









Great Expectations Presentation
- 1. Confidential and Proprietary to Daugherty Business Solutions Perspective GREAT EXPECTATIONS
- 2. Confidential and Proprietary to Daugherty Business Solutions Great Expectations Great Expectations is a Python-based open- source library for validating, documenting, and profiling your data. It helps to maintain data quality and improve communication about data between teams.
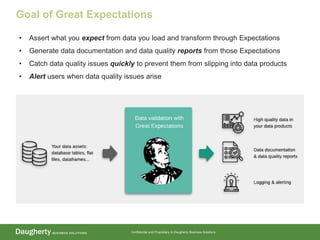
- 3. Confidential and Proprietary to Daugherty Business Solutions Goal of Great Expectations • Assert what you expect from data you load and transform through Expectations • Generate data documentation and data quality reports from those Expectations • Catch data quality issues quickly to prevent them from slipping into data products • Alert users when data quality issues arise
- 4. Confidential and Proprietary to Daugherty Business Solutions Key Features utilized by Data Engineers Expectations / Data Validation / Data Docs – Using assertions about what one expects of a dataset (Expectation), it is determined where issues exist (Data Validation) and generates a data quality report (Data Docs) example: expect_column_values_to_not_be_null would return a failure result for each row that reflects NULL in the defined column Automated Data Profiling – reviews datasets and generates a set of Expectations based on what is observed in the data example: Noting a column contains integers between 1 and 6, the profiler generates an Expectation - expect_column_values_to_b e_between Pre-defined and Custom Validations - Great Expectations provides dozens of validations for expected table shapes, missing values, unique values, data types, ranges, string matches, dates, aggregations, and more. They also provide documentation on creating custom expectations. Scalable - Great Expectations has been utilized at large data-heavy companies. In our particular use case with 600+ MB files, the expectation validation page was generated in a matter of seconds.
- 5. Confidential and Proprietary to Daugherty Business Solutions Customer Base Vimeo uses Great Expectations to monitor data pipelines that go into data warehouses Heineken’s Global Analytics team uses Great Expectations to standardize how validation is done across their data pipeline
- 6. Confidential and Proprietary to Daugherty Business Solutions Use Cases Built For NOT Built As Testing, validating, alerting, and ensuring data quality as part of a data pipeline A pipeline execution framework in and of itself Best setting up in Linux/iOS, or with a data pipeline already in place and great expectations as an addition A data versioning tool – does not store data itself Specific table-based tests such as value ranges, aggregations, and distribution checks A data cleaning tool, or one that will resolve failed Expectation tests (this must be solved separately)
- 7. Confidential and Proprietary to Daugherty Business Solutions Demo Let’s take a live look at how to start using Great Expectations!
- 8. Confidential and Proprietary to Daugherty Business Solutions Demo Using NYC Taxi Data 1. Introduce data and initialize a Data Context 2. Configure a Datasource to connect to data 3. Create Expectation Suite using the built-in automated profiler 4. Tour of Data Docs to view validation results 5. Use Expectation Suite to validate a new batch of data
- 9. Confidential and Proprietary to Daugherty Business Solutions NYC Taxi Data Background NYC Taxi Data is an open data set which is updated monthly. Each record corresponds to one taxi ride and contains information such as the pick-up and drop-off location, the payment amount, and the number of passengers, among others. In the demo, we will look at 10,000 row sample of Jan 2019 and Feb 2019 datasets
- 10. Confidential and Proprietary to Daugherty Business Solutions Ease of use, in conjunction with tutorial Python friendly Wide variety of database connections available Data docs make it easy to see if errors exist Ability to create checkpoints to validate new data Automated profiling expectations Doesn’t work well with all types of CLI commands (i.e. use pip instead of conda) Doesn’t support a work-flow for fixing bad data PROS CONS
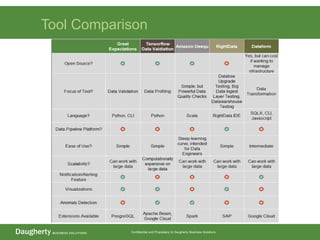
- 11. Confidential and Proprietary to Daugherty Business Solutions Tool Comparison
- 12. Confidential and Proprietary to Daugherty Business Solutions Considerations / Recommendations Helpful Links Airflow Code / Bitbucket Repo Getting Started with Great Expectations Connecting to Data Tutorials Custom Expectations Slack Channel Ease of Use Scalability Wide range of connectors Access to support and documentation THANK YOU RECOMMENDED When… Adding onto an existing data engineering pipeline Testing in sequence with other tasks Issue handling is not the expectation
Editor's Notes
- Expectations are basically unit tests for your data