEs IT Data Architect Data owner Dispute resolution process Data Gov Working Group Data steward Data steward Order management domain Virtual SME community Data Gov Working Group Data steward Data steward Data Gov Working Group Data steward Data steward Customer services domain Virtual SME community Marketing domain Virtual SME community
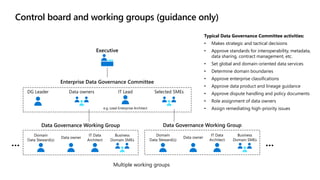
- 36. Control board and working groups (guidance only) Data owners DG Leader Selected SMEs IT Lead e.g. Lead Enterprise Architect Enterprise Data Governance Committee Domain Data Steward(s) Business Domain SMEs IT Data Architect Data owner Domain Data Steward(s) Business Domain SMEs IT Data Architect Data owner … … Multiple working groups Executive Data Governance Working Group Data Governance Working Group Typical Data Governance Committee activities: • Makes strategic and tactical decisions • Approve standards for interoperability, metadata, data sharing, contract management, etc. • Set global and domain-oriented data services • Determine domain boundaries • Approve enterprise classifications • Approve data product and lineage guidance • Approve dispute handling and policy documents • Role assignment of data owners • Assign remediating high-priority issues
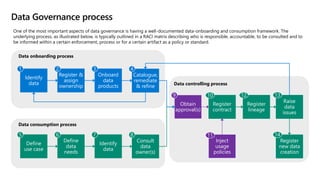
- 37. Data Governance process Identify data Register & assign ownership Catalogue, remediate & refine Onboard data products Define use case Define data needs Consult data owner(s) Identify data Obtain approval(s) Register contract Register lineage Raise data issues Register new data creation Data onboarding process Data consumption process Data controlling process Inject usage policies One of the most important aspects of data governance is having a well-documented data-onboarding and consumption framework. The underlying process, as illustrated below, is typically outlined in a RACI matrix describing who is responsible, accountable, to be consulted and to be informed within a certain enforcement, process or for a certain artifact as a policy or standard.
- 38. Why Data Governance is easier on public cloud • Data locality is easier: everything is metadata- driven (management groups, tagging, labeled resources, policies, etc.) • Governance enforcement is easier: consistency via policies, hub-spoke deployment models, subscription boundaries, etc. • No need to maintain copies with new technologies like Azure Synapse and Polyglot Persistence (virtualized instances, fast queries) • Large availability of powerful tools to process data at scale • Security in a hybrid world can be better enforced via Azure policies, Azure Arc, Azure Monitor, managed identities, audit logging, data retention policies, fine-grained access controls, etc.
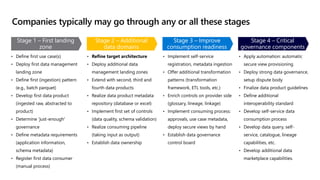
- 39. Companies typically may go through any or all these stages • Define first use case(s) • Deploy first data management landing zone • Define first (ingestion) pattern (e.g., batch parquet) • Develop first data product (ingested raw, abstracted to product) • Determine 'just-enough' governance • Define metadata requirements (application information, schema metadata) • Register first data consumer (manual process) • Refine target architecture • Deploy additional data management landing zones • Extend with second, third and fourth data products • Realize data product metadata repository (database or excel) • Implement first set of controls (data quality, schema validation) • Realize consuming pipeline (taking input as output) • Establish data ownership • Implement self-service registration, metadata ingestion • Offer additional transformation patterns (transformation framework, ETL tools, etc.) • Enrich controls on provider side (glossary, lineage, linkage) • Implement consuming process: approvals, use case metadata, deploy secure views by hand • Establish data governance control board • Apply automation: automatic secure view provisioning • Deploy strong data governance, setup dispute body • Finalize data product guidelines • Define additional interoperability standard • Develop self-service data consumption process • Develop data query, self- service, catalogue, lineage capabilities, etc. • Develop additional data marketplace capabilities. Stage 1 – First landing zone Stage 2 – Additional data domains Stage 3 – Improve consumption readiness Stage 4 – Critical governance components
- 40. Enterprise Scale Analytics and AI – Solution Narrative & Architecture Solution Brief The Enterprise Scale Analytics and AI Framework is intended to provide a robust, distributed, and scalable Azure analytics environment for large enterprise customers. Incorporating the tenants of the Well Architected Framework, it follows a hub-and- spoke model for centralized governance and controls while allowing logical or functional business units to operate individual Landing Zones to facilitate their analytics workloads. The centralized Data Management Subscription allows for collaboration and information sharing without compromising security. Additionally, the framework provides organizational guidance to align with best practice and maintain security boundaries. Recommendations are outlined across operational teams and end-user personas to ensure that all relevant needs can be met. Throughout the development of this framework, Customer