






























Free Training: How to Build a Lakehouse
- 1. How to build a Lakehouse Instructor: Doug Bateman
- 2. About Your Instructor ▪ Principal Data Engineering Instructor at Databricks ▪ Joined Databricks in 2016 ▪ 20+ Years of Industry Experience Doug Bateman
- 3. About Your Instructor (Personal) ▪ Two children ▪ 2 and 5 years old ▪ For fun: ▪ Sailing ▪ Rock Climbing ▪ Snowboarding (badly) ▪ Chess (badly) Doug Bateman
- 4. The global event for the data community ● Keep up with the latest advances in open source technologies like Apache Spark™, Delta Lake, MLflow and Koalas ● Level up your knowledge with 200+ highly technical sessions presented by leading experts from industry, research and academia ● Featured keynotes from industry thought leaders and luminaries like Malala Yousafzai, Matei Zaharia, the 2020 Mars Rover team, DJ Patil, Bill Nye and more ● Choose from 23 hands on training sessions lead by industry experts May 24-28 REGISTER TODAY
- 5. Course goals Describe key features of a data Lakehouse Explain how Delta Lake enables a Lakehouse architecture 1 2 3 Develop a sample Lakehouse using Databricks
- 6. Course Agenda Activity Course welcome Introduction to Lakehouse Architecture Delta Lake Create your own Lakehouse Question and Answers Wrap up
- 8. Access the Self-Paced Version of this Webinar https://tinyurl.com/how-to-build-a-lakehouse
- 9. Access the Lab Environment* *Available to Live Attendees Only. If you’re watching a recording, you can instead use: https://community.cloud.databricks.com/
- 11. Introduction to Lakehouse Architecture
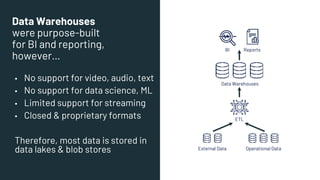
- 13. Data Warehouses were purpose-built for BI and reporting, however… ▪ No support for video, audio, text ▪ No support for data science, ML ▪ Limited support for streaming ▪ Closed & proprietary formats Therefore, most data is stored in data lakes & blob stores ETL External Data Operational Data Data Warehouses BI Reports
- 14. Data Lakes could store all your data and determine what you want to know later ▪ Poor BI support ▪ Complex to set up ▪ Poor performance ▪ Unreliable data swamps BI Data Science Machine Learning Structured, Semi-Structured and Unstructured Data Data Lake Real-Time Database Reports Data Warehouses Data Prep and Validation ETL
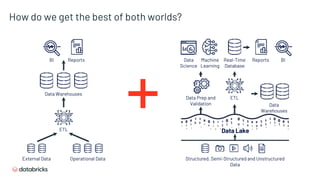
- 15. How do we get the best of both worlds? BI Data Science Machine Learning Structured, Semi-Structured and Unstructured Data Data Lake Real-Time Database Reports Data Warehouses Data Prep and Validation ETL ETL External Data Operational Data Data Warehouses BI Reports
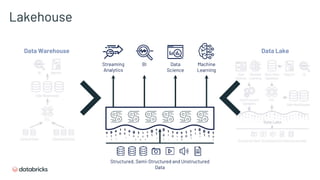
- 16. Lakehouse Data Warehouse Data Lake Streaming Analytics BI Data Science Machine Learning Structured, Semi-Structured and Unstructured Data
- 17. Lakehouse Summary A Lakehouse has the following key features: ● support for diverse data types and formats ● data reliability and consistency ● support for diverse workloads (BI, data science, machine learning, and analytics) ● ability to use BI tools directly on source data
- 18. The core components we need to build a Lakehouse Building a Lakehouse 1. Your data lake (cloud blob storage, open source format) 2. A powerful engine to query blob storage and open-source formats (Spark) 3. Transaction layer to provide consistency (DeltaLakes) 4. ETL and data cleansing workflow (Databricks Delta Pipelines) 5. Security, data integrity, and performance (Databricks Delta Engine) 6. As well as integrations for all of your user communities: a. SQL (Databricks SQL Analytics) b. BI tools and dashboards c. ML d. Streaming
- 19. Delta Lake
- 20. Really cheap, durable storage 10 nines of durability. Cheap. Infinite scale. The Emergence of Data Lakes Store all types of raw data Video, audio, text, structured, unstructured Open, standardized formats Parquet format, big ecosystem of tools operate on these file formats
- 21. Challenges with data lakes 1. Hard to append data Adding newly arrived data leads to incorrect reads 2. Modification of existing data is difficult GDPR/CCPA requires making fine grained changes to existing data lake 3. Jobs failing mid way Half of the data appears in the data lake, the rest is missing
- 22. Challenges with data lakes 4. Real-time operations Mixing streaming and batch leads to inconsistency 5. Costly to keep historical versions of the data Regulated environments require reproducibility, auditing, governance 6. Difficult to handle large metadata For large data lakes the metadata itself becomes difficult to manage
- 23. Challenges with data lakes 7. “Too many files” problems Data lakes are not great at handling millions of small files 8. Hard to get great performance Partitioning the data for performance is error-prone and difficult to change 9. Data quality issues It’s a constant headache to ensure that all the data is correct and high quality
- 24. A new standard for building data lakes An opinionated approach to building Data Lakes ■ Adds reliability, quality, performance to Data Lakes ■ Brings the best of data warehousing and data lakes ■ Based on open source and open format (Parquet) - Delta Lake is also open source
