Machine Learning Project - Default credit card clients
•
4 likes•7,816 views

- The model we built here will use all possible factors to predict data on customers to find who are defaulters and non‐defaulters next month. - The goal is to find the whether the clients are able to pay their next month credit amount. - Identify some potential customers for the bank who can settle their credit balance. - To determine if their customers could make the credit card payments on‐time. - Default is the failure to pay interest or principal on a loan or credit card payment.
Report
Share


































Machine Learning Project - Default credit card clients
- 1. Default of Credit Card Clients Presented By, Hetarth Bhatt – 251056818 Khushali Patel – 25105445 Rajaraman Ganesan – 251056279 Vatsal Shah – 251041322 Subject: Data Analytics Department of Electrical & Computer Engineering (M.Engg) Western University, Canada
- 3. Overview ● Banking / Financial Institutes plays a significant role in providing financial service. ● To maintain the integrity, bank/institute must be careful when investing in customers to avoid financial loss. ● Before giving credit to borrowers, the bank must come to about the potential of customers. ● The term credit scoring, determines the relation between defaulters and loan characteristics.
- 4. Goal ● The model we built here will use all possible factors to predict data on customers to find who are defaulters and non-defaulters next month. ● The goal is to find the whether the clients are able to pay their next month credit amount. ● Identify some potential customers for the bank who can settle their credit balance. ● To determine if their customers could make the credit card payments on-time. ● Default is the failure to pay interest or principal on a loan or credit card payment.
- 5. Process Design ● The process is done by Supervised learning Algorithm. ● The idea behind using this is we have a prior knowledge on our output values. ● It acts as a guide to teach the algorithms what conclusion it should come up with. ● Common algorithms in supervised learning includes logistic regression, naive bayes, support vector machines and decision tree classifier.
- 6. Approach Design Preparation of data Applying models Comparing the applied models Evaluation Model Analyse the Best model
- 8. Dataset Overview ● Oriented: UCI Machine Learning Repository. (Link) ● Attributes: 24 ● Tuples: 30,000 Customers data Customers data
- 9. Continue… Independent variables: • Customer ID • Credit limit • Gender • Age • Marital status • Level of education • History of their past payments made (April to September) (g1 to g6) • Amount of bill statement (h1 to h6) • Amount of previous payment (i1 to i6) Dependent variables: • default – A customer who will be default next month payment (0: no, 1: yes)
- 10. Dataset overview Graph shows total number of records for defaulters and non-defaulters. If they would do payment or not (yes=1 no=0) for next month 22% - default 78% - non-default (Screenshot: Taken during evaluation process)
- 11. Continue… 1. It shows count for ‘sex’ attribute 1 - Male and 2 - Female 2. It shows default count for ‘marriage’ attribute 0,3 - Others, 1 - Married, 2 - Single (Screenshot 1,2: Taken during evaluation process)
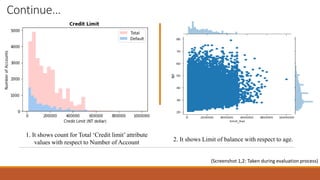
- 12. Continue… 2. It shows Limit of balance with respect to age. 1. It shows count for Total ‘Credit limit’ attribute values with respect to Number of Account (Screenshot 1,2: Taken during evaluation process)
- 14. Data Preprocessing ● Data set is divided in 60:40 ratio for train and test respectively. ● ID column was dropped as its unnecessary for our modeling. ● The attribute name ‘PAY_0’ was converted to ‘PAY_1’ for naming convenience. ● Pay_0: No consumption of credit card=-2, Pay duly(paid on time)=-1, payment delay for one month=1, payment delay for two months=2, payment delay for nine months and above=9. ● Marital Status 0 is converted to value 3 (Others). ● No Null values in dataset. ● Robust Scaler – It is used to convert variable in the same scale. Ex. in Limit Balance column there are different range of values which are converted in proper scale.
- 15. ● Education ● Gender ● Marital status Feature Engineering Education Value Graduate 1 University 2 High School 3 Others 4 Gender Value Male 1 Female 2 Marital Status Value - 0 Married 1 Single 2 Others 3
- 16. One-Hot Encoding ● The process in which Categorical variables are converted into a form, where we can apply algorithms to do prediction easily. ● (n-1) features ● Ex. There are 4 features in Education Converted to 3 features (n-1)
- 18. Proposed Models Logistic Regression •It is used for Binary classification. •Outputs have a nice probabilistic interpretation, and the algorithm can be regularized to avoid over fitting. •In logistic regression the hypothesis is that the conditional probability p of class belongs to ”1” •if probability is greater than threshold probability, generally 0.5, else it belongs to the class ”0”. •Ex. Y 𝑖 = ቊ 1 , 𝑝 ≥ 0.5 0, 𝑝 < 0.5 Support Vector Machine •Kernel: linear and enabled probability: ‘true’ •Soft-SVM search used in the process. •Hard-SVM searches for the decision boundary that separates the training data separately with the largest margin. •Soft-SVM is based on the assumption that learning data is not perfectly separable.
