IlOUG Tech Days 2016 - Unlock the Value in your Data Reservoir using Oracle Big Data Discovery
•
0 likes•1,722 views

Mark Rittman from Rittman Mead presented on Oracle Big Data Discovery. He discussed how many organizations are running big data initiatives involving loading large amounts of raw data into data lakes for analysis. Oracle Big Data Discovery provides a visual interface for exploring, analyzing, and transforming this raw data. It allows users to understand relationships in the data, perform enrichments, and prepare the data for use in tools like Oracle Business Intelligence.










































IlOUG Tech Days 2016 - Unlock the Value in your Data Reservoir using Oracle Big Data Discovery
- 1. info@rittmanmead.com www.rittmanmead.com @rittmanmead Unlock the Value in your Big Data Reservoir using Oracle Big Data Discover Mark Rittman, CTO, Rittman Mead IlOUG Tech Days 3, Tel Aviv, May 2016
- 2. info@rittmanmead.com www.rittmanmead.com @rittmanmead 2 •Mark Rittman, Co-Founder of Rittman Mead ‣Oracle ACE Director, specialising in Oracle BI&DW ‣14 Years Experience with Oracle Technology ‣Regular columnist for Oracle Magazine •Author of two Oracle Press Oracle BI books ‣Oracle Business Intelligence Developers Guide ‣Oracle Exalytics Revealed ‣Writer for Rittman Mead Blog : http://www.rittmanmead.com/blog •Email : mark.rittman@rittmanmead.com •Twitter : @markrittman About the Speaker
- 3. info@rittmanmead.com www.rittmanmead.com @rittmanmead 3 •Many customers and organisations are now running initiatives around “big data” •Some are IT-led and are looking for cost-savings around data warehouse storage + ETL •Others are “skunkworks” projects in the marketing department that are now scaling-up •Projects now emerging from pilot exercises •And design patterns starting to emerge Many Organisations are Running Big Data Initiatives
- 4. info@rittmanmead.com www.rittmanmead.com @rittmanmead 4 •Typical implementation of Hadoop and big data in an analytic context is the “data lake” •Additional data storage platform with cheap storage, flexible schema support + compute •Data lands in the data lake or reservoir in raw form, then minimally processed •Data then accessed directly by “data scientists”, or processed further into DW Common Big Data Design Pattern : “Data Reservoir”
- 5. info@rittmanmead.com www.rittmanmead.com @rittmanmead Common Project Environment : The “Data Lab”
- 6. info@rittmanmead.com www.rittmanmead.com @rittmanmead 6 •Data loaded into the reservoir needs preparation and curation before presenting to users •Specialist skills typically needed to ingest and understand data - and those staff are scarce •How do we staff and scale projects as our use of big data matures? But … Working with Unstructured Textual Data Is Hard
- 7. Hold on …
- 8. Haven't we heard this story before?
- 10. info@rittmanmead.com www.rittmanmead.com @rittmanmead 10 •Part of the acquisition of Endeca back in 2012 by Oracle Corporation •Based on search technology and concept of “faceted search” •Data stored in flexible NoSQL-style in-memory database called “Endeca Server” •Added aggregation, text analytics and text enrichment features for “data discovery” ‣Explore data in raw form, loose connections, navigate via search rather than hierarchies ‣Useful to find out what is relevant and valuable in a dataset before formal modeling What Was Oracle Endeca Information Discovery?
- 11. the years pass…
- 12. 2013
- 13. … to 2015
- 14. and even more importantly…
- 16. info@rittmanmead.com www.rittmanmead.com @rittmanmead 16 •A visual front-end to the Hadoop data reservoir, providing end-user access to datasets •Catalog, profile, analyse and combine schema-on-read datasets across the Hadoop cluster •Visualize and search datasets to gain insights, potentially load in summary form into DW Oracle Big Data Discovery
- 17. info@rittmanmead.com www.rittmanmead.com @rittmanmead 17 What Does Big Data Discovery Do? •Provide a visual catalog and search function across data in the data reservoir •Profile and understand data, relationships, data quality issues •Apply simple changes, enrichment to incoming data •Visualize datasets including combinations (joins)
- 18. info@rittmanmead.com www.rittmanmead.com @rittmanmead 18 •A catalog and view onto data sitting in Hadoop •Data wrangling, enrichment and combining •Visualization and Exploration of that data Main Big Data Discovery Use-Cases
- 19. info@rittmanmead.com www.rittmanmead.com @rittmanmead •Visual Analyzer, DVCS, DVD are also free- form data visualisation tools ‣Single-pane-of-glass view onto data ‣Drill, export and visualise your data •Crucially though these tools work on data that’s already structured and “known” ‣Data sources are either the OBIEE RPD, or files extracted from other structured systems •Oracle BDD is for stage before this, when data is in a “raw” state and landed in Hadoop ‣See the shape, value and integration points ‣Structure, enrich and transform Oracle Big Data Discovery vs. Oracle Data Visualisation
- 20. info@rittmanmead.com www.rittmanmead.com @rittmanmead 20 •Rittman Mead want to understand drivers and audience for their website ‣What is our most popular content? Who are the most in-demand blog authors? ‣Who are the influencers? What do they read? •Three data sources in scope: Example Scenario : Social Media Analysis RM Website Logs Twitter Stream Website Posts, Comments etc
