Deep Dive on Amazon Redshift
•
8 likes•2,564 views

Analyzing big data quickly and efficiently requires a data warehouse optimized to handle and scale for large datasets. Amazon Redshift is a fast, petabyte-scale data warehouse that makes it simple and cost-effective to analyze big data for a fraction of the cost of traditional data warehouses. In this session, we take an in-depth look at data warehousing with Amazon Redshift for big data analytics. We cover best practices to take advantage of Amazon Redshift's columnar technology and parallel processing capabilities to deliver high throughput and query performance. We also discuss how to design optimal schemas, load data efficiently, and use work load management.



















































Deep Dive on Amazon Redshift
- 1. Deep Dive on Amazon Redshift Storage Subsystem and Query Life Cycle Eric Ferreira, Principal Database Engineer, Amazon Redshift Mar 2017
- 2. Deep Dive Overview • Amazon Redshift History and Development • Cluster Architecture • Concepts and Terminology • Storage Deep Dive • Design Considerations • Query Life Cycle • New & Upcoming Feature • Open Q&A
- 3. Amazon Redshift History & Development
- 4. Columnar MPP OLAP AWS IAMAmazon VPCAmazon SWF Amazon S3 AWSKMS Amazon Route 53 Amazon CloudWatch Amazon EC2 PostgreSQL Amazon Redshift
- 5. February 2013 February 2017 > 100 Significant Patches > 140 Significant Features
- 6. Amazon Redshift Cluster Architecture
- 7. Redshift Cluster Architecture • Massively parallel, shared nothing • Leader node – SQL endpoint – Stores metadata – Coordinates parallel SQL processing • Compute nodes – Local, columnar storage – Executes queries in parallel – Load, backup, restore 10 GigE (HPC) Ingestion Backup Restore SQL Clients/BI Tools 128GB RAM 16TB disk 16 cores S3 / EMR / DynamoDB / SSH JDBC/ODBC 128GB RAM 16TB disk 16 coresCompute Node 128GB RAM 16TB disk 16 coresCompute Node 128GB RAM 16TB disk 16 coresCompute Node Leader Node
- 8. 128GB RAM 16TB disk 16 cores 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node Leader Node
- 9. 128GB RAM 16TB disk 16 cores 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node Leader Node • Parser & Rewriter • Planner & Optimizer • Code Generator • Input: Optimized plan • Output: >=1 C++ functions • Compiler • Task Scheduler • WLM • Admission • Scheduling • PostgreSQL Catalog Tables
- 10. 128GB RAM 16TB disk 16 cores 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node Leader Node • Query execution processes • Backup & restore processes • Replication processes • Local Storage • Disks • Slices • Tables • Columns • Blocks
- 11. 128GB RAM 16TB disk 16 cores 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node Leader Node • Query execution processes • Backup & restore processes • Replication processes • Local Storage • Disks • Slices • Tables • Columns • Blocks
- 13. Designed for I/O Reduction • Columnar storage • Data compression • Zone maps aid loc dt 1 SFO 2016-09-01 2 JFK 2016-09-14 3 SFO 2017-04-01 4 JFK 2017-05-14 • Accessing dt with row storage: – Need to read everything – Unnecessary I/O aid loc dt CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date );
- 14. Designed for I/O Reduction • Columnar storage • Data compression • Zone maps aid loc dt 1 SFO 2016-09-01 2 JFK 2016-09-14 3 SFO 2017-04-01 4 JFK 2017-05-14 • Accessing dt with columnar storage: – Only scan blocks for relevant column aid loc dt CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date );
- 15. Designed for I/O Reduction • Columnar storage • Data compression • Zone maps aid loc dt 1 SFO 2016-09-01 2 JFK 2016-09-14 3 SFO 2017-04-01 4 JFK 2017-05-14 • Columns grow and shrink independently • Effective compression ratios due to like data • Reduces storage requirements • Reduces I/O aid loc dt CREATE TABLE loft_deep_dive ( aid INT ENCODE LZO ,loc CHAR(3) ENCODE BYTEDICT ,dt DATE ENCODE RUNLENGTH );
- 16. Designed for I/O Reduction • Columnar storage • Data compression • Zone maps aid loc dt 1 SFO 2016-09-01 2 JFK 2016-09-14 3 SFO 2017-04-01 4 JFK 2017-05-14 aid loc dt CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date ); • In-memory block metadata • Contains per-block MIN and MAX value • Effectively prunes blocks which cannot contain data for a given query • Eliminates unnecessary I/O
