Getting Started with Splunk Enterprise
•
0 likes•199 views

What is Splunk? At the end of this session you’ll have a high-level understanding of the pieces that make up the Splunk Platform, how it works, and how it fits in the landscape of Big Data. You’ll see practical examples that differentiate Splunk while demonstrating how to gain quick time to value.















Getting Started with Splunk Enterprise
- 1. Copyright © 2015 Splunk Inc. Scott Henry Getting Started with Splunk Enterprise Scott Henry Sr Sales Engineer
- 2. 2 During the course of this presentation, we may make forward-looking statements regarding future events or the expected performance of the company. We caution you that such statements reflect our current expectations and estimates based on factors currently known to us and that actual events or results could differ materially. For important factors that may cause actual results to differ from those contained in our forward-looking statements, please review our filings with the SEC. The forward-looking statements made in this presentation are being made as of the time and date of its live presentation. If reviewed after its live presentation, this presentation may not contain current or accurate information. We do not assume any obligation to update any forward- looking statements we may make. In addition, any information about our roadmap outlines our general product direction and is subject to change at any time without notice. It is for informational purposes only and shall not be incorporated into any contract or other commitment. Splunk undertakes no obligation either to develop the features or functionality described or to include any such feature or functionality in a future release. Legal Notices
- 4. Our Plan of Action 4 1.Setting the stage. 2.How does Splunk fit in the landscape? 3.What differentiates Splunk? 4.Components that make up Splunk? 5.Demo - How it works?
- 5. 5 The Accelerating Pace of Data Volume | Velocity | Variety | Variability 5 GPS, RFID, Hypervisor, Web Servers, Email, Messaging, Clickstreams, Mobile, Telephony, IVR, Databases, Sensors, Telematics, Storage, Servers, Security Devices, Desktops Machine data is the fastest growing, most complex, most valuable area of big data
- 6. 6 Making machine data accessible, usable and valuable to everyone. 6
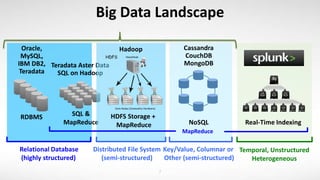
- 7. Big Data Landscape Key/Value, Columnar or Other (semi-structured) Cassandra CouchDB MongoDB NoSQL 7 Relational Database (highly structured) SQL & MapReduce RDBMS Oracle, MySQL, IBM DB2, Teradata Teradata Aster Data SQL on Hadoop Distributed File System (semi-structured) Hadoop HDFS Storage + MapReduce Temporal, Unstructured Heterogeneous Real-Time Indexing MapReduce
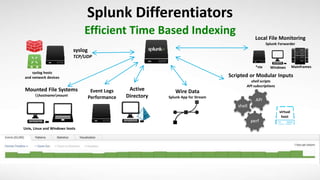
- 8. perf shell API Mounted File Systems hostnamemount syslog TCP/UDP Event Logs Performance Active Directory syslog hosts and network devices Unix, Linux and Windows hosts Local File Monitoring Splunk Forwarder virtual host Windows Scripted or Modular Inputs shell scripts API subscriptions Mainframes*nix Wire Data Splunk App for Stream Efficient Time Based Indexing Splunk Differentiators
- 9. Splunk Differentiators 10 • Role Based Access Control • Define roles and assign users to them. • Integrate with LDAP or SSO. • Centralized Access • Allows multiple users across the organization to securely leverage same instance with multiple data types. • Align data access to policies in the organization • Secure Data Transmission • Universal Forwarders provides easy, reliable, secure data collection from remote sources. • SSL security, data compression, configurable throttling and buffering.
