February 2016 HUG: Running Spark Clusters in Containers with Docker

This session will examine the many options the data scientist has for running Spark clusters in public and private clouds. We will discuss various environments employing AWS, Mesos, containers, docker, and BlueData EPIC technologies and the benefits and challenges of each. Speakers: Tom Phelan, Co-founder and Chief Architect - BlueData Inc. Tom has spent the last 25 years as a senior architect, developer, and team lead in the computer software industry in Silicon Valley. Prior to co-founding BlueData, Tom spent 10 years at VMware as a senior architect and team lead in the core R&D Storage and Availability group. Most recently, Tom led one of the key projects – vFlash, focusing on integration of server-based Flash into the vSphere core hypervisor. Prior to VMware, Tom was part of the early team at Silicon Graphics that developed XFS, one of the most successful open source file systems. Earlier in his career, he was a key member of the Stratus team that ported the Unix operating system to their highly available computing platform. Tom received his Computer Science degree from the University of California, Berkeley.






























February 2016 HUG: Running Spark Clusters in Containers with Docker
- 1. Running spark Clusters in Containers with Docker Hadoop Users Group Meetup February 17, 2016 Tom Phelan tap@bluedata.com Nanda Vijaydev nanda@bluedata.com
- 2. Outline • Vocabulary • Big Data New Realities • Apache Spark • Anatomy of a Spark Cluster • Deployment Options • Monolithic • Microservices • Trade-Offs and Choices
- 3. Vocabulary • Bare-Metal • Virtual Machine (VM) • Docker • Container • Spark
- 4. Big Data Deployment Options Source: Enterprise Strategy Group (ESG) Survey, 2015
- 5. Spark Adoption a. Get started with Spark for initial use cases and users b. Evaluation, testing, development, and QA c. Prototype multiple data pipelines quickly a. Spin up dev/test clusters with replica image of production b. QA/UAT using production data without duplication c. Offload specific users and workloads from production a. LOB multi-tenancy with strict resource allocations b. Bare-metal performance for business critical workloads c. Self-service, shared infrastructure with strict access controls Prototyping Departmental Spark-as-a-Service Dev/Test and Pre-Production Spark in a Secure Production Environment Multi-Tenant Spark Deployment On-Premises
- 6. New Realities, New Requirements • Software flexibility - Multiple distros, Hadoop and Spark, multiple configurations - Support new versions and apps as soon as they are available • Multi-tenant support - Data access and network security - Differential Quality of Service (QoS) • Stability, Scalability, Cost, performance, and security are always important
- 7. APACHE SPARK - ANATOMY OF A SPARK CLUSTER
- 9. Common Deployment Patterns 48% Standalone mode 40% YARN 11% Mesos Most Common Spark Deployment Environments (Cluster Managers) Source: Spark Survey Report, 2015 (Databricks)
- 11. APACHE SPARK - DEPLOYMENT OPTIONS
- 12. Spark Single Cluster – Native Bare MetalBare MetalBare MetalBare MetalBare MetalBare Metal Bare MetalBare MetalSpark Client Spark Master Spark Slave tasktask task Spark Slave tasktask task Spark Slave tasktask task Virtual Machine Virtual Machine Virtual Machine Virtual Machine
- 13. Spark Single Cluster – YARN Node Manager Node Manager Node Manager Spark Executor tasktask task Spark Executor tasktask task Spark Executor tasktask task Spark Client Spark Master Resource Manager
- 14. Spark MultiCluster + YARN (monolithic) ControllerController WorkerWorker WorkerWorker ControllerController WorkerWorker WorkerWorker
- 15. Spark Cluster – Mesos Mesos Slave Mesos Slave Mesos Slave Spark Executor tasktask task Spark Executor tasktask task Spark Executor tasktask task Mesos Master Spark Scheduler Spark Client
- 16. Spark Cluster – Mesos Mesos Slave Mesos Slave Mesos Slave Spark Executor tasktask task Spark Executor tasktask task Spark Executor tasktask task Mesos Master Spark Scheduler Spark Client Spark Framework for Mesos Spark Framework for Mesos
