HA/DR options with SQL Server in Azure and hybrid
•Download as PPTX, PDF•
7 likes•14,079 views

What are all the high availability (HA) and disaster recovery (DR) options for SQL Server in a Azure VM (IaaS)? Which of these options can be used in a hybrid combination (Azure VM and on-prem)? I will cover features such as AlwaysOn AG, Failover cluster, Azure SQL Data Sync, Log Shipping, SQL Server data files in Azure, Mirroring, Azure Site Recovery, and Azure Backup.


















HA/DR options with SQL Server in Azure and hybrid
- 1. James Serra Microsoft Data Platform Solution Architect HA/DR options with SQL Server in Azure and hybrid
- 2. About Me Microsoft, Big Data Evangelist In IT for 30 years, worked on many BI and DW projects Worked as desktop/web/database developer, DBA, BI and DW architect and developer, MDM architect, PDW/APS developer Been perm employee, contractor, consultant, business owner Presenter at PASS Business Analytics Conference, PASS Summit, Enterprise Data World conference Certifications: MCSE: Data Platform, Business Intelligence; MS: Architecting Microsoft Azure Solutions, Design and Implement Big Data Analytics Solutions, Design and Implement Cloud Data Platform Solutions Blog at JamesSerra.com Former SQL Server MVP Author of book “Reporting with Microsoft SQL Server 2012”
- 3. Agenda VM storage Always On AG Always On FCI Basic Availability Groups Database Mirroring Log Shipping Backup to Azure SQL Server data files in Azure Azure Site Recovery Azure VM Availability Set Azure SQL Data Sync
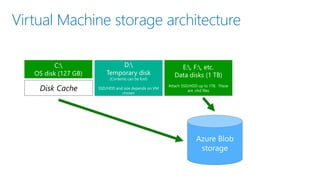
- 4. Virtual Machine storage architecture C: OS disk (127 GB) Usually 115 GB free E:, F:, etc. Data disks (1 TB) Attach SSD/HDD up to 1TB. These are .vhd files D: Temporary disk (Contents can be lost) SSD/HDD and size depends on VM chosenDisk Cache
- 5. Azure Default Blob Storage Azure Storage Page Blobs, 3 copies Storage high durability built-in (like have RAID) VHD disks, up to 1 TB per disk (64 TB total)
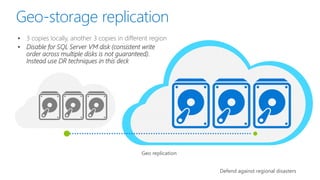
- 6. Geo-storage replication 3 copies locally, another 3 copies in different region Disable for SQL Server VM disk (consistent write order across multiple disks is not guaranteed). Instead use DR techniques in this deck Defend against regional disasters Geo replication
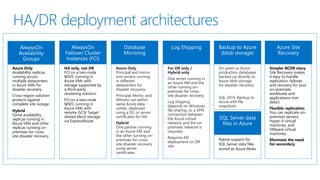
- 7. HA/DR deployment architectures Azure Only Availability replicas running across multiple Azure regions in Azure VMs for disaster recovery. Cross-region solution protects against complete site outage. Replicas running in same Azure Region for HA. Hybrid Some availability replicas running in Azure VMs and other replicas running on- premises for cross- site disaster recovery. HA only, not DR FCI on a two-node WSFC running in Azure VMs with storage supported by storage spaces direct. Azure Only Principal and mirror and servers running in different datacenters for disaster recovery. Principal, Mirror, and Witness run within same Azure data center, deployed using a DC or server certificates for HA. Hybrid One partner running in an Azure VM and the other running on- premises for cross- site disaster recovery using server certificates. For DR only / Hybrid only One server running in an Azure VM and the other running on- premises for cross- site disaster recovery. Log shipping depends on Windows file sharing, so a VPN connection between the Azure virtual network and the on- premises network is required. Requires AD deployment on DR site. On-prem or Azure production databases backed up directly to Azure blob storage for disaster recovery. SQL 2016: Backup to Azure with file snapshots Simpler BCDR story Site Recovery makes it easy to handle replication, failover and recovery for your on-premises workloads and applications (not data!). Flexible replication You can replicate on- premises servers, Hyper-V virtual machines, and VMware virtual machines. Eliminate the need for secondary Native support for SQL Server data files stored as Azure blobs
