




























Machine Learning with Decision trees
- 1. Machine Learning with DECISION TREES Ramandeep Kaur Software Consultant Knoldus Software LLP
- 2. Agenda ● What are Decision trees? ● Appropriate problems for DTrees ● Information gain , Entropy ● Issues with DTrees ● Overfitting ● Pruning ● Demo
- 3. What are Decision trees? ● A decision tree is a tree in which each branch node represents a choice between a number of alternatives, and each leaf node represents a decision. ● A type of supervised learning algorithm.
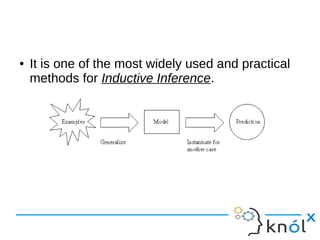
- 4. ● It is one of the most widely used and practical methods for Inductive Inference.
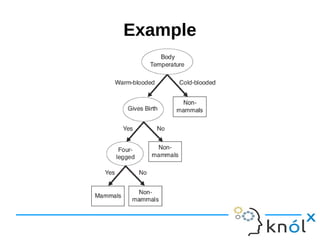
- 5. Example
- 6. Appropriate problems for DTrees ● Instances are represented by attribute-value pairs ● The target function has discrete output values ● The training data may contain errors ● The training data may have missing attribute values
- 7. How to select the deciding node? Which is the best Classifier?
- 8. Which node can be described easily?
- 9. ➔ Less impure node requires less information to describe it. ➔ More impure node requires more information. ===> Information theory is a measure to define this degree of disorganization in a system known as Entropy. So, we can conclude
- 10. Entropy - measuring homogeneity of a learning set ● Entropy is a measure of the uncertainty about a source of messages. ● Given a collection S, containing positive and negative examples of some target concept, the entropy of S relative to this classification. where, pi is the proportion of S belonging to class i
- 11. ● Entropy is 0 if all the members of S belong to the same class. ● Entropy is 1 when the collection contains an equal no. of +ve and -ve examples. ● Entropy is between 0 and 1 if the collection contains unequal no. of +ve and -ve examples.
- 12. Information gain ● Decides which attribute goes into a decision node. ● To minimize the decision tree depth, the attribute with the most entropy reduction is the best choice!
- 13. Where: ● S is each value v of all possible values of attribute A ● Sv = subset of S for which attribute A has value v ● |Sv| = number of elements in Sv ● |S| = number of elements in S The information gain, Gain(S,A) of an attribute A,
- 14. Issues in Decision Tree Learning
- 15. ISSUES ● How deeply to grow the decision tree? ● Handling continuous attributes ● Choosing an appropriate attribute selection measure ● Handling training data with missing attribute values
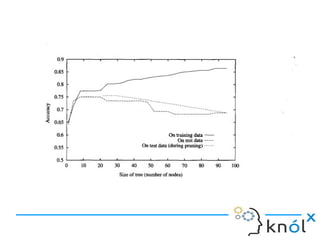
- 16. Overfitting in Decision Trees ● If a decision tree is fully grown, it may lose some generalization capability. ● This is a phenomenon known as overfitting.
- 17. Overfitting A hypothesis overfits the training examples if some other hypothesis that fits the training examples less well actually performs better over the entire distribution of instances (i.e, including instances beyond the training examples)
- 18. Why ??
- 19. Causes of Overfitting ● Overfitting Due to Presence of Noise - Mislabeled instances may contradict the class labels of other similar records. ● Overfitting Due to Lack of Representative Instances - Lack of representative instances in the training data can prevent refinement of the learning algorithm.
- 20. Overfitting Due to Noise: An Example
- 21. Overfitting Due to Noise
- 22. Overfitting Due to Noise
- 23. Overfitting Due to Lack of Samples
- 24. Overfitting Due to Lack of Samples ● Although the model’s training error is zero, its error rate on the test set is 30%. ● Humans, elephants, and dolphins are misclassified because the decision tree classifies all warmblooded vertebrates that do not hibernate as non-mammals.
- 25. A good model must not only fit the training data well but also accurately classify records it has never seen.
- 26. Avoiding overfitting in decision tree learning ● approaches that stop growing the tree earlier, before it reaches the point where it perfectly classifies the training data. ● approaches that allow the tree to overfit the data, and then post-prune the tree.
- 27. Approaches to implement ● separate set of examples ● a statistical test: chi-square test ● a heuristic called the Minimum Description Length principle - (explicit measure of the complexity for encoding the training examples and the decision tree, halting growth of the tree when this encoding size is minimized.)
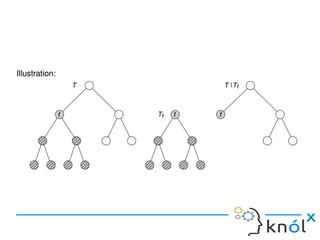
- 28. PRUNING ● Consider each of the decision nodes in the tree to be candidates for pruning. ● Pruning a decision node consists of removing the subtree rooted at that node, making it a leaf node, and assigning it the most common classification of the training examples affiliated with that node. ● Nodes are removed only if the resulting pruned tree performs no worse than the original over the validation set. ● Pruning of nodes continues until further pruning is harmful (i.e., decreases accuracy of the tree over the validation set).
- 31. DEMO
- 32. References ● Machine Learning – Tom Mitchell ● https://www3.nd.edu/~rjohns15/cse40647.sp14/ww
- 33. Thank You