- 25. 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues
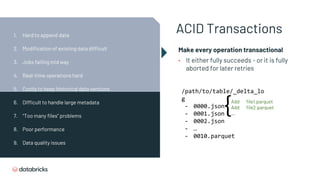
- 26. ACID Transactions Make every operation transactional • It either fully succeeds - or it is fully aborted for later retries /path/to/table/_delta_lo g - 0000.json - 0001.json - 0002.json - … - 0010.parquet 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues
- 27. ACID Transactions Make every operation transactional • It either fully succeeds - or it is fully aborted for later retries /path/to/table/_delta_lo g - 0000.json - 0001.json - 0002.json - … - 0010.parquet {Add file1.parquet Add file2.parquet ... 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues
- 28. ACID Transactions Make every operation transactional • It either fully succeeds - or it is fully aborted for later retries /path/to/table/_delta_lo g - 0000.json - 0001.json - 0002.json - … - 0010.parquet {Remove file1.parquet Add file3.parquet ... 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues
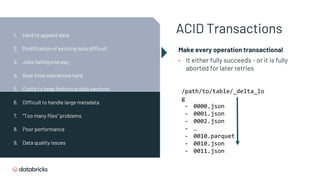
- 29. ACID Transactions Make every operation transactional • It either fully succeeds - or it is fully aborted for later retries /path/to/table/_delta_lo g - 0000.json - 0001.json - 0002.json - … - 0010.parquet - 0010.json - 0011.json 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues
- 30. ACID Transactions Make every operation transactional • It either fully succeeds - or it is fully aborted for later retries Review past transactions • All transactions are recorded and you can go back in time to review previous versions of the data (i.e. time travel) SELECT * FROM events TIMESTAMP AS OF ... SELECT * FROM events VERSION AS OF ... 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues
- 31. Spark under the hood • Spark is built for handling large amounts of data • All Delta Lake metadata stored in open Parquet format • Portions of it cached and optimized for fast access • Data and it’s metadata always co-exist. No need to keep catalog<>data in sync 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues
- 32. File Consolidation Automatically optimize a layout that enables fast access • Partitioning: layout for typical queries • Data skipping: prune files based on statistics on numericals • Z-ordering: layout to optimize multiple columns 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues OPTIMIZE events ZORDER BY (eventType)
- 33. Schema validation Schema validation and evolution • All data in Delta Tables have to adhere to a strict schema (star, etc) • Includes schema evolution in merge operations 1. Hard to append data 2. Modification of existing data difficult 3. Jobs failing mid way 4. Real-time operations hard 5. Costly to keep historical data versions 6. Difficult to handle large metadata 7. “Too many files” problems 8. Poor performance 9. Data quality issues MERGE INTO events USING changes ON events.id = changes.id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT *
- 34. Delta Lake Summary ▪ Core component of a Lakehouse architecture ▪ Offers guaranteed consistency because it's ACID compliant ▪ Robust data store ▪ Designed to work with Apache Spark
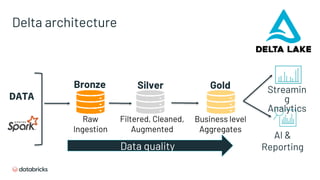
- 35. Delta architecture AI & Reporting Streamin g Analytics Bronze Silver Gold Data quality DATA Raw Ingestion Filtered, Cleaned, Augmented Business level Aggregates
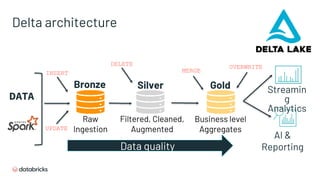
- 36. Delta architecture AI & Reporting Streamin g Analytics Bronze Silver Gold Data quality DATA Raw Ingestion Filtered, Cleaned, Augmented Business level Aggregates UPDATE DELETE MERGE OVERWRITE INSERT
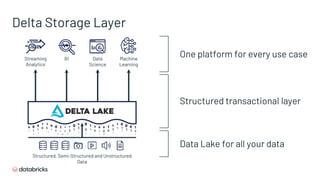
- 37. Delta Storage Layer Streaming Analytics BI Data Science Machine Learning Structured, Semi-Structured and Unstructured Data Data Lake for all your data One platform for every use case Structured transactional layer
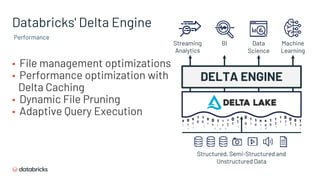
- 38. Databricks' Delta Engine ▪ File management optimizations ▪ Performance optimization with Delta Caching ▪ Dynamic File Pruning ▪ Adaptive Query Execution DELTA ENGINE Streaming Analytics BI Data Science Machine Learning Structured, Semi-Structured and Unstructured Data Performance
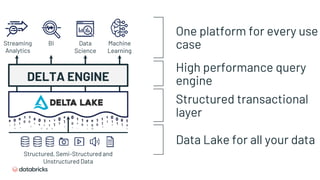
- 39. High performance query engine DELTA ENGINE One platform for every use case Streaming Analytics BI Data Science Machine Learning Data Lake for all your data Structured, Semi-Structured and Unstructured Data Structured transactional layer
- 40. How to Create a Lakehouse - Demo
- 41. The global event for the data community ● Keep up with the latest advances in open source technologies like Apache Spark™, Delta Lake, MLflow and Koalas ● Level up your knowledge with 200+ highly technical sessions presented by leading experts from industry, research and academia ● Featured keynotes from industry thought leaders and luminaries like Malala Yousafzai, Matei Zaharia, the 2020 Mars Rover team, DJ Patil, Bill Nye and more ● Choose from 23 hands on training sessions lead by industry experts May 24-28 REGISTER TODAY
- 42. Questions and Answers Thanks for Coming!