- 8. HA/DR Defined • High Availability (HA) – Keeping your database up 100% of the time with no data loss during common problems. Redundancy at system level, focus on failover, addresses single predictable failure, focus is on technology • Always On FCI • Always On AG (in same Azure region) • SQL Server data files in Azure • Disaster Recovery (DR) – Protection if major disaster or unusual failure wipes out your database. Use of alternate site, focus on re-establishing services, addresses multiple failures, includes people and processes to execute recovery. Usually includes HA also • Log Shipping • Database Mirroring • Always On AG (different Azure regions) • Backup to Azure
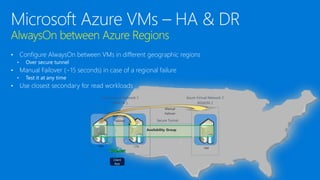
- 9. RPO/RTO RTO – Recover Time Objective. How much time after a failure until we have to be up and running again? RPO – Recover Point Objective. How much data can we lose? • HA – High Availability • RTO: seconds to minutes • RPO: Zero to seconds • Automatic failover • Well tested (maybe with each patch or release) • DR – Disaster Recovery • RTO: minutes to hours • RPO: seconds to minutes • Manual failover into prepared environment • Tested from time to time How long does it take to fail over: • Backup-Restore: Hours • Log Shipping: Minutes • Always On FCI: Seconds to minutes • Always On AG/Mirroring: Seconds
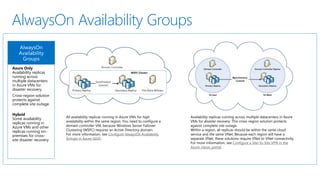
- 10. Always On Availability Groups Azure Only Availability replicas running across multiple Azure regions in Azure VMs for disaster recovery. Cross-region solution protects against complete site outage. Replicas running in same Azure Region for HA. Hybrid Some availability replicas running in Azure VMs and other replicas running on- premises for cross- site disaster recovery. Availability replicas running across multiple datacenters in Azure VMs for disaster recovery. This cross-region solution protects against complete site outage. Within a region, all replicas should be within the same cloud service and the same VNet. Because each region will have a separate VNet, these solutions require VNet to VNet connectivity. For more information, see Configure a Site-to-Site VPN in the Azure classic portal. NOTE: US East should show a FSW. All availability replicas running in Azure VMs for high availability within the same region. You need to configure a domain controller VM, because Windows Server Failover Clustering (WSFC) requires an Active Directory domain. For more information, see Configure Always On Availability Groups in Azure (GUI). With Windows Server 2016 replicas, you can use a Cloud Witness instead of a File Share Witness (FSW). A WSFC always requires a FSW to handle quorum (and Always On Availability Groups require WSFC).
- 11. Always On Availability Groups (Hybrid) Azure Only Availability replicas running across multiple Azure regions in Azure VMs for disaster recovery. Cross-region solution protects against complete site outage. Replicas running in same Azure Region for HA. Hybrid Some availability replicas running in Azure VMs and other replicas running on- premises for cross- site disaster recovery. Some availability replicas running in Azure VMs and other replicas running on-premises for cross-site disaster recovery. The production site can be either on-premises or in an Azure datacenter. Because all availability replicas must be in the same WSFC cluster, the WSFC cluster must span both networks (a multi- subnet WSFC cluster). This configuration requires a VPN connection between Azure and the on-premises network. For successful disaster recovery of your databases, you should also install a replica domain controller at the disaster recovery site. It is possible to use the Add Replica Wizard in SSMS to add an Azure replica to an existing Always On Availability Group. For more information, see Tutorial: Extend your Always On Availability Group to Azure.
