Fundamentals of Apache Kafka
•
7 likes•1,532 views

Kafka's basic terminologies, its architecture, its protocol and how it works. Kafka at scale, its caveats, guarantees and use cases offered by it. How we use it @ZaprMediaLabs.
Report
Share





















































Fundamentals of Apache Kafka
- 1. ZAPR MEDIA LABS Presented by: Chhavi Parasher and Ankit Timbadia
- 2. Agenda ● What is Apache Kafka? ● Why Apache Kafka? ● Fundamentals ○ Terminologies ○ Architecture ○ Protocol ● What does kafka offer? ● Where Kafka is used?
- 3. What is Apache Kafka?
- 4. What is kafka “A high throughput distributed pub-sub messaging system.
- 5. What is kafka “A pub-sub messaging system rethought as a distributed commit log storage.”
- 7. Why Kafka Client Source Data Pipelines Start like this.
- 8. Why Kafka Client Source Client Client Client Then we reuse them
- 9. Why Kafka Client Backend1 Client Client Client Then we add additional endpoints to the existing sources Backend2
- 10. Why Kafka Client Backend1 Client Client Client Then it starts to look like this Backend2 Backend3 Backend4
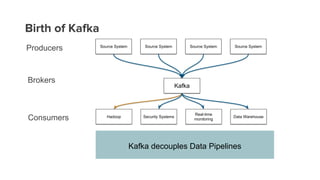
- 11. Birth of Kafka Kafka decouples Data Pipelines Source System Source System Source System Source System Hadoop Security Systems Real-time monitoring Data Warehouse Kafka Producers Brokers Consumers
- 13. Terminologies
- 14. Terminologies • Topic is a message stream (queue) • Partitions - Topic is divided into partitions • Ordered, immutable, a structured commit log • Segments - Partition has log segments on disk • Partitions broken down into physical files. • Offset - Segment has messages • Each message is assigned a sequential id
- 15. Anatomy of a topic 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 0 1 2 3 4 5 6 7 8 9 1 0 1 1 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 Partition 1 Partition 2 Partition 3 Writes Old New Segment1 Segment2
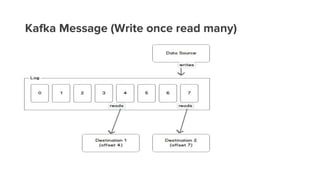
- 16. Kafka Message (Write once read many)
- 17. Partitions and Brokers • Each broker can be a leader or a replica for a partition • All writes & reads to a topic go through the leader
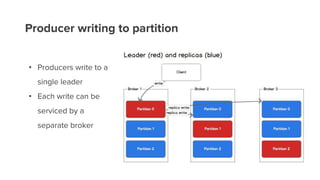
- 18. Producer writing to partition • Producers write to a single leader • Each write can be serviced by a separate broker
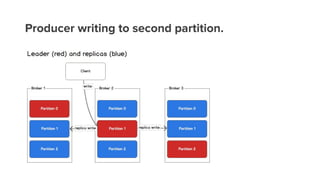
- 19. Producer writing to second partition.
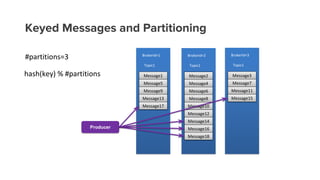
- 20. Keyed Messages and Partitioning Producer
- 21. Partitioning Distributes clients across consumers Consumer Consumer Consumer Consumer Consumer Consumer Consumer Producer Producer Producer Producer Producer
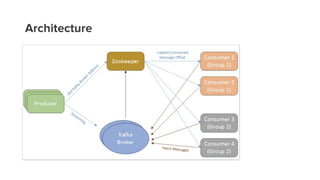
- 22. Architecture
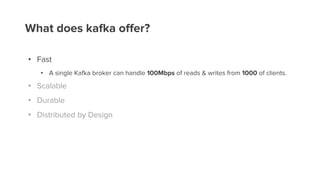
- 23. What does kafka offer?
- 24. What does kafka offer? • Fast • Scalable • Durable • Distributed by Design
- 25. What does kafka offer? • Fast • A single Kafka broker can handle 100Mbps of reads & writes from 1000 of clients. • Scalable • Durable • Distributed by Design
- 26. What does kafka offer? • Fast • Scalable • Data streams are partitioned and spread over a cluster of machines to allow data streams larger than the capability of any single machine • Durable • Distributed by Design
- 27. What does kafka offer? • Fast • Scalable • Durable • Messages are persisted on disk and replicated within the cluster to prevent data loss. Each broker can handle terabytes of messages without performance impact. • Distributed by Design
- 28. What does kafka offer • Fast • Scalable • Durable • Distributed by Design • Kafka has a modern cluster-centric design that offers strong durability and fault-tolerance guarantees.
- 29. Efficiency - high throughput & low latency • Disks are fast when used sequentially • Append to end of log. • Fetch messages from a partition beginning from a particular message id. • Batching makes best use of network/IO • Batched send and receive • Batched compression (GZIP, Snappy and LZ4)
- 30. Efficiency - high throughput & low latency • No message caching in JVM • Zero-copy from file to socket (Java NIO)
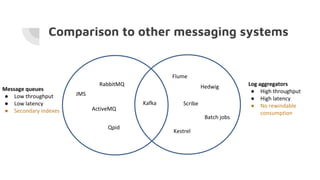
- 31. ● ● ● ● ● ● Comparison to other messaging systems
- 32. Where is Kafka used?
- 33. Who uses Apache Kafka?
