




































































































HBaseCon 2012 参加レポート
- 1. 2012月6月25日 Hadoopソースコードリーディング 第10回 資料 HBaseCon 2012 参加レポート 岩崎正剛/猿田浩輔 (株式会社NTTデータ) 本資料は 2012年5月にサンフランシスコで開催された Cloudera 社主催のイベント 『HBaseCon 2012』 の参加レポートです。各セッションの内容に基づき、作成したものです。 各セッションの概要および資料は http://www.hbasecon.com/agenda/ から確認できます。
- 2. お品書き イベントの様子 General Session Applications Operations Development Lightning Talk 2
- 3. イベントの様子 3
- 4. イベント概要 主催 Cloudera, Inc 開催日時 2012/05/22 開催場所 InterContinental San Francisco Hotel (カリフォルニア州サンフランシスコ) 概要 コミュニティの活性化などを目的とし、HBaseの利用事例紹介や運用ノウハウ/ 技術トピックなど、知見の発表/情報共有が行われるイベント 4
- 5. スポンサー 5
- 6. 会場の様子 当日の参加者およそ600人! 6
- 7. 会場の様子 Tシャツもらいました 7
- 8. イベントの構成 講演は4トラック構成 8
- 9. General Session 9
- 10. General Session(Stack & Mike) HBaseのコミッタでStumbleUponのStackとCloudera CEOのMike HBaseの開発に積極的に参加してほしいと要請 1
- 11. General Session(Stack & Mike) 特に貢献が求めらるもの レプリケーション セキュリティ セカンダリインデックス スナップショット バックアップ その他、分散システムの専門家の知見が必要な領域多数 1
- 12. General Session(Christophe & Charles) WibiData CEOのChristopheとCloudera VPのCharles Hadoopの典型的な利用領域と Hbaseでカバーできるようになる領域について言及 1
- 13. General Session(Christophe & Charles) Hadoopの典型的な利用領域 検索エンジン クリックストリーム処理 クラスタリング HBaseによりカバーできるようになるアプリケーション領 域 メッセージング 位置ベースアプリケーション リアルタイムレコメンデーション 広告最適化 1
- 14. General Session(Christophe & Charles) HBaseを用いたアプリケーションに共通するテーマについて言及 1
- 15. General Session(Christophe & Charles) HBaseを用いたアプリケーションの3つの共通テーマ 扱うデータがWeb Scale • RDBMSがカバーできない領域のスケール リアルタイム(ニアリアルタイム)が求められる Evolving • データソースとアプリケーションの要求が日々変わりうる 1
- 16. General Session(Christophe & Charles) これから重要となるHBaseの開発テーマ 1
- 17. General Session(Christophe & Charles) これから重要となるHBaseの開発テーマ スキーママネジメント/データモデリング 既存アプリケーションやシステムとの統合 各種言語サポート • REST, ORM, JDBC, Java, Python, Ruby, Scala, R • データサイエンティストがよく使うPythonやRubyのサポートを手厚くす る 1
- 18. Wishlist 1
- 19. Wishlist HBase開発者への要望 ユーザビリティとオペラビリティ • ワーニングメッセージやエラーメッセージの改善 • 解析用のメトリクス • 管理ツール M/Rジョブとの連携の改善 • バッチジョブ/GC/コンパクションの協調 自動チューニング • リージョンサイズ/フラッシュやコンパクションのストラテジ 1
- 23. Applications 2
- 24. GAP HBaseを用いてWeb上のカタログデータを統合 全てのブランド/マーケットを一元管理し、ブランドをまたがっ た分析などを可能にした 在庫管理のためデータストアをニアリアルタイムに更新 2
- 25. GAP 2
- 26. GAP 実現したいこと 業務用件 • 全てのブランド/マーケットを一元管理したい • ブランドをまたがった分析ができる システムの用件 • カタログのデータ量が増えても、スケール可能なアーキテクチャ • データストアに直接アクセスできる – ニアリアルタイムな在庫管理のため • キャッシュは最適化のためなどのためだけに最小限利用する – データの反映が遅延することを避ける • 高い可用性を持つ 2