- 12. Distributed Always On Availability Groups Azure Only Availability replicas running across multiple Azure regions in Azure VMs for disaster recovery. Cross-region solution protects against complete site outage. Replicas running in same Azure Region for HA. Hybrid Some availability replicas running in Azure VMs and other replicas running on- premises for cross- site disaster recovery. Distributed Availability Groups differ from an availability group on a single Windows Server Failover Cluster in the following ways: Pros • Each WSFC maintains its own quorum mode and node voting configuration. This means that the health of the secondary WSFC does not affect the primary WSFC • The data is sent one time over the network to the secondary WSFC and then replicated within that cluster. In a single WSFC, the data is sent individually to each replica. For a geographically dispersed secondary site, distributed availability groups are more efficient • The operating system version used on the primary and secondary clusters can differ. In a single WSFC, all servers must be on the same version of the OS. This has the potential to use Distributed Availability Groups with rolling updates/upgrades of the operating system Cons • The primary and secondary availability groups must have the same configuration of databases • Automatic failover to the secondary availability group is not supported • The secondary availability group is read-only
- 13. Always On Availability Groups failover modes • Primary role and secondary role of availability replicas are interchangeable • A secondary replica will be the failover target • Database level issues (i.e. database deletion, corrupted transaction log) do not cause an availability group to failover • During the failover, the failover target takes over the primary role, recovers its databases, and brings them online as the new primary databases. The former primary replica, when available, switches to the secondary role, and its databases become secondary databases. Three forms of failover: • Automatic failover: No data loss • Planned manual failover: No data loss • Forced manual failover: Also called forced failover. With possible data loss *If you issue a forced failover command on a synchronized secondary replica, the secondary replica behaves the same as for a manual failover
- 14. Always On Failover Cluster Instances (FCI) HA only, not DR FCI on a two-node WSFC running in Azure VMs with storage supported by storage spaces direct. You can use FCI to host an availability replica for an availability group Windows Server 2016 Storage Spaces Direct (S2D) provides virtual shared storage on top of the disks attached to the VMs hosting the FCI replicas by replicating the disk contents. We plan to support FCI natively on top of Premium Azure Files (physical SMB shared storage) this year.
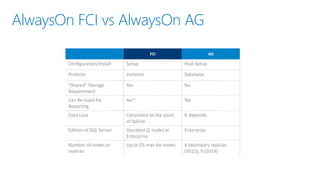
- 15. Always On FCI vs Always On AG
- 17. Basic Availability Groups Basic Availability Groups replaces the deprecated Database Mirroring feature, providing a similar level of features and is used for SQL Server 2016 Standard Edition (normal Availability Groups requires Enterprise Edition). Limitations: • Limit of two replicas (primary and secondary) • No read access on secondary replica • No backups on secondary replica • No support for replicas hosted on servers running a version of SQL Server prior to SQL Server 2016 Community Technology Preview 3 (CTP3) • No support for adding or removing a replica to an existing basic availability group • Support for one availability database • Basic availability groups cannot be upgraded to advanced availability groups. The group must be dropped and re-added to a group that contains servers running only SQL Server 2016 Enterprise Edition • Basic availability groups are only supported for Standard Edition servers
- 18. Database Mirroring Azure Only Principal and mirror and servers running in different datacenters for disaster recovery. Principal, Mirror, and Witness run within same Azure data center, deployed using a DC or server certificates for HA. Hybrid One partner running in an Azure VM and the other running on-premises for cross-site disaster recovery using server certificates. Principal and mirror and servers running in different datacenters for disaster recovery. You must deploy using server certificates because an Active Directory domain cannot span multiple datacenters. Principal, mirror, and witness servers all running in the same Azure datacenter for high availability. You can deploy using a domain controller. You can also deploy the same database mirroring configuration without a domain controller by using server certificates instead.
- 19. Database Mirroring vs Always On AG
- 20. Database Mirroring (Hybrid) Azure Only Principal and mirror and servers running in different datacenters for disaster recovery. Principal, Mirror, and Witness run within same Azure data center, deployed using a DC or server certificates for HA. Hybrid One partner running in an Azure VM and the other running on-premises for cross-site disaster recovery using server certificates. One partner running in an Azure VM and the other running on-premises for cross-site disaster recovery using server certificates. Partners do not need to be in the same Active Directory domain, and no VPN connection is required. Another database mirroring scenario involves one partner running in an Azure VM and the other running on-premises in the same Active Directory domain for cross-site disaster recovery. A VPN connection between the Azure virtual network and the on-premises network is required. For successful disaster recovery of your databases, you should also install a replica domain controller at the disaster recovery site.