- 34. What do people use it for? • Activity tracking • page views or click tracking, profile updates • Real-time event processing • Provides low latency • Good integration with spark, samza. storm etc. • Collecting Operational Metrics • Monitoring & alerting • Commit log • database changes can be published to Kafka
- 35. Why Replication? • Broker can go down • controlled: rolling restart for code/config push • uncontrolled: isolated broker failure • If broker is down • some partitions are unavailable • could be permanent data loss • Replication ensures higher availability & durability
- 36. Caveats • Not designed for large payloads. • Decoding is done for a whole message (no streaming decoding). • Rebalancing can screw things up. • if you're doing any aggregation in the consumer by the partition key • Number of partitions cannot be easily changed (chose wisely). • Lots of topics can hurt I/O performance.
- 37. Guarantees • At least once delivery • In order delivery, per partition • For a topic with replication factor N, Kafka can tolerate up to N-1 server failures without “losing” any messages committed to the log
- 38. Summary • A high throughput distributed messaging system rethought as commit log • Originally developed by LinkedIn, Open Sourced in 2011 • Written in Scala, Clients for every popular language • Used by LinkedIn, Twitter, Netflix and many more companies. • When should we use Kafka ? • When should we not use kafka?
- 39. Kafka in Production @ Zapr
- 40. Agenda • Kafka Clusters at @Zapr • Kafka in AWS • Challenges Managing Kafka Brokers. • Monitoring of Kafka Clusters.
- 41. Kafka Version: 0.8.2 Total Kafka Clusters: 5 Number of Topics: 185 Brokers: 17 Partitions: 7827 Regions: 2 (us-east-1,ap-southeast-1) Kafka at Zapr
- 42. Kafka Clusters on Amazon Web Services. Quorum of 3 Zookeeper Nodes for High Availability Kafka Brokers
- 43. Resource Utilization Family Type vCPU Memory CPU Pricing Compute Optimized C4.2xlarge 8 16 ~75% 338$ General Purpose M4.2xlarge 8 32 ~25% 366$ After moving from C4 Class to M4 Class Machines 40% Improvement in CPU Usage
- 44. Production Kafka Broker Configurations
- 45. #Default Partitions and Replication Factor for Kafka Topics num.partitions=10 default.replication.factor=2 #Controlled shutdown for the proper shutdown of Kafka Broker for maintenance. num.recovery.threads.per.data.dir=4 controlled.shutdown.enable=true controlled.shutdown.max.retries=5 controlled.shutdown.retry.backoff.ms=60000 #Creation and Deletion of Kafka Topics delete.topic.enable=true auto.create.topics.enable=true Production Kafka Broker Configurations
- 46. Challenges
- 47. Dynamic Load • Kafka Scales Horizontally • For a topic, Kafka has N (Replicated Partitions) • Adding a Broker causes Partition to rebalanced
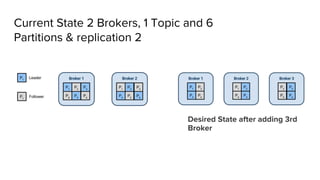
- 48. Current State 2 Brokers, 1 Topic and 6 Partitions & replication 2 Desired State after adding 3rd Broker
- 49. Kafka approach
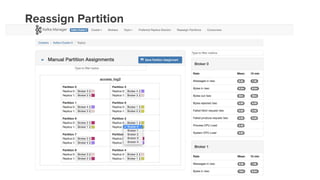
- 50. Introducing Kafka Manager https://github.com/yahoo/kafka-manager It supports the following : ● Manage multiple clusters. ● Easy inspection of cluster state (topics, consumers, offsets, brokers) ● Generate partition assignments with option to select brokers to use ● Run reassignment of partition (based on generated assignments) ● Create a topic with optional topic configs (0.8.1.1 has different configs than 0.8.2+) ● Delete topic (only supported on 0.8.2+ and remember set delete.topic.enable=true in broker config) ● Add partitions to existing topic ● Update config for existing topic ● Optionally enable JMX polling for broker level and topic level metrics.
- 51. Clusters
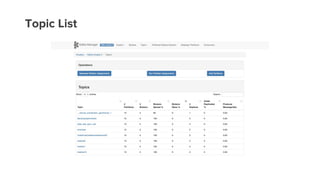
- 52. Topic List
- 53. Topic View
- 55. Broker List
- 56. Broker View
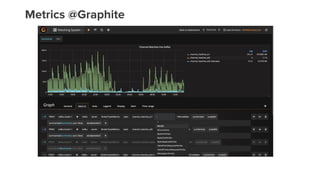
- 58. Monitoring
- 59. Kafka Graphite Metric Plugin https://github.com/damienclaveau/kafka-graphite #Graphite Reporter kafka.metrics.reporters=com.criteo.kafka.KafkaGraphiteM etricsReporter kafka.graphite.metrics.reporter.enabled=true kafka.metrics.polling.interval.secs = 60 kafka.graphite.metrics.host= graphite.zapr.com kafka.graphite.metrics.port=2003 kafka.graphite.metrics.group=PROD.kafka-cluster-1.10-0-1- 90
- 61. Kafka Offset Monitoring https://github.com/quantifind/KafkaOffsetMonitor ● This is an app to monitor your kafka consumers and their position (offset) in the queue. ● You can see the current consumer groups, for each group the topics that they are consuming ● Offset are useful to understand how quick you are consuming from a queue and how fast the queue is growing
- 63. Kafka offset monitoring @Graphite
- 64. Future plans • Upgrading EC2 instances to next generations from M4 to M5 • Upgrading Kafka Version from 0.8.2 to latest version (1.2) • Using ST1 (throughput optimized HDD) EBS
- 65. Thank you!