- 27. GAP いくつかのソリューションを検討 シェアード型RDBMS、MemCachedなど • 目的を達成するためには多大な努力が必要(チューニングコストな どが大きい) • スケーラビリティの限界という課題が残る 非RDBの利用 結果的にHBaseを導入 一貫性を重視した設計である サーバサイドでフィルタ処理が実装可能である 自動でシャーディング/データの分散配置/フェイルオー バーを行う Hadoopとの親和性が高い 2
- 28. GAP 2
- 29. GAP クラスタのトラフィックパターン ほとんどが読み込みリクエスト 書き込みや削除は突発的に起こる • カタログの掲載 • M/Rジョブの出力 書き込みは継続的に実行される • 在庫のアップデート 2
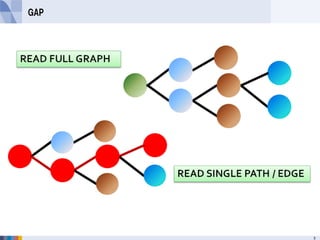
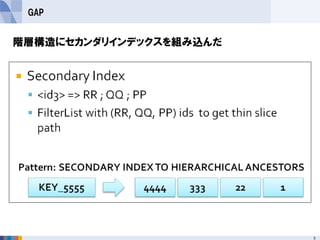
- 30. GAP 扱うデータモデル カタログデータをグラフ構造で保持 • SKU -> スタイルなど階層構造でデータを表現 • クロスブランド販売を可能にする(ブランド間を関係づける) アクセスパターン いちどにすべての商品のグラフ構造を読み込む(全商品の 検索) 商品グラフの中の特定のノードへのシングルパスをたどる (特定商品検索) セカンダリインデックスを用いた商品の検索 etc 3
- 31. GAP 3
- 32. GAP 3
- 34. GAP クラスタ構成 16 Slave (RS + TT + DN) Nodes • 8 & 16 GB RAM 3 Master (HM,ZK,JT, NN) Nodes • 8 GB RAM NN Failover via NFS 3
- 35. GAP チューニング関連ノウハウ Block Cache • Maximize Block Cache • hfile.block.cache.size: 0.6 Garbage Collection • MSLAB enabled • CMSInitiatingOccupancyFactor Quick Recovery on node failure • Default timeouts too large • zookeeper.session.timeout Region Server • hbase.rpc.timeout Data Node • dfs.heartbeat.recheck.interval • heartbeat.recheck.interval 3
- 37. Tumblr 3
- 38. Tumblr 3
- 39. Tumblr 3
- 40. Tumblr 4
- 41. Tumblr 4
- 42. Tumblr 4
- 43. Tumblr 4
- 44. Tumblr 4
- 45. Tumblr 4
- 46. Tumblr 4
- 47. Facebook 4
- 48. Facebook 4
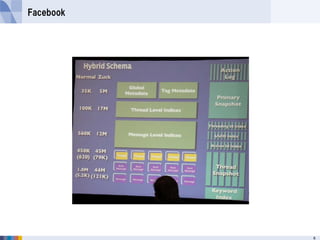
- 49. Facebook HBase最大のアプリケーションとして有名なメッセージング基盤 書き込みサイズの縮小、ホットスポットの排除が最重要 2PBのオンラインデータ ひと月あたり250TBのペースで増加 150億メッセージ x 1024 bytes = 14TB 1200億のチャットデータ x 100 bytes = 11TB 750億ops/day ピーク時の負荷は150万ops/s readが55%、writesが45% 1行の書き込みが平均16KeyValueで複数のCFにまたがる 1クラスタ25~200ノードからなる 48GBのメモリ 12~36TBのSATAディスク RegionServerはDataNodeと同一ノード上に同居 4
- 50. Facebook 5
- 51. Facebook 5
- 52. Facebook なぜHBaseか? 低レイテンシ 水平方向にスケールする 自動的にフェイルオーバーする 自動シャーディング 強い一貫性 圧縮して格納 Read - Modify - Writeをサポートしている(例えばカウン タ) MapReduceとの統合 5
- 53. Facebook 5
- 54. Facebook Appserverのドメインモデル 非正規化されたスキーマ エンティティ • メッセージ • スレッド • etc エンティティ間のリレーションシップ • スレッドとメッセージ • メッセージIDとスレッドID • etc 5
- 55. Facebook 5
- 56. Facebook 5
- 57. Facebook 5
- 58. Facebook 5
- 59. Facebook 5
- 60. Facebook 6
- 61. Facebook 6
- 62. Facebook 6
- 63. Facebook 6
- 64. Facebook 6
- 65. Operations 6
- 66. Case Study of HBase Operations at Facebook 6