- 17. SELECT COUNT(*) FROM LOGS WHERE DATE = '09-JUNE-2013' MIN: 01-JUNE-2013 MAX: 20-JUNE-2013 MIN: 08-JUNE-2013 MAX: 30-JUNE-2013 MIN: 12-JUNE-2013 MAX: 20-JUNE-2013 MIN: 02-JUNE-2013 MAX: 25-JUNE-2013 Unsorted Table MIN: 01-JUNE-2013 MAX: 06-JUNE-2013 MIN: 07-JUNE-2013 MAX: 12-JUNE-2013 MIN: 13-JUNE-2013 MAX: 18-JUNE-2013 MIN: 19-JUNE-2013 MAX: 24-JUNE-2013 Sorted By Date Zone Maps
- 18. Terminology and Concepts: Data Sorting • Goals: • Physically order rows of table data based on certain column(s) • Optimize effectiveness of zone maps • Enable MERGE JOIN operations • Impact: • Enables rrscans to prune blocks by leveraging zone maps • Overall reduction in block I/O • Achieved with the table property SORTKEY defined over one or more columns • Optimal SORTKEY is dependent on: • Query patterns • Data profile • Business requirements
- 19. Terminology and Concepts: Slices • A slice can be thought of like a “virtual compute node” – Unit of data partitioning – Parallel query processing • Facts about slices: – Each compute node has either 2, 16, or 32 slices – Table rows are distributed to slices – A slice processes only its own data
- 20. Data Distribution • Distribution style is a table property which dictates how that table’s data is distributed throughout the cluster: • KEY: Value is hashed, same value goes to same location (slice) • ALL: Full table data goes to first slice of every node • EVEN: Round robin • Goals: • Distribute data evenly for parallel processing • Minimize data movement during query processing KEY ALL Node 1 Slice 1 Slice 2 Node 2 Slice 3 Slice 4 Node 1 Slice 1 Slice 2 Node 2 Slice 3 Slice 4 Node 1 Slice 1 Slice 2 Node 2 Slice 3 Slice 4 EVEN
- 21. Data Distribution: Example CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date ) DISTSTYLE (EVEN|KEY|ALL); CN1 Slice 0 Slice 1 CN2 Slice 2 Slice 3 Table: loft_deep_dive User Columns System Columns aid loc dt ins del row
- 22. Data Distribution: EVEN Example CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date ) DISTSTYLE EVEN; CN1 Slice 0 Slice 1 CN2 Slice 2 Slice 3 INSERT INTO loft_deep_dive VALUES (1, 'SFO', '2016-09-01'), (2, 'JFK', '2016-09-14'), (3, 'SFO', '2017-04-01'), (4, 'JFK', '2017-05-14'); Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Rows: 0 Rows: 0 Rows: 0 Rows: 0 (3 User Columns + 3 System Columns) x (4 slices) = 24 Blocks (24MB) Rows: 1 Rows: 1 Rows: 1 Rows: 1
- 23. Data Distribution: KEY Example #1 CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date ) DISTSTYLE KEY DISTKEY (loc); CN1 Slice 0 Slice 1 CN2 Slice 2 Slice 3 INSERT INTO loft_deep_dive VALUES (1, 'SFO', '2016-09-01'), (2, 'JFK', '2016-09-14'), (3, 'SFO', '2017-04-01'), (4, 'JFK', '2017-05-14'); Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Rows: 2 Rows: 0 Rows: 0 (3 User Columns + 3 System Columns) x (2 slices) = 12 Blocks (12MB) Rows: 0Rows: 1 Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Rows: 2Rows: 0Rows: 1
- 24. Data Distribution: KEY Example #2 CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date ) DISTSTYLE KEY DISTKEY (aid); CN1 Slice 0 Slice 1 CN2 Slice 2 Slice 3 INSERT INTO loft_deep_dive VALUES (1, 'SFO', '2016-09-01'), (2, 'JFK', '2016-09-14'), (3, 'SFO', '2017-04-01'), (4, 'JFK', '2017-05-14'); Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Rows: 0 Rows: 0 Rows: 0 Rows: 0 (3 User Columns + 3 System Columns) x (4 slices) = 24 Blocks (24MB) Rows: 1 Rows: 1 Rows: 1 Rows: 1
- 25. Data Distribution: ALL Example CREATE TABLE loft_deep_dive ( aid INT --audience_id ,loc CHAR(3) --location ,dt DATE --date ) DISTSTYLE ALL; CN1 Slice 0 Slice 1 CN2 Slice 2 Slice 3 INSERT INTO loft_deep_dive VALUES (1, 'SFO', '2016-09-01'), (2, 'JFK', '2016-09-14'), (3, 'SFO', '2017-04-01'), (4, 'JFK', '2017-05-14'); Rows: 0 Rows: 0 (3 User Columns + 3 System Columns) x (2 slice) = 12 Blocks (12MB) Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Rows: 0Rows: 1Rows: 2Rows: 4Rows: 3 Table: loft_deep_dive User Columns System Columns aid loc dt ins del row Rows: 0Rows: 1Rows: 2Rows: 4Rows: 3