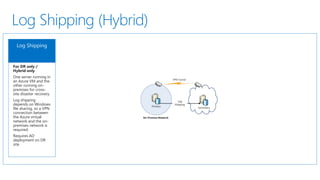
- 21. Log Shipping (Hybrid) For DR only / Hybrid only One server running in an Azure VM and the other running on- premises for cross- site disaster recovery. Log shipping depends on Windows file sharing, so a VPN connection between the Azure virtual network and the on- premises network is required. Requires AD deployment on DR site.
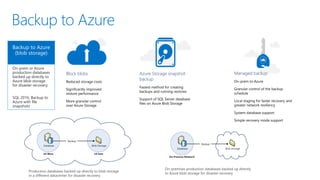
- 22. Block blobs Reduced storage costs Significantly improved restore performance More granular control over Azure Storage Azure Storage snapshot backup Fastest method for creating backups and running restores Support of SQL Server database files on Azure Blob Storage Backup to Azure Managed backup On-prem to Azure Granular control of the backup schedule Local staging for faster recovery and greater network resiliency System database support Simple recovery mode support On-prem or Azure production databases backed up directly to Azure blob storage for disaster recovery. SQL 2016: Backup to Azure with file snapshots Azure production databases backed up directly to Azure blob storage in a different datacenter for disaster recovery On-premises production databases backed up directly to Azure blob storage for disaster recovery.
- 23. Backup to Azure with file snapshots (SQL Server 2016) BACKUP DATABASE database TO URL = N'https://<account>.blob.core.windows.net/<container>/<backupfileblob1>‘ WITH FILE_SNAPSHOT Instance Azure Storage MDF Database MDF LDF LDF BAK Hybrid solutions
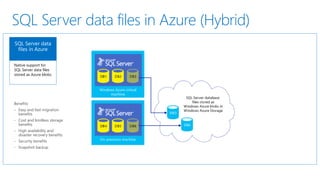
- 24. SQL Server data files in Azure (Hybrid) Native support for SQL Server data files stored as Azure blobs - Easy and fast migration benefits - Cost and limitless storage benefits - High availability and disaster recovery benefits - Security benefits - Snapshot backup
- 25. Azure Site Recovery (Hybrid) Simpler BCDR story Site Recovery makes it easy to handle replication, failover and recovery for your on-premises workloads and applications (not data!). Flexible replication You can replicate on- premises servers, Hyper-V virtual machines, and VMware virtual machines. Eliminate the need for secondary SQL Server on-prem DR example: Standalone SQL Server instance residing on-premises and replicating to an Azure Storage account by using Azure Site Recovery. The replication targets are page blobs containing the vhd files (C drive) of Azure IaaS virtual machines hosting SQL Server instances that are brought online during failover. SQL Server data files are not handled with ASR.
- 26. Azure VM Availability Set Create redundant VMs that are spread across multiple racks in the Windows Azure Data Centers. This means redundant power supply, switches and servers 99.95% SLA guaranteed (99.9% SLA for single instance) Each virtual machine in your Availability Set is assigned an Update Domain (UD) and a Fault Domain (FD) In ARM it is not yet possible to add an existing VM to an availability set. VMs in an Availability Set can be different sizes, but they need to be within a range of sizes supported by the hardware where the first VM lands. Generally we recommend to keep the VMs within the same family for a reliable deployment. This means only using VMs of the following sizes in the same set: A0 – A7 A8 – A11 D1 – D14 DS1 – DS14 D1v2 – D14v2 G1 – G5 GS1 – GS5
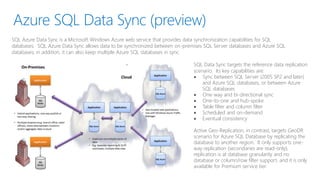
- 27. Azure SQL Data Sync (preview) SQL Azure Data Sync is a Microsoft Windows Azure web service that provides data synchronization capabilities for SQL databases. SQL Azure Data Sync allows data to be synchronized between on-premises SQL Server databases and Azure SQL databases; in addition, it can also keep multiple Azure SQL databases in sync. SQL Data Sync targets the reference data replication scenario. Its key capabilities are: Sync between SQL Server (2005 SP2 and later) and Azure SQL databases, or between Azure SQL databases One-way and bi-directional sync One-to-one and hub-spoke Table filter and column filter Scheduled and on-demand Eventual consistency Active Geo-Replication, in contrast, targets GeoDR scenario for Azure SQL Database by replicating the database to another region. It only supports one- way replication (secondaries are read-only), replication is at database granularity and no database or column/row filter support, and it is only available for Premium service tier.