- 67. Case Study of HBase Operations at Facebook - HBaseの運用苦労話。 HBaseがいかにCoolかという話は別セッションでやるのでここではCoolでない話を。 - 障害パターンごとに対応や「こうなっているべき」を紹介。 - NameNode障害 - ラックスイッチ/クラスタスイッチ障害 - メンテナンス - テーブル分割と負荷の偏り - コンパクション - バグによるサーバ停止 - プロセスが停止しないプロセス障害 - 原因別の停止時間比較。 定期/不定期メンテナンスが最も多い。スイッチの故障が続く。 NameNode障害は相対的に少ない。 - リージョンの移動が、データのローカリティが低下として、NW転送量にあらわれる。 帯域に余裕がほしい。 - 「落ちるときは落ちる」。 それを前提としてアプリや運用を作れ。しぶといシステムを組め。というまとめ。 6
- 68. Case Study of HBase Operations at Facebook 発表者: Ryan Thiessen, Technical Lead, Facebook 6
- 69. Case Study of HBase Operations at Facebook 6
- 70. Case Study of HBase Operations at Facebook 7
- 71. Case Study of HBase Operations at Facebook 7
- 72. Case Study of HBase Operations at Facebook 7
- 73. Case Study of HBase Operations at Facebook 7
- 74. HBase Backup 7
- 75. HBase Backup - 現状利用できるバックアップ手段の比較 - DistCP - exportツール - copytableツール - レプリケーション - アプリケーションから複数クラスタへの書き込み - Facebookにおけるユースケース - MapReduceによるバックアップジョブ - バックアップレベル - 所要時間 - Hbaseコミュニティでのバックアップ向け機能の開発状況 7
- 76. HBase Backup 発表者: Sunil Sitaula, Solutions Architect, Cloudera Inc. Madhuwanti Vaidya, Software Engineer, Facebook Inc. 7
- 77. HBase Backup -現状のバックアップ選択肢 DistCP - /hbaseディレクトリ下をまるまるコピー。 - 速くて簡単だが一貫性は保証されない。Memstoreのデータも考慮されない。 exportツール - データをExportするMRジョブ起動。 - テーブル名、バージョン数、TimeRange指定でexport対象を指定可能。 - 1度に1つのテーブルしか処理できない。 copytableツール - exportツールとは違い、データを別クラスタに保存。 - 長所短所はexportツールと同様。 レプリケーション - Regionサーバ間のWALEditsの転送によるレプリケーション。 - 一時的にスレーブ側クラスタをオフラインにすることもできる。 - バグやオペミスによるデータ消去はレプリカ側にも波及する。 アプリケーションから複数クラスタへの書き込み。 - DRに対応できるが、整合性や原子性をAPが配慮しなければならない。 7
- 78. HBase Backup - Facebookでのユースケース - HBASE-5509を利用したMRジョブによるバックアップ。 - 1マッパーが1リージョンを担当。 - regionをflushしてからHFileをコピー。 - データのローカリティが高いようにmapperを配置する。 - Trashを見に行く必要があるので、保持期間に注意。 - リストアは、ファイルを配置して、.META.に情報追加。 - バックアップには3つのレベルがある。 1. 同一クラスタ内。(1回/1日) 2. 同一DC内。(1回/10日) 3. DC間。(1回/10日) - 各データブロックを各ノードローカルにコピーする「高速コピー」機能を実装。 - 40TBのテーブルを49mapperでバックアップする際の所要時間。 - 通常: 15時間 - 高速コピー: 1.5時間 - 将来的な課題として、HLogのバックアップとPIRT。 - HDFSのハードリンク(HDFS-3370)が前提。 7
- 79. HBase Backup - 絶賛開発中の機能 - HBASE-6055: スナップショット - HBASE-4618: HFileとHLogにもとづくバックアップ 7
- 80. HBase Backup - 高速コピー 8
- 81. ランチボックス 8
- 82. Development 8
- 83. HBase Schema Design 8
