February 2017 HUG: Exactly-once end-to-end processing with Apache Apex

Apache Apex (http://apex.apache.org/) is a stream processing platform that helps organizations to build processing pipelines with fault tolerance and strong processing guarantees. It was built to support low processing latency, high throughput, scalability, interoperability, high availability and security. The platform comes with Malhar library - an extensive collection of processing operators and a wide range of input and output connectors for out-of-the-box integration with an existing infrastructure. In the talk I am going to describe how connectors together with the distributed checkpointing (a mechanism used by the Apex to support fault tolerance and high availability) provide exactly-once end-to-end processing guarantees. Speakers: Vlad Rozov is Apache Apex PMC member and back-end engineer at DataTorrent where he focuses on the buffer server, Apex platform network layer, benchmarks and optimizing the core components for low latency and high throughput. Prior to DataTorrent Vlad worked on distributed BI platform at Huawei and on multi-dimensional database (OLAP) at Hyperion Solutions and Oracle.















February 2017 HUG: Exactly-once end-to-end processing with Apache Apex
- 1. Exactly-Once End-To-End Processing with Apache Apex 55th Bay Area Hadoop User Group (HUG) Meetup February 15, 2017
- 2. Vlad Rozov Apache Apex PMC vrozov@apache.org http://github.com/vrozov Engineer at DataTorrent v.rozov@datatorrent.com CoD fan About me
- 3. http://www.apexbigdata.com Computer History Museum April 4, 2017 Apex Big Data World - San Jose
- 4. Apache Apex Platform Features • In-memory, distributed stream processing ᵒ Application logic broken into components (operators) that execute distributed in a cluster ᵒ Unobtrusive Java API to express (custom) logic ᵒ Maintain state and metrics in member variables ᵒ Windowing, event-time processing • Scalable, high throughput, low latency ᵒ Operators can be scaled up or down at runtime according to the load and SLA ᵒ Dynamic scaling (elasticity), compute locality • Fault tolerance & correctness ᵒ Automatically recover from node outages without having to reprocess from beginning ᵒ State is preserved, checkpointing, incremental recovery ᵒ End-to-end exactly-once • Operability ᵒ System and application metrics, record/visualize data ᵒ Dynamic changes and resource allocation, elasticity
- 5. Apache Apex Platform Overview
- 6. Fault Tolerance • Operator state is checkpointed to persistent store ᵒ Automatically performed by engine, no additional coding needed ᵒ Asynchronous and distributed ᵒ In case of failure operators are restarted from checkpoint state • Automatic detection and recovery of failed containers ᵒ Heartbeat mechanism ᵒ YARN process status notification • Buffering to enable replay of data from recovered point ᵒ Fast, incremental recovery, spike handling • Application master state checkpointed ᵒ Snapshot of physical (and logical) plan ᵒ Execution layer change log
- 7. Checkpointing Operator State • Save state of operator so that it can be recovered on failure • Pluggable storage handler • Default implementation ᵒ Serialization with Kryo ᵒ All non-transient fields serialized ᵒ Serialized state written to HDFS ᵒ Writes asynchronous, non-blocking • Possible to implement custom handlers for alternative approach to extract state or different storage backend (such as IMDG) • For operators that rely on previous state for computation operators can be marked @Stateless to skip checkpointing • Checkpoint frequency tunable (by default 30s) ᵒ Based on streaming windows for consistent state
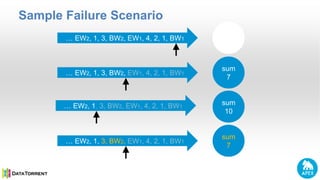
- 8. Sample Failure Scenario … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 sum 0 … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 sum 7 … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 … EW2, 1, 3, BW2, EW1, 4, 2, 1, BW1 sum 7 sum 10
