Геннадий Карпов, De Novo: "Cloud Disaster Recovery для пользователей Veeam Backup& Replication"
•
0 likes•483 views

Доклад директора по технологиям De Novo Геннадия Карпова на технологическом практикуме "Облака без лишних слов", 06.07.2016








Геннадий Карпов, De Novo: "Cloud Disaster Recovery для пользователей Veeam Backup& Replication"
- 1. De Novo© 2016 Veeam Cloud Disaster Recovery Геннадий Карпов Директор по технологиям
- 2. Приоритеты ИТ-служб в 2016 г. Источник: IDC Украина, 2016 2% 14% 24% 27% 53% 55% 0% 33% 31% 40% 50% 69% другое внедрение новых ИТ-сервисов модернизация ИТ-инфраструктуры повышение уровня защиты и эффективности хранения данных оптимизация затрат обеспечение непрерывности бизнеса Приоритетные ИТ-задачи 2016 2016 2015
- 3. 1. Облако как репозитарий резервных копий (vStorage, Veeam Cloud Repository, S3/swift Object Storage ). В случае потери основного ЦОД прикладной ландшафт можно восстановить из резервной копии на новом оборудовании или в Облаке. RPO ~4-24 часа, RTO ~дни (зависит от объема данных). 2. Зеркальный прикладной ландшафт в Облачном Датацентре. Репликация данных и механизм восстановления основан на функциональности прикладного ПО (Oracle DB, MS AD, Exchange, SQL Server). Возможна защита как виртуальных, так и физических операционных сред. Недеструктивное тестирование невозможно. Высокая сложность и потребление облачных ресурсов. Применимо не для всех ИТ-сервисов. RPO ~0-15 мин, RTO ~1-2 часа. 3. Зеркальные операционные среды в Облачном Датацентре (GeoCluster DRaaS). Геокластерная технология + репликация данных на уровне операционной системы. Возможна защита как виртуальных, так и физических операционных сред. Ограниченные возможности недеструктивного тестирования. RPO ~0-15 мин, RTO ~1-2 часа. 4. Зеркальная виртуальная инфраструктура (Zerto DRaaS). Репликация данных на уровне гипервизора. Возможна защита только виртуальных операционных сред VMware. Возможно недеструктивное автоматизированное тестирование. Автоматизация актуализации и исполнения DR-плана. RPO ~0-15 мин, RTO ~1-2 ч. 5. Veeam Cloud Disaster Recovery (VCDR). Репликация данных на уровне гипервизора. Возможно недеструктивное автоматизированное тестирование. Автоматизация исполнения DR-плана. RPO ~15-240 мин, RTO ~1-2 ч. DR-системы класса «земля-облако» 3
- 6. 6 Непрерывность ИТ это всегда проект Disaster Recovery Planning. Классификация бизнес-приложений и сервисов по критерию критичности для бизнеса; согласованные требования к RTO/RPO; определение взаимосвязанности систем и комплексов, ролей и прав персонала, участвующего в процедурах сопровождения. DR Implementation. Развертывание технологической платформы, настройка механизмов репликации. DR Operation. Разработка, моделирование и документирование процедур тестовой активации РЦ, восстановления сервисов в случае катастрофы и возврата в штатный режим.
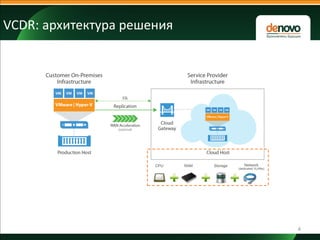
- 7. Выберите свой инструмент 7 Veeam Cloud Repository Veeam Cloud Disaster Recovery Zerto Disaster Recovery Подключение очень простое простое сложное Сетевая топология очень простая простая сложная RPO 6-24 часа 15+ мин 0-15 мин RTO часы/дни (зависит от объема данных) минуты/часы минуты/часы Множественные точки восстановления Автоматизированные DR-планы Недеструктивное тестирование и журналы для аудита Группы консистентности Реконфигурация гостевой ОС Интеграция с vCloud Director Репликация Hyper-V <-> vSphere Стоимость низкая умеренная высокая
- 8. 8 Veeam VCR/VCDR: технологии двойного назначения Миграция в Облако. Основной проблемой при миграции «тяжелых» ландшафтов является доступное окно миграции (обычно не более 48 часов). VCR/VCDR позволяет обеспечить безопасную фоновую миграцию основного объема данных в Облако с последующим быстрым переключением на облачный ландшафт. Быстрое тестирование на реальном профиле нагрузки. Временный перенос конкретного приложения в Облако с сохранением сетевой топологии позволяет провести нагрузочное тестирование на реальном профиле нагрузки с минимальными рисками (сохраняется возможность быстрого и безопасного возврата «на землю») Решение проблемы окна обслуживания. VCDR позволяет быстро перенести в Облако часть нагрузки без необходимости каких-либо изменений в сетевой топологии. Этот сценарий может быть использован для временного высвобождения части локальных ресурсов для проведения регламентных или ремонтно-восстановительных работ.