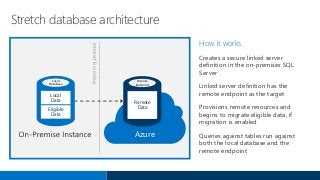
- 28. Stretch database architecture How it works Creates a secure linked server definition in the on-premises SQL Server Linked server definition has the remote endpoint as the target Provisions remote resources and begins to migrate eligible data, if migration is enabled Queries against tables run against both the local database and the remote endpoint Remote Endpoint Remote Data Azure InternetBoundary Local Database Local Data Eligible Data
- 29. Resources SQL Server in VM best practices: https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-sql- server-performance-best-practices/ https://azure.microsoft.com/en-us/documentation/articles/azure-subscription-service- limits/#virtual-machines-limits https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-size-specs/ https://azure.microsoft.com/en-us/pricing/details/virtual-machines/ Disaster Recovery and High Availability for Azure Applications: https://msdn.microsoft.com/en- us/library/azure/dn251004.aspx
- 30. Q & A ? James Serra, Big Data Evangelist Email me at: JamesSerra3@gmail.com Follow me at: @JamesSerra Link to me at: www.linkedin.com/in/JamesSerra Visit my blog at: JamesSerra.com (where this slide deck is posted via the “Presentations” link on the top menu)
Editor's Notes
- HA/DR options with SQL Server in Azure and hybrid What are all the high availability (HA) and disaster recovery (DR) options for SQL Server in a Azure VM (IaaS)? Which of these options can be used in a hybrid combination (Azure VM and on-prem)? I will cover features such as Always On AG, Failover cluster, Azure SQL Data Sync, Log Shipping, SQL Server data files in Azure, Mirroring, Azure Site Recovery, and Azure Backup.
- https://blogs.msdn.microsoft.com/mast/2013/12/06/understanding-the-temporary-drive-on-windows-azure-virtual-machines/ SSD/HDD storage included in A-series, D-series, and Dv2-series VMs is local temporary storage. DS-series, G-series, GS-series SSD's have less local temporary storage due to storage used for caching purposes to ensure predictable levels of performance associated with premium storage. DS-series and GS-series support premium storage disks, which means you can attach SSD's to the VM (the other series support only standard storage disks). The pricing and billing meters for the DS sizes are the same as D-series and the GS sizes are the same as G-series. When you create an Azure virtual machine, it has a disk for the operating system mapped to drive C (size is 127GB) that is on Blob storage and a local temporary disk mapped to drive D. You can choose standard disk type or premium (if DS-series or GS-series) for your local temporary disk - the size of which is based on the series you choose (i.e. A0 is 20GB). You can also attach new disks - specify standard or premium, for standard: specify size (1GB-1023GB), for premium: specify P10, P20, or P30. the disks are .vhd files that reside in an Azure storage account
- Because Azure stores three copies of your SQL databases in Azure Blob Storage, and Azure has redundant hardware (99.9% SLA for VMs), most companies don’t need to do anything more for HA (DR is a different story and Always On Availability Groups in different regions is one option for that). If the customer still feels like they need something more for HA, then Always On FCI or Always On Availability Groups in the same region would be the way to go. I lay out all the options in my deck at https://www.slideshare.net/jamserra/hadr-options-with-sql-server-in-azure-and-hybrid .
