Infrastructure optimization for seismic processing (eng)
•
0 likes•1,603 views

NetProject is a system integrator focused on building optimized IT infrastructure for seismic data processing applications. They aim to configure hardware and software to maximize application performance while minimizing costs. Key optimization strategies include choosing the right CPU, RAM, and server configurations; utilizing RDMA for efficient data transfer; offloading processing to GPUs; selecting high-performance file systems and storage; and optimizing resource scheduling and infrastructure management. NetProject leverages their expertise in oil and gas IT to help customers improve seismic processing performance.
Report
Share




































Infrastructure optimization for seismic processing (eng)
- 1. Performance Boost for Seismic Processing with right IT infrastructure Vsevolod Shabad vshabad@netproject.ru CEO and founder +7 (985) 765-76-03
- 2. NetProject at a glance System integrator with strong oil&gas focus: we build and expand the IT infrastructure for Geological and Geophysical applications 2
- 3. How to make the HPC right balanced? The applications performance must be limited only by the licenses: •Paradigm ES 360, GeoDepth, Echos •Schlumberger Omega •Landmark SeisSpace ProMAX •CGG Geocluster with minimal overall cost 3
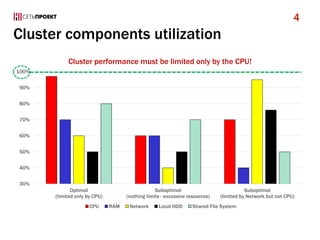
- 4. Cluster components utilization 30% 40% 50% 60% 70% 80% 90% 100% Optimal (limited only by CPU) Suboptimal (nothing limits - excessive resources) Suboptimal (limited by Network but not CPU) Cluster performance must be limited only by the CPU! CPU RAM Network Local HDD Shared File System 4
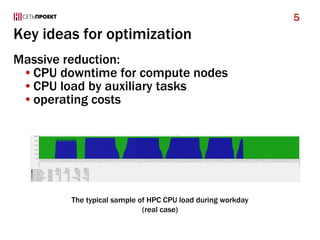
- 5. Key ideas for optimization Massive reduction: •CPU downtime for compute nodes •CPU load by auxiliary tasks •operating costs 5 The typical sample of HPC CPU load during workday (real case)
- 6. Candidates for optimization Compute nodes File nodes and storage Management nodes and resource schedulers Cluster interconnect Backup and restore subsystem Monitoring and management subsystem Cooling subsystem 6
- 7. Compute nodes optimization CPU & RAM: optimal choice CPU offload with RDMA CPU offload with GPU Right form factor of servers 7
- 8. CPU & RAM: optimal choice sample Part Haswell-EP (Xeon E5-2600 v3) Broadwell-EP (E5-2600 v4) Server type HPE ProLiant XL230a Gen9 CPU 2x Xeon E5-2650 v3 (20 cores, 2.3 GHz) 2x Xeon E5-2680 v4 (28 cores, 2.4 GHz) RAM 160 GB (8 GB/core) PC4-2133 224 GB (8 GB/core) PC4-2400 HDD 2x 1.8 TB SAS 10K RPM Network 1x Infiniband FDR, 4x GigE List Price, USD 17 456 18 366 Performance, TFLOPS 0.74 1.08 List Price per core, USD 872.8 655.9 (–24.8%) List Price per TFLOPS, USD 23 713.4 17 081.5 (–28.0%) 8 Typical compute node for Paradigm ES 360
- 9. CPU & RAM: non-optimal choice sample Part Broadwell-EP (E5-2600 v4) Broadwell-EP (E5-2600 v4) Server type HPE ProLiant XL230a Gen9 CPU 2x Xeon E5-2680 v4 (28 cores, 2.4 GHz) 2x Xeon E5-2699 v4 (44 cores, 2.2 GHz) RAM 224 GB (8 GB/core) PC4-2400 352 GB (8 GB/core) PC4-2400 HDD 2x 1.8 TB SAS 10K RPM Network 1x Infiniband FDR, 4x GigE List Price, USD 18 366 36 396 Performance, TFLOPS 1.08 1.55 List Price per core, USD 655.9 827.2 (+26.1%) List Price per TFLOPS, USD 17 081.5 23 499,5 (+37,6%) 9 Typical compute node for Paradigm ES 360