- 17. Spark Cluster – Mesos Mesos Slave Mesos Slave Mesos Slave Spark Executor tasktask task Spark Executor tasktask task Spark Executor tasktask task Mesos Master Spark Scheduler Spark Client
- 18. Mesos MasterMesos Master Mesos Slave #1Mesos Slave #1 Mesos Slave #2Mesos Slave #2 Mesos Scheduler Mesos Scheduler Mesos ExecMesos Exec Mesos Scheduler Mesos Scheduler Mesos Scheduler Mesos Scheduler Container Data Node Container Data Node Container Data Node Container Data Node Mesos ExecMesos Exec Name NodeName Node Marathon Scheduler Marathon Scheduler Mesos ExecMesos Exec Container Task Container Task Mesos ExecMesos Exec Mesos ExecMesos Exec Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Spark + Docker + Mesos (microservice)
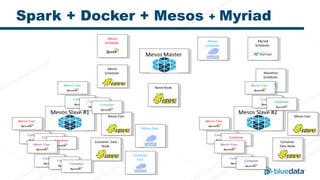
- 19. Mesos MasterMesos Master Mesos Slave #1Mesos Slave #1 Mesos Slave #2Mesos Slave #2 Mesos Scheduler Mesos Scheduler Mesos Scheduler Mesos Scheduler Mesos Scheduler Mesos Scheduler Container Data Node Container Data Node Container Data Node Container Data Node Mesos ExecMesos Exec Name NodeName Node Marathon Scheduler Marathon Scheduler Mesos ExecMesos Exec Container Task Container Task Mesos ExecMesos Exec Mesos ExecMesos Exec Mesos ExecMesos Exec Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Spark + Docker + Mesos + Myriad Mesos ExecMesos Exec Mesos ExecMesos Exec Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Mesos ExecMesos Exec Mesos ExecMesos Exec Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Myriad Scheduler Myriad Scheduler
- 20. Mesos MasterMesos Master Mesos Slave #1Mesos Slave #1 Mesos Slave #2Mesos Slave #2 Mesos Scheduler Mesos Scheduler Mesos ExecMesos Exec Mesos Scheduler Mesos Scheduler Mesos Scheduler Mesos Scheduler Container Data Node Container Data Node Container Data Node Container Data Node Mesos ExecMesos Exec Name NodeName Node Marathon Scheduler Marathon Scheduler Mesos ExecMesos Exec Container Task Container Task Mesos ExecMesos Exec Mesos ExecMesos Exec Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task Container Task JobJob TaskTask TaskTask TaskTask Spark + Docker + Mesos (microservice) Myriad Scheduler Myriad Scheduler
- 22. • Amazon EC2 Elastic Container Service (ECS) - Launch containers on EC2 - Amazon Elastic Container Registry (ECR): Docker Images • Amazon Elastic MapReduce (EMR) - Easy to use - Low startup costs: Hardware and human - Expandable Spark-as-a-Service/Public Cloud
- 23. • Data access - Already exists in S3 - Ingest time • Data security • Software versions - Spark 1.6.0, Hadoop 2.71; MapR • Cost - Short running vs. long running clusters Spark-as-a-Service/Public Cloud
- 24. • Easy to set up a dev/demonstration environment - Mesos framework for Spark available - Container isolation - Most of the pieces are available • Complete control - Customization - Docker files - Bring your own BI/analytics tool Spark + Docker w/ Microservices
- 25. • Can be difficult to set up a production environment - Multi-tenancy, QoS - Software interoperability - Container cluster network connectivity and security Spark + Docker w/ Microservices
- 26. • Docker packaging of images - Distribution agnostic - With or without YARN - Bring your own BI/analytics tool - Less overhead than virtual machines Spark + Docker w/ Monolithic
- 27. • Multi-tenancy - Per tenant QoS, - Limit Data Access Spark + Docker + w/ Monolithic
- 28. • Enterprise features (depending on implementation) - Deployment flexibility (on physical servers or VMs) - Network connectivity - Private VLAN per Tenant - Persistent IP addresses - Externally visible IP addresses - No NATing required Spark + Docker w/ Monolithic
- 29. Open Source Less Stable Less Cost Proprietary More Stable More Cost On-Premises Less Later More Now Public Cloud More Later Less Now Trade-Offs (Not Unique to Spark)
- 30. • Just Spark, Just Works, no Customizations – Public Cloud or SaaS • Lots of Customizations, Willing to Tinker, Limited QoS – Microservice container deployment • Configurable, Flexible, Enterprise Multi-Tenancy – Monolithic container deployment Use Cases Choice of Deployment
- 31. Thank You www.bluedata.com Try BlueData EPIC for Free: bluedata.com/free