

















Intro to Delta Lake
- 1. Introduction to Delta Lake Bring reliability, performance, and security to your data Himanshu Raja, Sr. Manager, Product Brenner Heinz, Technical PMM Barbara Eckman, Senior Principal Software Architect at Comcast
- 2. Every company is becoming a data company ML-driven actuarial modeling increases the predictability & accuracy of insurance pricing Identification of dementia 8 years earlier than traditional diagnosis with deep learning on images Personalize the gaming experience with tailored offers for 67M+ gamers Increased audience engagement with an Emmy winning voice- powered experience Support contact tracing for over 60 million UK citizens and predict the spread of COVID-19
- 3. The future is here, it’s just not very evenly distributed CEOs say AI is a strategic priority 83% Business value created by AI in 2022 $3.9T Of big data projects fail 85% Of data science projects never make it into production 87%
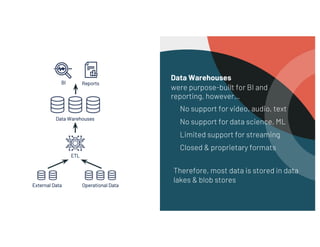
- 4. Data Warehouses were purpose-built for BI and reporting, however… No support for video, audio, text No support for data science, ML Limited support for streaming Closed & proprietary formats Therefore, most data is stored in data lakes & blob stores
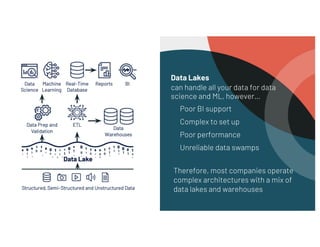
- 5. Data Lakes can handle all your data for data science and ML, however… Poor BI support Complex to set up Poor performance Unreliable data swamps Therefore, most companies operate complex architectures with a mix of data lakes and warehouses
- 6. How do we get the best of both worlds?
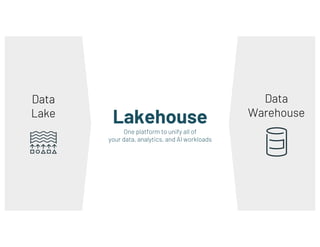
- 7. Data Warehouse Lakehouse One platform to unify all of your data, analytics, and AI workloads Data Lake
- 8. Data Engineering SQL Analytics & BI Integration Real-time Data Applications Machine Learning Data Management & Governance Lakehouse Platform Platform Security & Administration Data Science Integrated and collaborative role-based experiences Structured Semi-structured Unstructured Streaming Open Data Lake
- 9. Data Warehouse Data Lake An open approach to bringing data management and governance to data lakes Better reliability with transactions 48x faster data processing with indexing Data governance at scale with fine- grained access control lists
- 10. High quality, reliable data Deliver a reliable single source of truth - for both batch and streaming - on the freshest, most complete set of data. Key Features: ACID Transaction Schema Enforcement Unified Batch and Streaming Schema Evolution Merges, Updates, & Deletes Time travel Clones 50% faster time-to-insight Transactional Log Parquet Files Streaming Batch Updates/Deletes
- 11. Lightning fast performance Modernize your ETL data pipelines and optimize for peak performance without compromising reliability. Delta Engine - a high performance query engine - gives you superior price/performance than a data warehouse on your Delta Lake. 48x faster ETL workloads
- 12. Security and compliance at scale Quickly and accurately update data in your data lake and keep track of historical versions of data to comply with government regulations like GDPR and CCPA. Maintain better data governance with secure access controls to the data in Delta Lake.
- 13. Open and agile Leverage vast open-source ecosystem and avoid vendor lock-in with Delta Lake. Standardize big data storage in your own ecosystem, in open Parquet format, that can be consumed by other systems outside of Databricks.