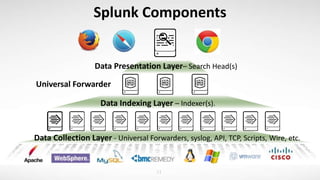
- 10. Splunk Components 11 Data Collection Layer - Universal Forwarders, syslog, API, TCP, Scripts, Wire, etc. Data Indexing Layer – Indexer(s). Data Presentation Layer– Search Head(s) Universal Forwarder
- 11. 1. 2. 3. 4. How to Get Started Download Install Forward Data Search Databases Networks Servers Virtual Machines Smart phones and Devices Custom Applications Security WebServer Sensors Four steps:
- 12. 13 Demo – How it Works 13 1. Installing and Starting Splunk 2. Ingesting Data 3. Search Basics • Search Bar • Time Picker • Extracted Fields 4. Dynamic Field Extraction 5. Alerting 6. Statistics and Reporting 7. Command Language 8. Splunk Applications
- 13. Demo 14
- 14. 15 Supplemental Information 15 Download • www.splunk.com/download Search Tutorial: • docs.splunk.com/Documentation/Splunk/latest/SearchTutorial Tutorial Data: • docs.splunk.com/images/Tutorial/tutorialdata.zip
- 15. 16 Education Resources 16 Splunk Education • www.splunk.com/education Using Splunk, Searching and Reporting, Developing Apps, Administering Splunk, and more! Books • Implementing Splunk: Big Data Essentials for Operational Intelligence • Splunk Essentials • Exploring Splunk • Splunk Operational Intelligence Cookbook
- 16. 17 Things to Remember 17 1. Splunk is Free – Download and get started today 2. Quick Time to Value 3. Data Gold Mines – what informational fortune awaits?! 4. Leverage the Splunk Community • splunkbase.splunk.com • answers.splunk.com • blogs.splunk.com 5. Happy Splunking!!
- 17. Questions?
- 18. Thank You
Editor's Notes
- Data is growing and embodies new characteristics not found in traditional structured data: Volume, Velocity, Variety, Variability. "Big data" is a term applied to these expanding data sets whose size is beyond the ability of commonly used software tools to capture, manage, and process the data within a tolerable elapsed time. Machine data is one of the fastest, growing, most complex and most valuable segments of big data and embodies new characteristics not found in traditional structured data terms of Volume, Velocity, Variety, Variability. All the webservers, applications, network devices – all of the technology infrastructure running an enterprise or organization – generates massive streams of data, digital exhaust per say. It comes in an array of unpredictable formats that are difficult to process and analyze by traditional methods or in a timely manner. So why is this “machine data” valuable? Because it contains a trace - a categorical record - of user behavior, cyber-security risks, application behavior, service levels, fraudulent activity and customer experiences.
- Splunk’s mission is to make YOUR machine data accessible, usable and valuable to everyone. It’s this overarching mission that drives our company and products that we deliver.
- How has big data evolved over time. For a long time, ‘big data’ was simply a large relational database. The database industry – in order to handle large data – moved to smaller databases, but many of them. Horizontal partitioning (Also known as Sharding) is a database design principle whereby rows of a database table are held separately (For example, A -> D in one database E -> H in a second database, etc ..) Hadoop was introduced by Google and was adapted as the de-facto big data system. Hadoop is an open source project from Apache that has evolved rapidly into a major technology movement. It has emerged as a popular way to handle massive amounts of data, including structured and complex unstructured data. Its popularity is due in part to its ability to store and process large amounts of data effectively across clusters of commodity hardware, particularly cheaply. Apache Hadoop is not actually a single product but instead a collection of several components. For the most part, Hadoop is a batch oriented system. ** Teradata Aster Data & SQL on Hadoop are SQL interface systems that can talk to Hadoop ** Cassandra & HBase are NoSQL databases that can process data using a Key / Value in real-time. Splunk = Temporal, Unstructured, Heterogeneous, real-time analytics platform. Besides relational databases, the technologies leverage a form of MapReduce – which is a programming model for processing and generating large data sets. So we’ll dig deeper in a bit to see what truly differentiates Splunk. Interesting thing to note, Splunk can also enrich your machine data with several types of external data sources, included are databases, Hadoop, and NoSQL data stores.