Architecture & Engineering have been working side-by-side with the customer and our Product & Engineering teams. Architecture Key Components Critical Data Management Subscription Services – central to each customer environment is the Data Management Sub which is dependent on the following services for facilitating metadata, security, and governance of the entire ecosystem: • Azure Purview • Azure Log Analytics • Azure Key Vault • Azure Active Directory • Azure Private Link • Azure Virtual Network Core Data Landing Zone Services – For each Data LZ deployment, the requested data elements and use- cases will most commonly use the following services: • Azure Synapse Analytics • Azure Databricks • Azure Data Factory • Azure Data Lake Storage An objective of this framework is to keep all aspects of operations on the Azure platform, including 3rd party components where necessary. Scenario • Enterprise Scale Analytics and AI allows multiple groups within an organisation to operate their own analytics platform whilst adhering to common policies and standards. • The central Data Management Subscription hosts data catalogue, mesh wide audit capabilities, monitoring, and auxiliary services for automation. • The central data platform group defines policies that encompass baseline security, policies, capabilities and standards. • New Data Landing Zones are instantiated based on these blueprints, which encompass key capabilities to enable enterprise analytics (i.e.. Storage, monitoring, key management, ELT, analytical engines, and automation) • Data Landing Zones can be augmented to serve respective business requirements, i.e., deploying additional domains, customising domains and data products within the Data Landing Zone. • Data Landing Zones are typically split by either org-division, function, or region. Customer Scenario • Committed to agility and Self-Service Analytics • Already using ADLS Gen 2 or migrating from ADLS Gen 1. • Minimum deployment of 1 x Data Management and 1 x Data LZ • Expandable by adding Data LZs as business needs change or grow Design Principles • Data Domain and Data Product democratization • Microservices-driven design • Policy-driven governance • Single control and management plane • Align Azure-native design and roadmaps Data Landing Zone = Azure Subscription Enterprise Scaled Version Data Management Subscription Data Landing Zone Data Products Basic Version Source: Customer Architecture and Engineering (CAE)
- 41. Cloud Adoption Framework for Data Management and Analytics: https://docs.microsoft.com/en-us/azure/cloud-adoption- framework/scenarios/data-management/ Start with a common value proposition: • Create a common vision for data use aligned with the goals of the organization. • Allocate data governance representatives throughout the organization. Gather support. • Stress out the importance of data ownership: robust data, stable data consumption, increased customer satisfaction, new business opportunities. • Stress out that higher quality creates greater trust in data. • Layout common definitions of “Data Architecture” and “Data Governance”. Make it relevant for the rest of the organization. • Identify the most difficult data challenges facing stakeholders and determine how data governance can address these. • Establish a data governance body and its target operating model. • Create improved understanding and transparency around processes. • Identify milestones and metrics for your data governance proposition. These might include: • Reduction of time in finding and collecting data • Reduction of solving data inconsistencies and errors • Time saved by streamlining data processes • Improvements made by data quality • Expanded use and new use cases • Regulatory compliancy, data privacy and security goals Typical next steps
- 42. Progress through the data governance maturity model Ungoverned Stage 1 Stage 2 Fully governed People No stakeholder executive sponsor Stakeholder sponsor in place Stakeholder sponsor in place Stakeholder sponsor in place No roles and responsibilities defined Roles and responsibilities defined Roles and responsibilities defined Roles and responsibilities defined No DG control board DG control board in place but no ability DG control board in place with data DG control board in place with data No DG working groups No DG working groups Some DG working groups in place All DG working groups in place No data owners accountable for data No data owners accountable for data Some data owners in place All data owners in place No data stewards appointed with responsibility for data quality Some data stewards in place for DQ but scope too broad e.g. whole dept Data stewards in place and assigned to DG working groups for specific data Data stewards in place assigned to DG working groups for specific data No one accountable for data privacy No one accountable for data privacy CPO accountable for privacy (no tools) CPO accountable for privacy with tools No one accountable for access security IT accountable for access security IT Sec accountable for access security IT Sec accountable for access security & responsible for enforcing privacy No one to produce trusted data assets Data publisher identified and accountable for producing trusted data Data publisher identified and accountable for producing trusted data Data publisher