- http://www.jamesserra.com/archive/2015/11/redundancy-options-in-azure-blob-storage/ Geo-replication in Azure disks does not support the data file and log file of the same database to be stored on separate disks. GRS replicates changes on each disk independently and asynchronously. This mechanism guarantees the write order within a single disk on the geo-replicated copy, but not across geo-replicated copies of multiple disks. If you configure a database to store its data file and its log file on separate disks, the recovered disks after a disaster may contain a more up-to-date copy of the data file than the log file, which breaks the write-ahead log in SQL Server and the ACID properties of transactions. If you do not have the option to disable geo-replication on the storage account, you should keep all data and log files for a given database on the same disk. If you must use more than one disk due to the size of the database, you need to deploy one of the disaster recovery solutions listed above to ensure data redundancy. From https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-windows-sql-high-availability-dr/
- https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-windows-classic-sql-dr/ It is up to you to ensure that your database system possesses the HADR capabilities that the service-level agreement (SLA) requires. The fact that Azure provides high availability mechanisms, such as service healing for cloud services and failure recovery detection for the Virtual Machines (https://azure.microsoft.com/en-us/blog/service-healing-auto-recovery-of-virtual-machines), does not itself guarantee you can meet the desired SLA. These mechanisms protect the high availability of the VMs but not the high availability of SQL Server running inside the VMs. It is possible for the SQL Server instance to fail while the VM is online and healthy. Moreover, even the high availability mechanisms provided by Azure allow for downtime of the VMs due to events such as recovery from software or hardware failures and operating system upgrades. I do not consider transactional replication as a HA/DR solution. Yes, data modifications are being pushed to subscribers but we're talking at the publication/article level. This is going to be a subset of the data (could include all the data, but that won't be enforced. I.e. you create a new table in the publisher database, and that will not automatically be pushed to the subscribers). Plus, tables without a primary key cannot be replicated. Can do SQL Server on-prem replication to Azure SQL Database. The intent of replication was very different than HA/DR. "I want this table pushed to a data mart" or something like that. However, replication is the de facto solution for customers requiring subsets of data to be available.
- http://www.netmagicsolutions.com/blog/defining-high-availability-and-disaster-recovery https://docs.microsoft.com/en-us/azure/virtual-machines/windows/sql/virtual-machines-windows-sql-high-availability-dr
- https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-windows-sql-high-availability-dr/ https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-sql-server-alwayson-availability-groups-gui-arm/ https://blogs.msdn.microsoft.com/igorpag/2013/09/02/sql-server-2012-alwayson-availability-group-and-listener-in-azure-vms-notes-details-and-recommendations/ https://blogs.msdn.microsoft.com/igorpag/2014/07/03/deep-dive-sql-server-alwayson-availability-groups-and-cross-region-virtual-networks-in-azure/ https://blogs.technet.microsoft.com/dataplatforminsider/2014/06/19/sql-server-alwayson-availability-groups-supported-between-microsoft-azure-regions/ http://sqlha.com/2012/04/13/allans-alwayson-availability-groups-faq/ From Luis Carlos Vargas Herring: https://blogs.msdn.microsoft.com/clustering/2014/11/13/introducing-cloud-witness/ Both SQL FCI and AGs depend on Windows Cluster to handle quorum. Yes, in Windows Server 2016 they can leverage its Cloud Witness. This removes the need for a separate Azure VM to host the witness. We plan to enhance our AlwaysOn template to use this in H1CY17. File Share Witness: https://www.derekseaman.com/tag/file-share-witness, https://technet.microsoft.com/en-us/library/cc731739.aspx Availability Group listeners: https://msdn.microsoft.com/en-us/library/hh213417.aspx, https://docs.microsoft.com/en-us/azure/virtual-machines/windows/sql/virtual-machines-windows-portal-sql-alwayson-int-listener Does an always on availability group listener require an additional VM? No, the listener is merely a networking concept (a way for client connections to be routed to the primary replica). It needs an Azure Load Balancer (https://azure.microsoft.com/en-us/services/load-balancer/, https://docs.microsoft.com/en-us/azure/virtual-machines/windows/sql/virtual-machines-windows-portal-sql-ps-alwayson-int-listener)
- https://msdn.microsoft.com/en-us/library/ff877884.aspx https://msdn.microsoft.com/en-us/library/hh510230.aspx https://www.brentozar.com/sql/sql-server-alwayson-availability-groups/
- https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/distributed-availability-groups-always-on-availability-groups https://www.mssqltips.com/sqlservertip/5053/setup-and-implement-sql-server-2016-always-on-distributed-availability-groups/
- https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/failover-and-failover-modes-always-on-availability-groups
- An availability group has been configured with 2 replicas (primary P and secondary S1) for automatic failover and a Listener within the virtual network VNET1 in Region 1 (e.g. West US). This guarantees high availability of SQL Server in case of failures within the region. A secure tunnel has been configured between VNET1 and another virtual network VNET2 in Region 2 (e.g. Central US). The availability group has been expanded with a third replica (S2) configured for manual failover in this VNET to enable disaster recovery in case of failures impacting Region1. Finally, the Listener has been configured to route connections to the primary replica, irrespective of which region hosts it. This allows client applications connect to the primary replica, with the same connection string, after failing over between Azure regions. https://blogs.technet.microsoft.com/dataplatforminsider/2014/06/19/sql-server-alwayson-availability-groups-supported-between-microsoft-azure-regions/ https://blogs.msdn.microsoft.com/igorpag/2014/12/22/sql-server-2014-high-availability-and-multi-datacenter-disaster-recovery-with-multiple-azure-ilbs/
- https://azure.microsoft.com/en-us/blog/high-availability-for-a-file-share-using-wsfc-ilb-and-3rd-party-software-sios-datakeeper/ Replaces SQL Server failover cluster Requires shared storage
- https://docs.microsoft.com/en-us/azure/virtual-machines/windows/sql/virtual-machines-windows-portal-sql-create-failover-cluster
- The only cost advantage for FCI is if a customer must use SQL Standard and an older version of SQL Server. AGs were only supported on SQL Enterprise before SQL16. In SQL16 they’re supported also on Standard edition.