- 26. Terminology and Concepts: Data Distribution • KEY – The key creates an even distribution of data – Joins are performed between large fact/dimension tables – Optimizing merge joins and group by • ALL – Small and medium size dimension tables (< 2-3M) • EVEN – When key cannot produce an even distribution
- 28. Storage Deep Dive: Disks • Redshift utilizes locally attached storage devices • Compute nodes have 2.5-3x the advertised storage capacity • 1, 3, 8, or 24 disks depending on node type • Each disk is split into two partitions – Local data storage, accessed by local CN – Mirrored data, accessed by remote CN • Partitions are raw devices – Local storage devices are ephemeral in nature – Tolerant to multiple disk failures on a single node
- 29. Storage Deep Dive: Blocks • Column data is persisted to 1MB immutable blocks • Each block contains in-memory metadata: – Zone Maps (MIN/MAX value) – Location of previous/next block • Blocks are individually compressed with 1 of 10 encodings • A full block contains between 16 and 8.4 million values
- 30. Storage Deep Dive: Columns • Column: Logical structure accessible via SQL • Physical structure is a doubly linked list of blocks • These blockchains exist on each slice for each column • All sorted & unsorted blockchains compose a column • Column properties include: – Distribution Key – Sort Key – Compression Encoding • Columns shrink and grow independently, 1 block at a time • Three system columns per table-per slice for MVCC
- 31. Block Properties: Design Considerations • Small writes: • Batch processing system, optimized for processing massive amounts of data • 1MB size + immutable blocks means that we clone blocks on write so as not to introduce fragmentation • Small write (~1-10 rows) has similar cost to a larger write (~100 K rows) • UPDATE and DELETE: • Immutable blocks means that we only logically delete rows on UPDATE or DELETE • Must VACUUM or DEEP COPY to remove ghost rows from table
- 32. Column Properties: Design Considerations • Compression: • COPY automatically analyzes and compresses data when loading into empty tables • ANALYZE COMPRESSION checks existing tables and proposes optimal compression algorithms for each column • Changing column encoding requires a table rebuild • DISTKEY and SORTKEY significantly influence performance (orders of magnitude) • Distribution Keys: • A poor DISTKEY can introduce data skew and an unbalanced workload • A query completes only as fast as the slowest slice completes • Sort Keys: • A sortkey is only effective as the data profile allows it to be • Selectivity needs to be considered
- 34. Storage Deep Dive: Slices • Each compute node has either 2, 16, or 32 slices • A slice can be thought of like a “virtual compute node” – Unit of data partitioning – Parallel query processing • Facts about slices: – Table rows are distributed to slices – A slice processes only its own data – Within a compute node all slices read from and write to all disks
- 35. 128GB RAM 16TB disk 16 cores 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node Leader Node • Parser & Rewriter • Planner & Optimizer • Code Generator • Input: Optimized plan • Output: >=1 C++ functions • Compiler • Task Scheduler • WLM • Admission • Scheduling • PostgreSQL Catalog Tables • Redshift System Tables (STV)
- 36. 128GB RAM 16TB disk 16 cores 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node 128GB RAM 16TB disk 16 cores Compute Node Leader Node • Parser & Rewriter • Planner & Optimizer • Code Generator • Input: Optimized plan • Output: >=1 C++ functions • Compiler • Task Scheduler • WLM • Admission • Scheduling • PostgreSQL Catalog Tables • Redshift System Tables (STV)
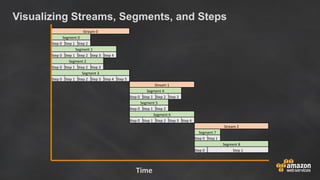
- 37. Query Execution Terminology • Step: An individual operation needed during query execution. Steps need to be combined to allow compute nodes to perform a join. Examples: scan, sort, hash, aggr • Segment: A combination of several steps that can be done by a single process. The smallest compilation unit executable by a slice. Segments within a stream run in parallel. • Stream: A collection of combined segments which output to the next stream or SQL client.
