

























High-Performance Networking Using eBPF, XDP, and io_uring
- 1. Brought to you by Bryan McCoid Sr. Software Engineer at High Performance Networking Using eBPF, XDP, and io_uring
- 2. Bryan McCoid Sr. Software Engineer ■ I work on the clustering/control plane component at Couchbase ■ Into all things Linux, eBPF, and networking ■ I live in Santa Cruz, CA -- so I literally enjoy long walks on the beach ■ Talk not based on Couchbase product(s) or technology ● Based on personal interest and open source work About me..
- 3. So who cares about networking anyways?! Why is it that we even care about this? It all sounds very boring and I just want to write my application logic.. The answer I’ve found most compelling is.. ■ Most (interesting) high performance applications are I/O bound ■ Backend servers and databases all tend to be bound by either networking or disk performance. ■ … so that’s why I’m gonna focus on networking
- 5. So what are our options? Most people deal with networking in linux at the socket level ■ Normal, blocking sockets ● 1 thread blocking on every I/O syscall ■ Async sockets (epoll + nonblocking sockets, io_uring) ● Epoll: register sockets and get notified when they are ready ● Io_uring: new hotness ■ Low Level: AF_PACKET ■ Kernel Bypass: ● DPDK - Data Plane Development Kit (Intel) - Link ● Netmap - "the fast packet I/O framework" - Link
- 6. Enter eBPF... “eBPF is a revolutionary technology with origins in the Linux kernel that can run sandboxed programs in an operating system kernel. It is used to safely and efficiently extend the capabilities of the kernel without requiring to change kernel source code or load kernel modules.” -- https://ebpf.io/
- 7. XDP/AF_XDP - Linux’s answer to kernel bypass
- 8. AF_PACKET V4 -> AF_XDP ■ A new version of AF_PACKET was being developed around the same time eBPF came into existence. ■ Instead of releasing it, they transformed it into what we now know as XDP by using ebpf as the glue. ■ A specific socket type was created that used eBPF to route packets to userspace. ■ And that’s how we got AF_XDP. (and this is where the talk really begins ;-)
- 9. XDP XDP comes in two variants to the user, but these interfaces are intertwined ■ XDP programs can be standalone, written in C, compiled to ebpf bytecode, and ran on raw packet data without ever having anything to do with userspace. ■ XDP can be used to route packets to ringbuffers that allow rapid transfer to userspace buffers. This is referred to as AF_XDP.
- 10. The linux kernel networking is great, but... ■ For many use-cases it’s not ideal ■ It’s relatively scalable but.. ● At some point you are just at the mercy of the kernel ■ Copies.. Copies, copies.. ● Multiple copies often need to take place, even in the best optimized methods ■ Much better latency, or at least more consistent latency
- 11. My use for XDP And how to use AF_XDP in general
- 12. How to use it? + Designing a runtime in Rust ■ Built for existing Rust asynchronous I/O library named Glommio ● Designed as a TPC async I/O library that uses io_uring ■ Currently just in a forked version ■ Still being worked on.. (check back someday) ■ Would love contributions! So how would we design it and how does AF_XDP work?
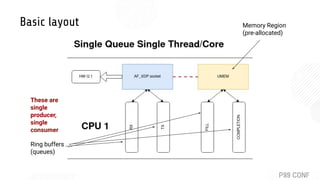
- 13. Basic layout
- 16. Memory Region (pre-allocated) Ring buffers (queues) These are single producer, single consumer Basic layout
- 17. Basic layout (including another cpu for driver / IRQ handling)
- 18. “Default” eBPF code for AF_XDP socket #include <bpf/bpf_helpers.h> Struct bpf_map_def SEC(“maps”) xsks_map = { .type = BPF_MAP_TYPE_XSKMAP, .key_size = sizeof(int), .value_size = sizeof(int), .max_entries = 64, };
- 19. “Default” eBPF code for AF_XDP socket SEC(“xdp_sock”) int xdp_sock_prog(struct xdp_md *ctx) { int index = ctx->rx_queue_index; if (bpf_map_lookup_elem(&xsks_map, &index)) { return bpf_redirect_map(&xsks_map, index, 0); } return XDP_PASS; }
- 20. How about other designs?
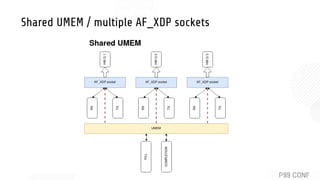
- 21. Shared UMEM / multiple AF_XDP sockets
- 22. Many sockets, many UMEMs, 1 per core
- 23. Interfacing with kernel is easy let count = _xsk_ring_cons__peek( self.rx_queue.as_mut(), filled_frames.len().unwrap_or(0), &mut idx, ); … snip … for idx in 0..count { let rx_descriptor = _xsk_ring_cons__rx_desc(rx_queue.as_ref(), idx); // put ^^ this descriptor somewhere } … snip … _xsk_ring_cons__release(rx_queue.as_mut(), count);
- 24. How this fits into the larger framework The framework I’m integrating to focuses on IO_URING so integrating can happen a few different ways.. 1. When you need to poll/drive I/O (needs_wakeup mode) you can submit to io_uring a. When packets arrive, this will wake up the consumer (from io_uring) to poll the rings again. 2. For busy-polling mode you just make the calls in the runtime loop and you can’t easily go to sleep/block. So you either spin, or fallback to the other mode. a. It makes it harder to use the existing capabilities of io_uring, but pretty much forces you into spinning constantly, calling synchronous kernel API’s, whether there’s packets or not.
- 25. Other considerations ■ Is relying on the io_uring for needs_wakeup notifications of readiness too slow? ● Does it add too much latency? ■ Is it possible to use multi-shot poll and never have to re-arm the ring? ■ The runtime is cooperatively scheduled, so how do you guard against tight loops on recieve or similar? ● Most of the calls to kernel/libbpf are actually synchronous, is that a problem?
- 26. This is all a work in-progress... Thanks for listening and we’d love for people to get interested and contribute! Main repo: https://github.com/DataDog/glommio Parting words: When in doubt: just try using io_uring alone, it’s really great and is the future of most async I/O on linux.
- 27. Brought to you by Bryan McCoid bryan.mccoid@couchbase.com @bryanmccoid
- 28. (BONUS) Popular projects ■ (DPDK) Seastar *cough* *cough* - asynchronous fast I/O framework ■ (DPDK) mTCP - TCP stack ■ (XDP) Katran - XDP load balancer ■ (XDP/eBpf) Cillium - Kubernetes networking stack built into linux kernel using ebpf. ■ (XDP) Mizar - high performance cloud network for virtual machines.