- https://msdn.microsoft.com/en-us/library/mt614935.aspx Basic availability groups use a subset of features compared to advanced availability groups on SQL Server 2016 Enterprise Edition. Basic availability groups include the following limitations: Limit of two replicas (primary and secondary). No read access on secondary replica. No backups on secondary replica. No support for replicas hosted on servers running a version of SQL Server prior to SQL Server 2016 Community Technology Preview 3 (CTP3). No support for adding or removing a replica to an existing basic availability group. Support for one availability database. Basic availability groups cannot be upgraded to advanced availability groups. The group must be dropped and re-added to a group that contains servers running only SQL Server 2016 Enterprise Edition. Basic availability groups are only supported for Standard Edition servers. https://www.concurrency.com/blog/july-2016/sql-server-2016-basic-availability-groups
- https://msdn.microsoft.com/en-us/library/mt614935.aspx
- What’s new in SQL Server 2016: http://searchsqlserver.techtarget.com/feature/Whats-new-in-2016s-SQL-Server-AlwaysOn-Availability-Groups
- https://msdn.microsoft.com/en-us/library/ms187103.aspx https://msdn.microsoft.com/en-us/library/ms151224.aspx http://www.sqlservercentral.com/articles/Replication/logshippingvsreplication/1399/ http://gokasdba.blogspot.com/2014/06/log-shipping-vs-mirroring-vs-replication.html http://dba.stackexchange.com/questions/53815/clustering-vs-transactional-replication-vs-availability-groups
- https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-sql-server-backup-and-restore/ https://blogs.technet.microsoft.com/dataplatforminsider/2016/04/19/sql-server-2016-cloud-backup-and-restore-enhancements/
- https://msdn.microsoft.com/en-us/library/dn385720.aspx https://msdn.microsoft.com/en-us/library/dn673536.aspx
- https://azure.microsoft.com/en-us/documentation/articles/site-recovery-overview/
- https://blogs.technet.microsoft.com/uspartner_ts2team/2016/11/22/azure-single-instance-virtual-machine-sla/ https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-windows-manage-availability/ https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-windows-classic-configure-availability/ In ARM: You can’t change the VM’s Availability Set once the VM is created You can’t add an Azure VM to an Availability Set once the VM is created You can’t remove a VM from an Availability Set Instead use Powershell: https://buildwindows.wordpress.com/2016/02/25/add-or-change-an-arm-virtual-machines-availability-set/ From Luis Carlos Vargas Herring: “Availability Set” is an Azure concept (not a SQL technology). The Availability Set merely tells Azure to host VMs in different failure domains (racks) and upgrade domains. This ensures that a failure/upgrade only brings down one VM at a time. This works well for stateless apps (like web servers), but it’s not enough for stateful apps that need replicas with an exact copy of the data (like SQL Server). SQL Availability Groups solve this by replicating data from a primary SQL instance to one or more secondary SQL instances and orchestrating a failover in case of a failure. An Azure Availability Set is a deployment constraint. It tells Azure to allocate those VMs inside of it into different fault and upgrade domains. This ensures that a rack failure or a Host maintenance operation doesn’t impact more than one VM at the same time. This is a core measure for replicated components (e.g. web servers or SQL Server replicas). To configure the SQL Server replicas, you need AlwaysOn Availability Groups.