- 84. HBase Schema Design HBaseのスキーマ設計設計はRDBMSの場合の非正規化に相当する。 「入れ子になったエンティティ」というRDBMSにはない概念がキーポイント。 - HBaseのデータ構造の復習 - HBaseには外部キー、ジョイン、テーブルをまたがるトランザクションは無い。 テーブル間の関係をどう表現するかについて、 自力でジョインを実装するか非正規化するかの2択だが、非正規化がおすすめ。 - 入れ子になったエンティティ - 固定幅での表現、区切り文字、シリアライズによるバイト列の結合 - 行キーの一部、列名、タイムスタンプを属性の格納に利用。 - 「HBaseスキーマのデザインパターン」紹介。 データへのアクセスパスを考慮して設計すること。 RDBはアクセスパターンをユーザから隠ぺいするが、 HBaseはユーザに考えさせる。 8
- 85. HBase Schema Design 発表者: Ian Varley, Principal Member of Technical Staff, Salesforce.com 8
- 86. HBase Performance Tuning and Optimizations 8
- 87. HBase Performance Tuning and Optimizations 8
- 88. HBase Performance Tuning and Optimizations 8
- 89. HBase Schema Design - デザインパターン 0. 行キーの設計がすべて。 (行キーというかKeyValueのKey全体を含むニュアンス) 1. Design for the questions, not the answers. 2. データサイズは2種類しかない。大きすぎるか、そうでないか。 3. コンパクトに詰め込め。 (OpenTSBDのタイムスタンプを差分で保存する例から。) 4. 行単位の原子性を活用する。 5. 属性は行キー内に移動することができる。 (Lars Georgeがfoldingと呼んでいる手法。) 6. エンティティをネストさせると、データを事前に集計できる。 (DWHのpre-aggregation。) 8
- 90. HBase Performance Tuning and Optimizations - Facebookでの性能チューニングベストプラクティス - 行キー設計と事前スプリット - ブロックサイズ - コンパクション設定 - HBase自体の性能改良について紹介 - HFile v2 - データブロックエンコーディング(HBASE-4218) - スキャナ改善 9
- 91. HBase Performance Tuning and Optimizations 発表者: Mikhail Bautin, Software Engineer, Facebook 9
- 92. HBase Performance Tuning and Optimizations Facebookでの性能チューニングベストプラクティス - テーブルの事前スプリット。 - 行キーの先頭にハッシュキーをつけて書き込みを散らす。 - 1ブロック内のKVの数が多くなりすぎないようにブロックサイズを調節。 Facebookdでは64KBまたは128KBを利用。 - オフピーク時間を設定する。 - hbase.offpeak.{start,end}.hour - hbase.hstore.compaction.ratio.offpeak - コンパクション設定 - hbase.hstore.compactionThreshold = 3 - hbase.hstore.compaction.max = 12 (OOMを防ぐために上限を設定。) - hbase.hstore.compaction.min.size = 4194304 (4MB以下は常に対象。) - hbase.store.compaction.ratioを上げ、積極的にコンパクションする。 9
- 93. HBase Performance Tuning and Optimizations 9
- 94. HBase Performance Tuning and Optimizations 9
- 95. HBase Performance Tuning and Optimizations スキャナ改善 - HBASE-4433: next呼び出し時の不要なブロック読み込みの防止。 - HBASE-4434: next呼び出しでのプリフェッチをやめる - HBASE-2794: 同一CF内の複数列のGetでBloomフィルタを利用可能にする - HBASE-4465: StoreFileのスキャン効率改善 - HBASE-4469: Bloomフィルタ利用時の行シークの効率改善。 - HBASE-4532: 専用Bloomフィルタを利用した行シークの効率改善。 - HBASE-4585: 複数列読み込み時のnextでの不要な読み込みの防止。 9
- 96. HBase Performance Tuning and Optimizations 9
- 97. Ligntning Talk 9
- 100. Yahoo! トランザクション機能を拡張 1
- 102. NextBio 患者データの相関を格納 1
- 103. AOL メールデータのプロファイリング結果を格納 1
- 104. OCLC 図書館所蔵の書籍データを格納するシステム 1
- 105. Sushi 1
- 106. Chocolate(Any Question?) 1