- 21. info@rittmanmead.com www.rittmanmead.com @rittmanmead 21 •Datasets in Hive have to be ingested into DGraph engine before analysis, transformation •Can either define an automatic Hive table detector process, or manually upload •Typically ingests 1m row random sample ‣1m row sample provides > 99% confidence that answer is within 2% of value shown no matter how big the full dataset (1m, 1b, 1q+) ‣Makes interactivity cheap - representative dataset Ingesting & Sampling Datasets for the DGraph Engine
- 22. info@rittmanmead.com www.rittmanmead.com @rittmanmead 22 •Ingestion process has automatically geo-coded host IP addresses •Other automatic enrichments run after initial discovery step, based on datatypes, content Automatic Enrichment of Ingested Datasets
- 23. info@rittmanmead.com www.rittmanmead.com @rittmanmead 23 •Data ingest process automatically applies some enrichments - geocoding etc •Can apply others from Transformation page - simple transformations & Groovy expressions Data Transformation & Enrichment
- 24. info@rittmanmead.com www.rittmanmead.com @rittmanmead 24 •Users can upload their own datasets into BDD, from MS Excel or CSV file •Uploaded data is first loaded into Hive table, then sampled/ingested as normal Upload Additional Datasets 1 2 3
- 25. info@rittmanmead.com www.rittmanmead.com @rittmanmead 25 •Used to create a dataset based on the intersection (typically) of two datasets •Not required to just view two or more datasets together - think of this as a JOIN and SELECT Join Datasets On Common Attributes
- 26. info@rittmanmead.com www.rittmanmead.com @rittmanmead 26 Visualize and Interact With Hadoop Datasets
- 27. info@rittmanmead.com www.rittmanmead.com @rittmanmead 27 •BDD Studio dashboards support faceted search across all attributes, refinements •Auto-filter dashboard contents on selected attribute values - for data discovery •Fast analysis and summarisation through Endeca Server technology Faceted Search Across Entire Data Reservoir Further refinement on “OBIEE” in post keywords 3 Results now filtered on two refinements 4
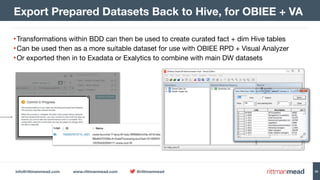
- 28. info@rittmanmead.com www.rittmanmead.com @rittmanmead 28 •Transformations within BDD can then be used to create curated fact + dim Hive tables •Can be used then as a more suitable dataset for use with OBIEE RPD + Visual Analyzer •Or exported then in to Exadata or Exalytics to combine with main DW datasets Export Prepared Datasets Back to Hive, for OBIEE + VA
- 29. info@rittmanmead.com www.rittmanmead.com @rittmanmead 29 •Users in Visual Analyzer then have a more structured dataset to use •Data organised into dimensions, facts, hierarchies and attributes •Can still access Hadoop directly through Impala or Big Data SQL •Big Data Discovery though was key to initial understanding of data Further Analyse in Visual Analyzer for Managed Dataset
- 30. hang on a moment…
- 31. … what about her?
- 33. How do I turn Christian Berg…
- 34. Into Christian Berg-Tierney? I’m too sexy…
- 35. info@rittmanmead.com www.rittmanmead.com @rittmanmead BDD 1.2.0 Release Theme : “Developer Productivity” 35
- 36. info@rittmanmead.com www.rittmanmead.com @rittmanmead 36 •Useful to create weekly stats out of daily ones, for example for logistic regression analysis •Roll up low-level data to higher grains •Logs -> sessions -> customers •Intuitive UI helps analysts find the right grains •Execute at full scale using Spark •Results can be sampled or indexed in full New Features to Aggregate and Join Datasets
- 37. info@rittmanmead.com www.rittmanmead.com @rittmanmead •Blend huge datasets right in BDD, UI to support experimentation, preview •Execute at scale with Spark, results can be sampled or indexed in full •Useful for joining-back to same dataset to calculate change since last month/week Join Datasets in BDD (incl. Joinback)
- 38. info@rittmanmead.com www.rittmanmead.com @rittmanmead •Access Python & Spark packages, run against BDD datasets •Pandas, Numpy, SparkML, Spark SQL •Suddenly Big Data Discovery gets useful •Use BDD’s cataloging and enrichment •Blend and join datasets •Use them as datasources into Python and Spark data science algorithms •The best of both worlds Most Significant for Data Scientists : pySpark Shell
- 39. info@rittmanmead.com www.rittmanmead.com @rittmanmead •Use .toSpark and .toDF Spark transformations to turn BDD datasets into Spark RDDs and Dataframes •Then access Spark SQL set-based queries and JDBC query federation to further manipulate + join data •Use Spark MLlib to access machine-learning features •Classification •Clustering •Collaborative Learning Access to Spark SQL and Spark MLlib
- 40. info@rittmanmead.com www.rittmanmead.com @rittmanmead •Using BDD + wearable + home IoT datasets to create a quantified-self project •Use machine learning (via BDD shell) to optimise my life for health and mood Watch This Space … at KScope’16
- 42. info@rittmanmead.com www.rittmanmead.com @rittmanmead 42 •Articles on the Rittman Mead Blog ‣http://www.rittmanmead.com/category/oracle-big-data-appliance/ ‣http://www.rittmanmead.com/category/big-data/ ‣http://www.rittmanmead.com/category/oracle-big-data-discovery/ •Rittman Mead offer consulting, training and managed services for Oracle Big Data ‣Oracle & Cloudera partners ‣http://www.rittmanmead.com/bigdata Additional Resources
- 43. info@rittmanmead.com www.rittmanmead.com @rittmanmead Unlock the Value in your Big Data Reservoir using Oracle Big Data Discover Mark Rittman, CTO, Rittman Mead IlOUG Tech Days 3, Tel Aviv, May 2016