- 10. Some non-obvious restrictions HPE Proliant XL230a Gen9: •can‘t work with single CPU •two same processors required •can‘t use the 32GB RDIMM for DDR4 RAM •only LRDIMM for 32GB DDR4 allowed •… Fujitsu CX400 M1: •can‘t use two Infiniband HBAs with liquid cooling •only one Infiniband HBA allowed •… … 10
- 11. CPU offload with RDMA Direct buffer-to-buffer data move without CPU and operating system
- 12. CPU offload with RDMA RDMA usage in HPC: •between compute nodes •between compute node and file node (storage) 12
- 13. Sample of RDMA efficiency 13 Source: http://cto.vmware.com/wp- content/uploads/2012/09/RDMAonvSphere.pdf
- 14. RDMA must be supported by the apps! Seismic processing: •Paradigm ES 360, GeoDepth, Echos •since version 15.5 •Schlumberger Omega, Landmark ProMAX •with MPI File systems: •IBM Spectrum Scale (ex GPFS) •Lustre •BeeGFS (ex FhGFS) 14
- 15. CPU offload with GPU Paradigm: •Echos RTM Schlumberger: •Omega RTM, Kirchhoff Tsunami: •Tsunami RTM … 15 Full list: http://www.nvidia.co.uk/content/EMEAI/PDF/tesla- gpu-applications/gpu-apps-catalog-eu.pdf
- 16. Sample of GPU efficiency Statoil custom seismic processing application NVIDIA GPU (GeForce GTX280) Source: http://www.idi.ntnu.no/~elster/master-studs/owej/owe-johansen-master- ntnu.pdf 16
- 17. Right form factor of servers Rack-optimized 1U •HPE Proliant DL360 Gen9, … Rack-optimized 2U •Fujitsu RX2540 M2, … High-density servers •Lenovo NeXtScale M5, … Blade servers •DELL M1000e, … 17
- 18. Typical high-density chassis Chassis Number of nodes Chassis height, RU Lenovo NeXtScale n1200 12 6 HPE Apollo 2000 4 2 HPE Apollo a6000 10 5 (+1.5) Fujitsu Primergy CX400 S2 4 2 Huawei X6800 8 4 DELL PowerEdge FX2 8 2 DELL PowerEdge C6320 4 2 18
- 19. File nodes and storage Right choice of file system with RDMA и QoS High-density block storage arrays Short IOPS caching with SSD File system overhead reduction Backup to Redirect-On-Write snapshots Transparent data migration to tapes 19
- 20. Right choice of file system IBM Spectrum Scale (GPFS) Lustre (+ ZFS) BeeGFS Panasas PanFS EMC Isilon Huawei 9000 NetApp FAS (NFS) RDMA support at client side Yes Yes Yes No No Redirect-On-Write snapshot support Yes Yes (with ZFS) No Yes Yes Transparent migration to tape Yes No No No No Commercial support Yes “Yes” (no for ZFS- on-Linux) Yes Yes Yes Installation difficulty High High High Low Low Single-Thread performance Moderate Low High Low Low 20
- 21. File system overhead sample 21 Source: http://wiki.lustre.org/images/b/b2/Lustre_on_ZFS-Ricardo.pdf
- 22. Right choice of block storage array Requirements sample (moderate cluster for SLB Omega): •I/O throughput — 3 GB/sec on sequential I/O •usable capacity — 300 TB Solutions: •EMC VNX5400 — 174 spindles, 39 RU •NetApp E5600 — 69 spindles, 12 RU Front-end I/O ports options: •SAS, Fibre Channel, 10GbE, Infiniband NetApp E5600 disk array supports iSER connection via Infiniband fabric (without FC & SAS) 22
- 23. Short IOPS caching with SSD Most applicable for: •metadata •trace headers File system support: •IBM Spectrum Scale: •Highly-available write cache (HAWC) •Local Read-Only Cache (LROC) •Panasas ActiveStor: •internal Panasas ActiveStor capabilities •Lustre: •no •EMC Isilon: •SmartFlash 23
- 24. Backup to Redirect-On-Write snapshots Traditional backup to tapes: •500 TB of data, verification after write •four LTO-7 (300 MB/sec) drives: •500 000 000 / (4 * 300 * 2 * 3600) = 58 hours under ideal conditions Innovative backup (snapshots): •10 minutes regardless of data volume 24
