








































Integration Patterns for Big Data Applications
- 1. Big Data Integration Patterns Michael Häusler Jun 12, 2017
- 2. The social network gives scientists new tools to connect, collaborate, and keep up with the research that matters most to them. ResearchGate is built for scientists.
- 3. Our mission is to connect the world of science and make research open to all.
- 4. 12+ million Members 100+ million Publications 1,500+ million Citations
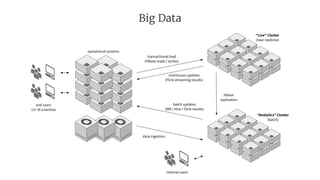
- 5. operational systems end users 12+ M scientists “Analytics” Cluster (batch) “Live” Cluster (near realtime) internal users HBase replication transactional load (HBase reads / writes) continuous updates (Flink streaming results) batch updates (MR / Hive / Flink results) data ingestion Big Data
- 6. 65+ 370+ 3,000+ Engineers Data Ingestion Jobs per Day Big Data Yarn Applications per Day
- 7. 65+ 3,000+ Engineers Yarn Applications per Day Developer Productivity Ease of Maintenance Ease of Operations
- 8. Big Data Architecture Integration Patterns & Pricinicples
- 9. Patterns & Principles Integration patterns should be strategic, but also ... should be driven by use cases should tackle real world pain points should not be dictated by a single technology
- 10. Patterns & Principles Big data is still a fast moving space Big data batch processing today is quite different compared to 5 years ago Big data stream processing is evolving heavily right now Big data architecture must evolve over time
- 11. First Big Data Use Case Early 2011, Author Analysis
- 12. Author Analysis – Clustering and Disambiguation
- 13. Author Analysis – High Product Impact
- 14. Enriching User Generated Content Users and batch flows continuously enrich an evolving dataset Both user actions and batch flow results ultimately affect the same live database Users Live Database Batch flow
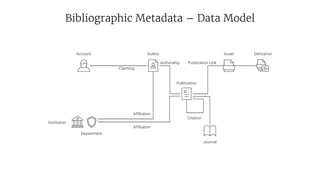
- 15. Bibliographic Metadata – Data Model Author Asset Derivative Publication Journal Institution Department Account Affiliation Citation Authorship Publication Link Affiliation Claiming
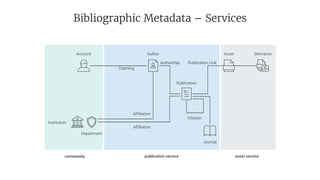
- 16. community publication service asset service Bibliographic Metadata – Services Author Asset Derivative Publication Journal Institution Department Account Affiliation Citation Authorship Publication Link Affiliation Claiming
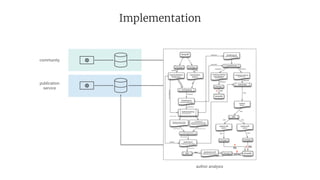
- 18. Implementation publication service author analysis community data sources data ingestion input data data processing intermediate results final results export of results differ
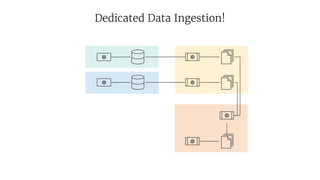
- 19. #1 Decouple Data Ingestion
- 20. Implementation publication service author analysis community postgres reuse input data mongodb debug
- 21. Debugging an Error on Production Your flow has unit and integrations tests but still breaks unexpectedly in production You need to find the root cause Is it a change in input data? Is it a change on the cluster? Is it a race condidition? Crucial capabilities Easy adhoc analysis of all involved data (input, intermediate, result) Rerun current flow with current cluster configuration on yesterday’s data Confirm hotfix by re-running on today’s data (exactly the same data that triggered the bug)
- 22. How to decouple?
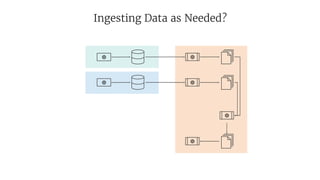
- 23. Ingesting Data as Needed?
- 24. Publishing Data as Needed?