identified and accountable for producing trusted data No SMEs identified for data entities Some SMEs identified but not engaged SMEs identified & in DG working groups SMEs identified & in DG working groups Process No common business vocabulary Common biz vocabulary started in a glossary Common business vocabulary established Common business vocabulary complete No way to know where data is located, its data quality or if it is sensitive data Data catalog auto data discovery, profiling & sensitive data detection on some systems Data catalog auto data discovery, profiling & sensitive data detection on all structured data Data catalog auto data discovery, profiling & sensitive data detection on structured & unstructured in all systems w/ full auto tagging No process to govern authoring or maintenance of policies and rules Governance of data access security policy authoring & maintenance on some systems Governance of data access security, privacy & retention policy authoring & maintenance Governance of data access security, privacy & retention policy authoring & maintenance No way to enforce policies & rules Piecemeal enforcement of data access security policies & rules across systems with no catalog integration Enforcement of data access security and privacy policies and rules across systems with catalog integration Enforcement of data access security, privacy & retention policies and rules across all systems No processes to monitor data quality, data privacy or data access security Some ability to monitor data quality Some ability to monitor privacy (e.g. queries) Monitoring and stewardship of DQ & data privacy on core systems with DBMS masking Monitoring and stewardship of DQ & data privacy on all systems with dynamic masking No availability of fully trusted data assets Dev started on a small set of trusted data assets using data fabric software Several core trusted data assets created using data fabric Continuous delivery of trusted data assets with enterprise data marketplace No way to know if a policy violation occurred or process to act if it did Data access security violation detection in some systems Data access security violation detection in all systems Data access security violation detection in all systems No vulnerability testing process Limited vulnerability testing process Vulnerability testing process on all systems Vulnerability testing process on all systems No common process for master data creation, maintenance & sync MDM with common master data CRUD & sync processes for single entity MDM with common master data CRUD & sync processes for some data entities MDM with common master data CRUD & sync processes for all master data entities complete
- 43. Progress through the data governance maturity model Ungoverned Stage 1 Stage 2 Fully governed Policies No data governance classification schemes on confidentiality & retention Data governance classification scheme for confidentiality Data governance classification scheme for both confidentiality and retention Data governance classification scheme for both confidentiality and retention No policies & rules to govern data quality Policies & rules to govern data quality started in common vocabulary in business glossary Policies & rules to govern data quality defined in common vocabulary in catalog biz glossary Policies & rules to govern data quality defined in common vocabulary in catalog biz glossary No policies & rules to govern data access security Some policies & rules to govern data access security created in different technologies Policies & rules to govern data access security & data privacy consolidated in the data catalog using classification scheme Policies & rules to govern data access security, data privacy and retention consolidated in the data catalog using classification schemes and enforced everywhere No policies & rules to govern data privacy Some policies & rules to govern data privacy Policies & rules to govern data access security & data privacy consolidated in the data catalog using classification scheme Policies & rules to govern data access security, data privacy and retention consolidated in the data catalog using classification schemes and enforced everywhere No policies & rules to govern data retention No policies & rules to govern data retention Some policies & rules to govern data retention Policies & rules to govern data access security, data privacy and retention consolidated in the data catalog using classification schemes and enforced everywhere No policies & rules to govern master data maintenance Policies & rules to govern master data maintenance for a single master data entity Policies & rules to govern master data maintenance for some master data entities Policies & rules to govern master data maintenance for all master data entities Technology No data catalog with auto data discovery, profiling & sensitive data detection Data catalog with auto data discovery, profiling & sensitive data detection purchased Data catalog with auto data discovery, profiling & sensitive data detection purchased Data catalog with auto data discovery, profiling & sensitive data detection purchased No data fabric software with multi-cloud edge and data centre connectivity Data fabric software with multi-cloud edge and data centre connectivity & catalog integration purchased