- 25. Transparent data migration to tapes Middleware: IBM Spectrum Archive (LTFS) Drives IBM TS1150: 360 MB/s, 10 TB per cartridge 25
- 26. Resource schedulers Cluster usage alignment and optimization Energy aware scheduling Top-3 systems: •IBM Spectrum LSF (Platform LSF) •Altair PBS Pro •Adaptive Computing MOAB HPC Suite 26
- 27. Cluster interconnect Key technology — RDMA Two options: •Infiniband FDR/EDR •Ethernet 40G/56G/100G (with RoCE) 27
- 28. Backup and restore subsystem Protection from logical data damage •with Redirect-On-Write snapshots Protection from от physical data damage is not necessary •with dedicated seismic data archive on LTO-7 tapes 28
- 29. Snapshot technologies comparative Redirect-On-Write Copy-On-Write NetApp FAS3240 IBM Storwize v7000 Source: NetProject’s comparative testing for JSC NOVATEK (2012) 29
- 30. Monitoring and management Dedicated Gigabit Ethernet fabric Management software: •Altair PBS Pro + HPE CMU •IBM Platform Cluster Manager 30
- 31. Cooling subsystem Air conditioning: •applicable for any equipment (up to 15 кW/rack) •temperature range could be expanded Liquid conditioning: •equipment adaptation or “liquid cooling rack door” required •high level of data center density 31
- 32. Temperature range expansion 4% operational savings from cooling for every 10 C increase in operating temperature (Intel, IDC, Gartner) Incompatible: •with NVIDIA GRID •with CPU > 120W ATD module price for Fujitsu Primergy is 26 USD! 32
- 33. Our product portfolio: Servers: •Lenovo, HPE, DELL, Fujitsu, Cisco, Huawei, Intel, Supermicro, Inspur, Sugon, … Storage: •NetApp, IBM, HDS, Panasas, Huawei, EMC, … Network: •Mellanox, Cisco, Lenovo, Huawei, Brocade Tape libraries: •IBM, HPE, Quantum Resource scheduling tools: •IBM Platform, Altair, Adaptive Computing 33
- 34. Company strengths Strong industry focus on G&G IT infrastructure Deep knowledge and experience: •Industry specifics and major applications: •better than most system integrators and IT infrastructure vendors •IT infrastructure products and technologies •better than most G&G software vendors Advanced project management methodology Structured knowledgebase of past projects High engineering culture of staff Deep customer involvement in projects 34
- 35. Company weaknesses Strong industry focus on G&G IT infrastructure Low level of company brand recognition Lack of overseas market experience A small number of employees Limited financial resources 35
- 36. Company background in a brief Technology experience: •Networking since 1996 •Storage since 2004 •Servers since 2006 •VDI since 2010 •HPC since 2014 Oil & Gas industry focus since 2012 •metallurgy and banking focus in 1996-2014 Big Data experience since 2007 ISO 9001:2008 certified since 2012 36
- 37. Partner reference about NetProject At the last time we are increasingly ask NetProject for consulting about hardware configurations, clusters, workstations, and infrastructure solutions. This company's team has participated in the creation of the various data center architectures for the wide spectrum of Paradigm technologies and has proved itself from the best side. Serge Levin, Paradigm Geophysical (Russia) Sales Director 37
- 38. A proven way to win! Join to us! http://www.netproject.ru/ 38