- 26. Platform Data Import ... Hive... Adhoc Analytics
- 27. Platform Data Import Dedicated component, but generic Every team can onboard new data sources, as required by use cases Every ingested source is immediately available for all consumers (incl. analytics) Feature parity for all data sources (e.g., mounting everything in Hive)
- 28. #2 Speak a common format* * have at least one copy of all data in a common format (e.g., avro)
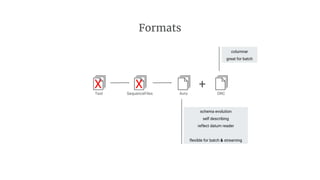
- 29. Formats Text SequenceFiles Avro ORC X X + schema evolution self describing reflect datum reader flexible for batch & streaming columnar great for batch
- 30. Speak a common format Have at least one copy of all data in a common format Your choice of processing framework should not be limited by format of existing data Every ingested source should be available for all consumers When optimizing for a framework (e.g., ORC for Hive) consider a copy
- 31. #3 Speak a common language* * continuously propagate schema changes
- 32. Structured or unstructured data? ... ... mongodb (schemaless) service knows structure postgres (schema)
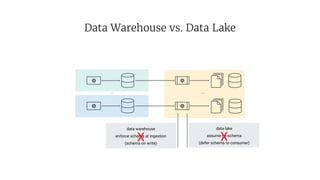
- 33. Data Warehouse vs. Data Lake ... ... data lake assume no schema (defer schema to consumer) data warehouse enforce schema at ingestion (schema on write) X X
- 34. Can we have both? Preserve schema information that is already present some times at database level many times at application level Preserve full data – be truthful to our data source continuously propagate schema changes Can we have something like a Data Lakehouse?
- 35. Entities Define Schema Code first entities within owning service define schema Auto conversion preferred conversion to other representations via annotations (JSON, BSON, Avro, ...)
- 36. Continuously propagate schema changes Data ingestion process is generic and driven by avro schema Changes in avro schema are continuously propagated to data ingestion process Consumers with old schema can still read data due to avro schema evolution Caveat: breaking changes still have to be dealt with by a change process Everyone speaks the same language
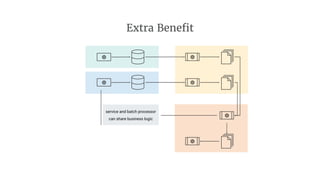
- 37. Extra Benefit service and batch processor can share business logic
- 38. #4 Model Data Dependencies Explicitly
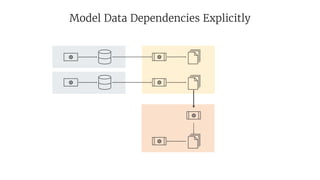
- 39. Model Data Dependencies Explicitly
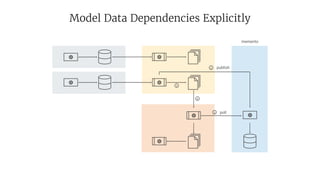
- 40. Model Data Dependencies Explicitly memento publish poll 1 2 3 4
- 41. Memento v2 memento publish unique artifactId memento poll <waiting-time>
- 42. Model Data Dependencies Explicitly More flexible scheduling – run flows as early as possible Allows multiple ingestion or processing attempts Allows immutable data (repeatable read) Allows analysis of dependency graph which datasets are used by what flow
- 43. #5 Decouple export of results
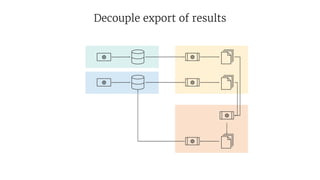
- 44. Decouple export of results
- 45. Decouple export of results
- 46. Push results via HTTP to service Export of results just becomes a client of the service service does not have to be aware of big data technologies Service can validate results, e.g., plausibility checks optimistic locking Makes testing much easier
- 47. Avro → Http Part of the flow, but standardized component Handles tracking of progress treats input file as a “queue” converts records to http calls can be interrupted and resumed anytime Sends standardized headers, e.g., X-rg-client-id: author-analysis Handles backpressure signals from services
- 48. #6 Model Flow Orchestration Explicitly
- 49. Model Flow Orchestration Explicitly Consider using an execution system like Azkaban, Luigi, or Airflow Establish coding standards for orchestration, e.g., inject paths from outside – don’t construct them in your flow inject calculation dates – never call now() inject configuration settings – don’t hardcode -D mapreduce.map.java.opts=-Xmx4096m foresee environment specific settings Think about ease of operations tuning of settings upgrades
- 50. What about Stream Processing?
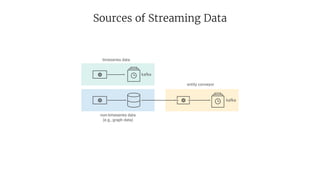
- 51. Sources of Streaming Data entity conveyor timeseries data non-timeseries data (e.g., graph data) kafka kafka
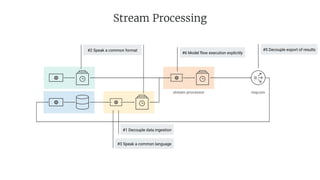
- 52. Stream Processing stream processor mqcom #2 Speak a common format #5 Decouple export of results #1 Decouple data ingestion #3 Speak a common language #6 Model flow execution explicitly
- 53. What about #4 ? Model Data Dependencies Explicitly We think about it Depends on use cases and pain points Potentially put Kafka topics into Memento storing “offsets of interest” from producers facilitate switching between incompatible versions of stream processors
- 54. Evolving Big Data Architecture stream processor batch processor
- 55. Thank you! Michael Häusler, Head of Engineering https://www.researchgate.net/profile/Michael_Haeusler https://www.researchgate.net/careers