- How has big data evolved over time. For a long time, ‘big data’ was was simply a large database. The database industry – in order to handle large data – moved to smaller databases, but many of them. Horizontal partitioning (Also known as Sharding) is a database design principle whereby rows of a database table are held separately (For example, A -> D in one database E -> H in a second database, etc ..) Hadoop was introduced by Google and was adapted as the de-facto big data system. Hadoop is an open source project from Apache that has evolved rapidly into a major technology movement. It has emerged as a popular way to handle massive amounts of data, including structured and complex unstructured data. Its popularity is due in part to its ability to store and process large amounts of data effectively across clusters of commodity hardware, particularly cheaply. Apache Hadoop is not actually a single product but instead a collection of several components. For the most part, Hadoop is a batch oriented system. ** Teradata Aster Data & SQL on Hadoop are SQL interface systems that can talk to Hadoop ** Cassandra & HBase are NoSQL databases that can process data using a Key / Value in real-time. Splunk = Temporal, Unstructured, Heterogeneous, real-time analytics platform. Besides relational databases, the technologies leverage a form of MapReduce – which is a programming model for processing and generating large data sets. So we’ll dig deeper in a bit to see what truly differentiates Splunk. Splunk can also enrich your machine data with several types of external data sources, included are databases, Hadoop, and NoSQL data stores.
- Getting data into Splunk is designed to be as flexible and easy as possible. In most cases you’ll find that no configuration is required; you just have to determine what data to collect and which method you want to use to get it into Splunk. Splunk is THE universal machine data platform. It goes beyond ingesting just log files, ingesting data from syslog, scripts, system events, API’s, even wire data! The result is beautifully indexed time-based series events, previously in disparate silos that can now be cross-correlated and made accessible to everyone your organization. Notice here that we are ingesting local files, data from syslogs, output from scripts and even wire data. Let’s see how the Splunk platform supports all this data collection.
- Three major tiers and components of Splunk Distribution Data Collection Layer -> This is where data is collected by or sent into Splunk. The star of the show here is Splunk’s Universal Forwarder which provides reliable, secure data collection from remote sources and forwards that data into Splunk Enterprise for indexing and consolidation. Data Indexing Layer -> The Data Collection Layer’s job is to collect and/or forward data to the Data Indexing Layer - Powered by Splunk Indexers. Indexers are just a collection of indexes which are logical containers for data to reside in. Data Presentation Layer -> Powered by Search Heads is responsible for distributing searches to the indexing layer, aggregate the final results, and present it to the end user. Viewing the data -> No special or custom client needed! Simply use your favorite browser and point to your Search Head. Now, in modestly small deployments the data indexing and searching will be done with the same Splunk Enterprise Instance.
- It only takes minutes to download and install Splunk on the platform of your choice, bringing you fast time to value. Once Splunk has been downloaded and installed the next step is to get data into a Splunk instance. The data then becomes searchable from a single place! Since Splunk stores only a copy of the raw data, searches won’t affect the end devices data comes from. Having a central place to search your data not only simplifies things, it also decreases risk since a user doesn’t have to log into the end devices. Splunk can be installed on a single small instance, such as a laptop, or installed on multiple servers to scale as needed. The ability to scale from a single desktop to an enterprise is another of our key differentiators. When installed on multiple servers the functions can be split up to meet any performance, security, or availability requirements.
- Lets say you are a Web Site Administrator. You recently received user complaints that that web pages are failing and not returning content when it should. Let’s use Splunk to search this data, to not only determine problems that happened but factors associated with or contributing to it.
- Start up a brand new Splunk Have a ready data set, typically use tutorial Literally drag and drop. Go back to components, what make them up Run two manual queries, paints picture of we can do. Patterns Create a data model (Use instant pivot) Create output Do something completely impressive. (create party on third party system, 3d graph, alert, something tangible outside of Splunk) Highlight best Splunk 6 features, add data, patterns, instant pivot,
- Data is growing and embodies new characteristics not found in traditional structured data: Volume, Velocity, Variety, Variability. "Big data" is a term applied to these expanding data sets whose size is beyond the ability of commonly used software tools to capture, manage, and process the data within a tolerable elapsed time. Machine data is one of the fastest, growing, most complex and most valuable segments of big data and embodies new characteristics not found in traditional structured data terms of Volume, Velocity, Variety, Variability. All the webservers, applications, network devices – all of the technology infrastructure running an enterprise or organization – generates massive streams of data, digital exhaust per say. It comes in an array of unpredictable formats that are difficult to process and analyze by traditional methods or in a timely manner. So why is this “machine data” valuable? Because it contains a trace - a categorical record - of user behavior, cyber-security risks, application behavior, service levels, fraudulent activity and customer experiences.