- 9. At most once At least once Exactly once Subscribes to data from the start of the next window. Operator brought back to its latest checkpointed state and the upstream buffer server replays all subsequent windows Operator brought back to its latest checkpointed state and the upstream buffer server replays all subsequent windows Ignore the lost windows and continue to process incoming data normally. Lost windows are recomputed & application catches up live incoming data Lost windows are recomputed in a logical way to have the effect as if computation has been done exactly once. No duplicates & no recomputation Likely duplicates & recomputation No duplicates & recomputation? Possible missing data No lost data No lost data Processing Guarantees
- 10. End-to-End Exactly Once • Becomes important when writing to external systems • Data should not be duplicated or lost in the external system even in case of application failures • Common external systems ᵒ Databases ᵒ Files ᵒ Message queues • Platform support for at least once is a must so that no data is lost • Data duplication must still be avoided when data is replayed from checkpoint ᵒ Operators implement the logic dependent on the external system • Aid of platform features such as stateful checkpointing and windowing • Three different mechanisms with implementations explained in next slides
- 11. Files Streaming data is being written to file on a continuous basis Failure at a random point results in file with an unknown amount of data Operator works with platform to ensure exactly once • Platform responsibility ᵒ Restores state and restarts operator from an earlier checkpoint ᵒ Platform replays data from the exact point after checkpoint • Operator responsibility ᵒ Replayed data doesn’t get duplicated in the file ᵒ Accomplishes by keeping track of file offset as state Existing implementation from Malhar Library AbstractFileOutputOperator.java
- 12. Exactly Once Strategy File Data Offset Ensures no data is duplicated or lost Chk Operator saves file offset during checkpoint File contents are flushed before checkpoint to ensure there is no pending data in buffer On recovery platform restores the file offset value from checkpoint Operator truncates the file to the offset Starts writing data again
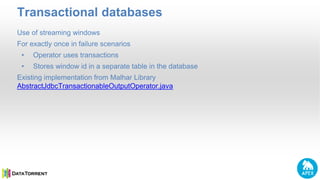
- 13. Transactional databases 13 Use of streaming windows For exactly once in failure scenarios • Operator uses transactions • Stores window id in a separate table in the database Existing implementation from Malhar Library AbstractJdbcTransactionableOutputOperator.java
- 14. Exactly Once Strategy d11 d12 d13 d21 d22 d23 lwn1 lwn2 lwn3 op-id wn chk wn wn+1 Lwn+11 Lwn+12 Lwn+13 op-id wn+1 Data Table Meta Table Data in a window is written out in a single transaction Window id is also written to a meta table as part of the same transaction Operator reads the window id from meta table on recovery Ignores data for windows less than the recovered window id and writes new data Partial window data before failure will not appear in data table as transaction was not committed Assumes idempotency for replay
- 15. Stateful Message Queue 15 Data is being sent to a stateful message queue like Apache Kafka On failure data already sent to message queue should not be re-sent Exactly once strategy • Sends a key along with data that is monotonically increasing • On recovery operator asks the message queue for the last sent message • Gets the recovery key from the message • Ignores all replayed data with key that is less than or equal to the recovered key • If the key is not monotonically increasing then data can be sorted on the key at the end of the window and sent to message queue Existing implementation from Malhar Library: AbstractExactlyOnceKafkaOutputOperator.java
- 16. Resources Apache Apex - http://apex.apache.org/ Subscribe to forums Apex - http://apex.apache.org/community.html DataTorrent - https://groups.google.com/forum/#!forum/dt-users Download - https://datatorrent.com/download/ Twitter @ApacheApex; Follow - https://twitter.com/apacheapex @DataTorrent; Follow - https://twitter.com/datatorrent Meetups - http://meetup.com/topics/apache-apex Webinars - https://datatorrent.com/webinars/ Videos - https://youtube.com/user/DataTorrent Slides - http://slideshare.net/DataTorrent/presentations Startup Accelerator - Free full featured enterprise product https://datatorrent.com/product/startup-accelerator/ Big Data Application Templates Hub - https://datatorrent.com/apphub
- 17. Questions?