- 19. Continue… Feed Forward Neural Network •Feed forward NN is used with Backpropagation algorithm. Below parameters decided tuned parameters •Activation function : Rectified Linear Unit(ReLU) and Sigmoid •SGD: adam •Epochs: 100 •Loss function: Binary cross entropy •Input layer : 26, Hidden layer : 2, Output: 1 •Early Stopping Voting Classifier •Estimators: list of classifiers •Combined average of Logistic Regression + Decision tree Classifier + Support Vector Machine (SVM) Naïve Bayes, KNN and Decision Tree classifier
- 20. Evaluation Process Evaluation Metrics: ● Accuracy: Accuracy determine how often the model predicts default and non-default correctly. ● Precision: Precision calculates whenever our models predicts it is default how often it is correct. ● Recall: Recall regulate the actual default that the model is actually predict. ● Precision Recall Curve: PRC will display the tradeoff between precision and recall threshold. Cross Validation: ● K Fold cross validation; k = 5
- 21. Confusion Metrics True Positive – A person who is defaulter and predicted as defaulter. True Negative – A person who is non-defaulter and predicted as non-defaulter. False Positive – A person who is predicted defaulter is non-defaulter. False Negative – A person who is predicted non-defaulter is defaulter. # Non-defaulter (predicted) - 0 Defaulter (predicted) - 1 Non-defaulter (actual) - 0 TN FP Defaulter (actual) - 1 FN TP
- 23. Evaluation Result No. Algorithms Accuracy Precision Recall Confusion Metrix - Null 78 - - - 1 Logistic Regression 81.45 66.92 35.95 8927 419 1806 848 2 KNN 78.86 53.47 34.17 8557 789 1747 907 3 Naïve Byes 76.68 47.65 52.23 7736 1610 1188 1466 4 Classification Tree 78.46 52.09 32.81 8545 801 1783 871 5 SVM 81.66 63.99 39.11 8762 584 1616 1038 6 Feed Forward NN 75.65 33.91 40.74 8927 419 1806 848 7 Voting Classifier 83.95 67.49 32.83 8842 504 1822 832
- 24. Graphical representation Bar chart representation of Precision, Recall and Accuracy values
- 25. Precision-Recall curve Comparison of implemented algorithms with Precision-recall curve
- 26. Precision Recall curve with threshold ● Precision-Recall comparison with respect to the threshold value. ● Adjust precision and recall value by adjusting threshold value ● We set threshold value 0.2 ● False Negative value is improved by 40%.
- 28. Conclusion ● We investigated the data, checking for data unbalancing, visualizing the features and understanding the relationship between different features. ● We used both train-validation split and cross-validation to evaluate the model effectiveness to predict the target value, i.e. detecting if a credit card client will default next month. ● We then investigated five predictive models: ○ We started with Logistic Regression, Naïve bayes, SVM, KNN, Classification Tree and Feed-forward NN and Voting classifier accuracy is almost same. ○ We choose based model based on minimum value of False Negative value. ○ This would also inform the issuer’s decisions on who to give a credit card to and what credit limit to provide.
- 30. Demo
- 31. QR Code S C A N Q R C O D E A N D A C C ES S P P T A N D C O D E ( A C C E S S T H E C O D E : H T T P : / / V A T S A L S H A H . I N / P R O J E C T S . H T M L )
- 32. References ● Li, Xiao-Lin, and Yu Zhong. An overview of personal credit scoring: techniques and future work. Journal: International Journal of Intelligence Science ISSN 2163-0283. 2012. ● Federal Reserve. (2017) “Report to the Congress on the Profitability of Credit Card Operations of Depository Institutions”. ● Taiwo Oladipupo Ayodele. (2010) “Types of Machine Learning Algorithms”, New Advances In Machine Learning, Yagang Zhang (Ed.), Intech ● Default Credit Card Clients Dataset, https://www.kaggle.com/uciml/default-of-credit-card-clients-dataset/ ● Davis J., Goadrich M. The Relationship Between Precision-Recall and ROC Curves. ACM New York, NY, USA 2006. ISBN:1-59593-383-2. ● Arlot, Sylvain, and Alain Celisse. A survey of cross-validation procedures for model selection. eprint arXiv:0907.4728. DOI:10.1214/09-SS054. ● https://www.analyticsvidhya.com/blog/2016/03/introduction-deep-learning-fundamentals-neural- networks/
- 34. Contact Us You can share your feedback on below Email-IDs. ● Hetarth Bhatt – hbhatt7@uwo.ca ● Khushali Patel – kpate372@uwo.ca ● Rajaraman Ganesan – rganesa@uwo.ca ● Vatsal Shah – vshh56@uwo.ca (http://vatsalshah.in)
- 35. THANK YOU