- https://azure.microsoft.com/en-us/blog/azure-sql-data-sync-refresh/?v=17.23h https://azure.microsoft.com/en-us/documentation/articles/sql-database-get-started-sql-data-sync/ https://www.mssqltips.com/sqlservertip/3062/understanding-sql-data-sync-for-sql-server/ https://msdn.microsoft.com/en-us/library/hh868047.aspx Compare SQL Data Sync to Active Geo-Replication
- When it comes to hybrid solution we are introducing new industry first concepts of stretch tables into Azure for operational databases. So think about it We are making migrating SQL Server from on-prem to Azure VMs much easier. Currently when you move SQL Server we only migrated the schema and data. With SQL v-next you will able to migrate systems objects, SQL Settings so that migration is literally point and click type of migration. We will provide a wizard drive experience that will provide gallery image, vm size recommendations.
- Notes Now let’s talk about some of these innovative hybrid scenarios that can compliment your on-premises SQL Server investments. Stretch database, is one of these unique hybrid scenarios that only Microsoft provides and can be extremely valuable in your data strategy. We know your OLTP databases are growing rapidly and you need to think about how to cost effectively manage your data. More importantly, you need to think about what you’re doing with historical data and whether you want it to go offline onto tape. When it goes to tape, it’s not queryable anymore. What if you wanted the historical data at your fingertips but didn’t want to have it reside on premium storage with your hot data because it’s too costly. We can solve that problem with this stretch database hybrid scenario. Without modifying your app, you can stretch your database to Azure. You don’t even have to do any of the heavy lifting to make this work. You just have to set the policy you want to apply on the historical data and run the query as you normally would. SQL Server determines if the table has been stretched and retrieves the data from Azure. The other thing to note is that this technology does not impact the performance of writes on the same table being stretched as part of the engineering design point for this solution. A question you might ask is I am stretching historical customer data which has sensitive data, what about data security. The best part is that stretch database works with our new Always Encrypted technology that protects the columns you desire at rest and in motion, even in the memory buffer pool, so sensitive customer information is secure. Stretch database offers a great value prop in terms of saving you money and providing easy access to historical customer data so you can make improve customer experiences without requiring application modifications. This is just one example of how cloud-first innovation allows us to deliver new hybrid scenarios that our competitor simply can’t deliver or haven’t thought of.
- Source: https://msdn.microsoft.com/en-us/library/dn935011(v=sql.130).aspx Stretch Database lets you archive your historical data transparently and securely. In SQL Server 2016 Community Technology Preview 2 (CTP2), Stretch Database stores your historical data in the Microsoft Azure cloud. After you enable Stretch Database, it silently migrates your historical data to an Azure SQL Database. You don't have to change existing queries and client apps. You continue to have seamless access to both local and remote data. Your local queries and database operations against current data typically run faster. You typically enjoy reduced cost and complexity.
- Source: https://msdn.microsoft.com/en-us/library/mt169378(v=sql.130).aspx Concepts and architecture for Stretch Database Terms Local database. The on-premises SQL Server 2016 Community Technology Preview 2 (CTP2) database. Remote endpoint. The location in Microsoft Azure that contains the database’s remote data. In SQL Server 2016 Community Technology Preview 2 (CTP2), this is an Azure SQL Database server. This is subject to change in the future. Local data. Data in a database with Stretch Database enabled that will not be moved to Azure based on the Stretch Database configuration of the tables in the database. Eligible data. Data in a database with Stretch Database enabled that has not yet been moved, but will be moved to Azure based on the Stretch Database configuration of the tables in the database. Remote data. Data in a database with Stretch Database enabled that has already been moved to Azure. Architecture Stretch Database leverages the resources in Microsoft Azure to offload archival data storage and query processing. When you enable Stretch Database on a database, it creates a secure linked server definition in the on-premises SQL Server. This linked server definition has the remote endpoint as the target. When you enable Stretch Database on a table in the database, it provisions remote resources and begins to migrate eligible data, if migration is enabled. Queries against tables with Stretch Database enabled automatically run against both the local database and the remote endpoint. Stretch Database leverages processing power in Azure to run queries against remote data by rewriting the query. You can see this rewriting as a "remote query" operator in the new query plan.
- Source: https://msdn.microsoft.com/en-us/library/mt163698(v=sql.130).aspx