- 38. Visualizing Streams, Segments, and Steps Stream 0 Segment 0 Step 0 Step 1 Step 2 Segment 1 Step 0 Step 1 Step 2 Step 3 Step 4 Segment 2 Step 0 Step 1 Step 2 Step 3 Segment 3 Step 0 Step 1 Step 2 Step 3 Step 4 Step 5 Stream 1 Segment 4 Step 0 Step 1 Step 2 Step 3 Segment 5 Step 0 Step 1 Step 2 Segment 6 Step 0 Step 1 Step 2 Step 3 Step 4 Stream 2 Segment 7 Step 0 Step 1 Segment 8 Step 0 Step 1 Time
- 39. client JDBC ODBC Leader Node Parser Query Planner Code Generator Final Computations Generate code for all segments of one stream Explain Plans Compute Node Receive Compiled Code Run the Compiled Code Return results to Leader Compute Node Receive Compiled Code Run the Compiled Code Return results to Leader Return results to client Segments in a stream are executed concurrently. Each step in a segment is executed serially. Query Lifecycle
- 40. Query Execution Deep Dive: Leader Node 1. The leader node receives the query and parses the SQL. 2. The parser produces a logical representation of the original query. 3. This query tree is input into the query optimizer (volt). 4. Volt rewrites the query to maximize its efficiency. Sometimes a single query will be rewritten as several dependent statements in the background. 5. The rewritten query is sent to the planner which generates >= 1 query plans for the execution with the best estimated performance. 6. The query plan is sent to the execution engine, where it’s translated into steps, segments, and streams. 7. This translated plan is sent to the code generator, which generates a C++ function for each segment. 8. This generated C++ is compiled with gcc to a .o file and distributed to the compute nodes.
- 41. Query Execution Deep Dive: Compute Nodes • Slices execute the query segments in parallel. • Executable segments are created for one stream at a time. When the segments of that stream are complete, the engine generates the segments for the next stream. • When the compute nodes are done, they return the query results to the leader node for final processing. • The leader node merges the data into a single result set and addresses any needed sorting or aggregation. • The leader node then returns the results to the client.
- 42. Visualizing Streams, Segments, and Steps Stream 0 Segment 0 Step 0 Step 1 Step 2 Segment 1 Step 0 Step 1 Step 2 Step 3 Step 4 Segment 2 Step 0 Step 1 Step 2 Step 3 Segment 3 Step 0 Step 1 Step 2 Step 3 Step 4 Step 5 Stream 1 Segment 4 Step 0 Step 1 Step 2 Step 3 Segment 5 Step 0 Step 1 Step 2 Segment 6 Step 0 Step 1 Step 2 Step 3 Step 4 Stream 2 Segment 7 Step 0 Step 1 Segment 8 Step 0 Step 1 Time
- 43. Query Execution Stream 0 Segment 0 Step 0 Step 1 Step 2 Segment 1 Step 0 Step 1 Step 2 Step 3 Step 4 Segment 2 Step 0 Step 1 Step 2 Step 3 Segment 3 Step 0 Step 1 Step 2 Step 3 Step 4 Step 5 Stream 1 Segment 4 Step 0 Step 1 Step 2 Step 3 Segment 5 Step 0 Step 1 Step 2 Segment 6 Step 0 Step 1 Step 2 Step 3 Step 4 Stream 2 Segment 7 Step 0 Step 1 Segment 8 Step 0 Step 1 Time Stream 0 Segment 0 Step 0 Step 1 Step 2 Segment 1 Step 0 Step 1 Step 2 Step 3 Step 4 Segment 2 Step 0 Step 1 Step 2 Step 3 Segment 3 Step 0 Step 1 Step 2 Step 3 Step 4 Step 5 Stream 1 Segment 4 Step 0 Step 1 Step 2 Step 3 Segment 5 Step 0 Step 1 Step 2 Segment 6 Step 0 Step 1 Step 2 Step 3 Step 4 Stream 2 Segment 7 Step 0 Step 1 Segment 8 Step 0 Step 1 Stream 0 Segment 