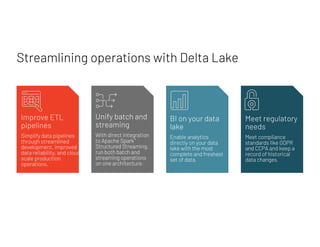
- 14. Streamlining operations with Delta Lake Improve ETL pipelines Simplify data pipelines through streamlined development, improved data reliability, and cloud- scale production operations. Unify batch and streaming With direct integration to Apache Spark! Structured Streaming, run both batch and streaming operations on one architecture. BI on your data lake Enable analytics directly on your data lake with the most complete and freshest set of data. Meet regulatory needs Meet compliance standards like GDPR and CCPA and keep a record of historical data changes.
- 15. Building a Lakehouse Foundation Across Industries Energy & Utilities Digital Native Healthcare & Life Sciences Financial Services Manufacturing & Automotive Media & Entertainment Public Sector Retail & CPG
- 16. Exabytes of data processed / day 75% Data Scanned 3K+ Customers in Production
- 17. Demand forecasting & personalized experiences ■ 1000+ data pipelines; 50-100x faster data processing; 15 minutes to deploy ML models ■ Fine-grained forecasts right down to the SKU, store and day ■ Double-digit improvements in accuracy across 30,000 retail locations Inventory management & supply chain optimization ■ 32x faster inventory analysis and predictions ■ Millions of dollars in cost savings ■ 50+ locations worldwide positively impacted by ability to better predict inventory Audience engagement with a voice-powered experience ■$9M reduction in compute costs ■30% improvement in data science productivity ■Massive performance gains replacing 640 machines with 64
- 18. Delta Lake Innovation Velocity Q1/Q2 2018 Q3/Q4 2018 Q1/Q2 2019 Q3/Q4 2019 Q3/Q4 2017 ●DESCRIBE DETAIL ●IgnoreChanges for streams ●Expanded DDL ●OPTIMIZE scalability ●Schema enforcement, evolution ●Correction verification ●Parallel checkpointing ●Optimized Writes ●Auto Compaction ●Presto/Athena support ●Metadata query optimizations ●Open Source! ●Z-ORDER scalability ●Scala/Python DML APIs ●Convert to Delta from Metastore ●Spark 3.0 support ●Aggregate function perf ●Auto Loader streaming ingestion ●COPY INTO batch data ingestion ●Detailed operational metrics ●MERGE schema evolution ●MERGE perf ●ACID transactions ●Snapshot isolation ●Stream/Batch Support ●Fine-grained conflict detection ●Delta Cache (SSD) ●OPTIMIZE, VACUUM, MERGE, HISTORY ●S3 & S3-SQS streaming source ●Data skipping ●Z-ORDER BY ●Multi-cluster writes ●Bloom filters Q1/Q2 2020 Q3/Q4 2020 ●Table CLONE ●Auto Loader listing support ●User tags for commits ●Enhanced checkpoints - low latency queries ●Improved query latencies ●Vectorized reader/writer ●MERGE perf with pruning ●Merge INTO supports schema evolution of nested columns and optimized writes ●CDC record emission ●Expanded column constraints ●Table RESTORE ●Time Travel ●Async updates ●MERGE & OPTIMIZE scalability ●FSCK REPAIR ●Incremental Z-ORDER ●Subquery for del/update ●Isolation level support ●Easy CONVERT TO DELTA ●Extended MERGE syntax Q1 2021 ●Better JSON schema evolution handling in Auto Loader ●Support for reading overwritten files in Auto Loader ●Better multi-dimensional clustering and data skipping performance with OPTIMIZE ZORDER ●Auto-tuning file sizes for MERGE-heavy Delta tables ●Delta as default format ●New SQL operators reduce complex ETL on JSON strings ●Track stream progress with Delta Lake streaming source metrics
- 19. What Delta Lake can do for you Scale data insights throughout your organization with a simplified solution Provide best price/performance Enable a multi-cloud, secure infrastructure The foundation of your lakehouse
- 20. Demo
- 21. Thank you!
- 22. Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.