Data fabric software with multi-cloud edge and data centre connectivity & catalog integration purchased Data fabric software with multi-cloud edge and data centre connectivity & catalog integration purchased No metadata lineage Metadata lineage available in data catalog on trusted assets being developed using fabric Metadata lineage available in data catalog on trusted assets being developed using fabric Metadata lineage available in data catalog on trusted assets being developed using fabric No data stewardship tools Data stewardship tools available as part of the data fabric software Data stewardship tools available as part of the data fabric software Data stewardship tools available as part of the data fabric software No data access security tool Data access security in multiple technologies Data access security in multiple technologies Data access security enforced in all systems No data privacy enforcement software No data privacy enforcement software Data privacy enforcement in some DBMSs Data privacy enforcement in all data stores No master data management system Single entity master data management system Multi-entity master data management system Multi-entity master data management system
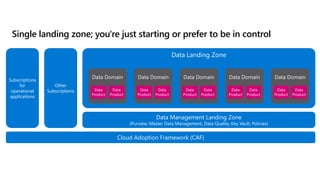
- 44. Cloud Adoption Framework (CAF) Subscriptions for operational applications Other Subscriptions Data Management Landing Zone (Purview, Master Data Management, Data Quality, Key Vault, Policies) Data Landing Zone Data Domain Data Domain Data Domain Data Domain Data Domain Data Product Data Product Data Product Data Product Data Product Data Product Data Product Data Product Data Product Data Product Single landing zone; you're just starting or prefer to be in control
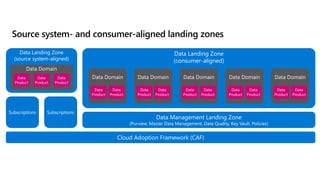
- 45. Cloud Adoption Framework (CAF) Subscriptions Subscriptions Data Management Landing Zone (Purview, Master Data Management, Data Quality, Key Vault, Policies) Data Landing Zone (consumer-aligned) Data Domain Data Domain Data Domain Data Domain Data Domain Data Product Data Product Data Product Data Product Data Product Data Product Data Product Data Product Data Product Data Product Data Landing Zone (source system-aligned) Data Domain Data Product Data Product Data Product Source system- and consumer-aligned landing zones
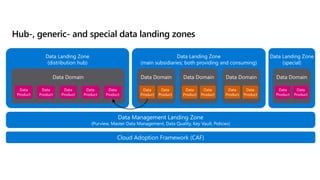
- 46. Data Landing Zone (special) Data Landing Zone (main subsidiaries; both providing and consuming) Cloud Adoption Framework (CAF) Data Management Landing Zone (Purview, Master Data Management, Data Quality, Key Vault, Policies) Data Landing Zone (distribution hub) Data Domain Data Domain Data Product Data Product Data Domain Data Product Data Product Data Domain Data Product Data Product Data Domain Data Product Data Product Hub-, generic- and special data landing zones Data Product Data Product Data Product Data Product Data Product
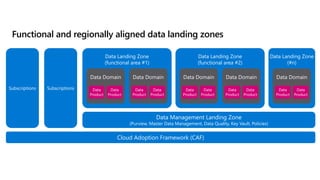
- 47. Data Landing Zone (#n) Cloud Adoption Framework (CAF) Subscriptions Subscriptions Data Management Landing Zone (Purview, Master Data Management, Data Quality, Key Vault, Policies) Data Landing Zone (functional area #1) Data Domain Data Product Data Product Data Domain Data Product Data Product Data Domain Data Product Data Product Data Landing Zone (functional area #2) Data Domain Data Product Data Product Data Domain Data Product Data Product Functional and regionally aligned data landing zones
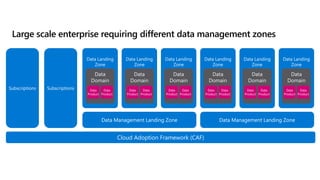
- 48. Cloud Adoption Framework (CAF) Subscriptions Subscriptions Data Management Landing Zone Data Landing Zone Data Domain Data Product Data Product Data Landing Zone Data Domain Data Product Data Product Data Landing Zone Data Domain Data Product Data Product Data Management Landing Zone Data Landing Zone Data Domain Data Product Data Product Data Landing Zone Data Domain Data Product Data Product Data Landing Zone Data Domain Data Product Data Product Large scale enterprise requiring different data management zones
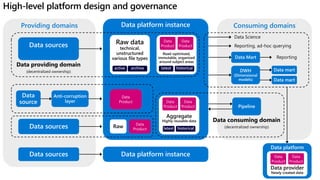
- 49. Providing domains Consuming domains Data sources Data platform instance Raw data technical, unstructured various file types Anti-corruption layer Data sources Raw Read-optimized, immutable, organized around subject areas Data Product latest historical archive active Data source Data platform instance Data sources Data Mart DWH (Dimensional models) Data mart Data mart Pipeline Aggregate Highly reusable data latest historical High-level platform design and governance Data Product Data Product Data Product Data Product Data Product Data platform Data provider Newly created data Data Product Data Product
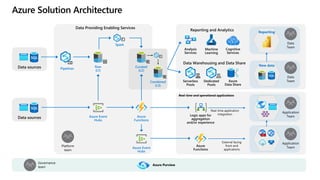
- 50. Azure Solution Architecture Azure Event Hubs Data sources Raw (L1) Spark Data Providing Enabling Services Reporting and Analytics Analysis Services Machine Learning Cognitive Services Azure Data Share Data Warehousing and Data Share Serverless Pools Dedicated Pools Data sources Azure Functions Logic apps for aggregation and/or experience External facing front-end applications Real-time application integration Application Team Application Team Real-time and operational applications Data Team New data Data Team Reporting Azure Functions Azure Purview Pipelines Curated (L2) Combined (L3) Azure Event Hubs Platform team Governance team