0 Step 0 Step 1 Step 2 Segment 1 Step 0 Step 1 Step 2 Step 3 Step 4 Segment 2 Step 0 Step 1 Step 2 Step 3 Segment 3 Step 0 Step 1 Step 2 Step 3 Step 4 Step 5 Stream 1 Segment 4 Step 0 Step 1 Step 2 Step 3 Segment 5 Step 0 Step 1 Step 2 Segment 6 Step 0 Step 1 Step 2 Step 3 Step 4 Stream 2 Segment 7 Step 0 Step 1 Segment 8 Step 0 Step 1 Stream 0 Segment 0 Step 0 Step 1 Step 2 Segment 1 Step 0 Step 1 Step 2 Step 3 Step 4 Segment 2 Step 0 Step 1 Step 2 Step 3 Segment 3 Step 0 Step 1 Step 2 Step 3 Step 4 Step 5 Stream 1 Segment 4 Step 0 Step 1 Step 2 Step 3 Segment 5 Step 0 Step 1 Step 2 Segment 6 Step 0 Step 1 Step 2 Step 3 Step 4 Stream 2 Segment 7 Step 0 Step 1 Segment 8 Step 0 Step 1 Slices 0 1 2 3
- 44. New & Upcoming Features
- 45. Recently Released Features New Data Type - TIMESTAMPTZ • Support for Timestamp with Time zone : New TIMESTAMPTZ data type to input complete timestamp values that include the date, the time of day, and a time zone. Eg: 30 Nov 07:37:16 2016 PST Multi-byte Object Names • Support for Multi-byte (UTF-8) characters for tables, columns, and other database object names User Connection Limits • You can now set a limit on the number of database connections a user is permitted to have open concurrently Automatic Data Compression for CTAS • All newly created tables will leverage default encoding
- 46. Amazon Redshift Workload Management Waiting BI tools SQL clients Analytics tools Client Running Queue 1 Queue 2 4 Slots 2 Slots Short queries go to the head of the queue 1 1 Coming Soon: Short Query Bias
- 47. Amazon Redshift Cluster BI tools SQL clients Analytics tools Client Leader node Compute node Compute node Compute node 2 2 2 2 All queries receive a power start. Shorter queries benefit the most Coming Soon: Power Start
- 48. Monitor and control cluster resources consumed by a query Get notified, abort and reprioritize long-running / bad queries Pre-defined templates for common use cases Coming Soon: Query Monitoring Rules
- 49. BI tools SQL clientsAnalytics tools Client AWS Redshift ADFS Corporate Active Directory IAM Amazon Redshift ODBC/JDBC User groups Individual user Single Sign-On Identity providers New Redshift ODBC/JDBC drivers. Grab the ticket (userid) and get a SAML assertion. Coming Soon: IAM Authentication
- 50. Coming Soon: Lots More … Automatic and Incremental Background VACUUM • Reclaims space and sorts when Redshift clusters are idle • Vacuum is initiated when performance can be enhanced • Improves ETL and query performance Automatic Compression for New Tables • All newly created tables will leverage default encoding • Provides higher compression rates New Functions • Approximate Percentile 010101010101
- 51. Resources • https://github.com/awslabs/amazon-redshift-utils • https://github.com/awslabs/amazon-redshift-monitoring • https://github.com/awslabs/amazon-redshift-udfs • Admin scripts Collection of utilities for running diagnostics on your cluster • Admin views Collection of utilities for managing your cluster, generating schema DDL, etc. • ColumnEncodingUtility Gives you the ability to apply optimal column encoding to an established schema with data already loaded • Amazon Redshift Engineering’s Advanced Table Design Playbook https://aws.amazon.com/blogs/big-data/amazon-redshift-engineerings-advanced-table- design-playbook-preamble-prerequisites-and-prioritization/