




Lstm
- 1. Long Short Term Memory (LSTM) 1 Mehrnaz Faraz Faculty of Electrical Engineering K. N. Toosi University of Technology Milad Abbasi Faculty of Electrical Engineering Sharif University of Technology
- 2. Contents • Introduction • Vanishing/Exploding Gradient Problem • Long Short Term Memory • LSTM Variations • CNN-LSTM • BiLSTM • Fuzzy-LSTM 2
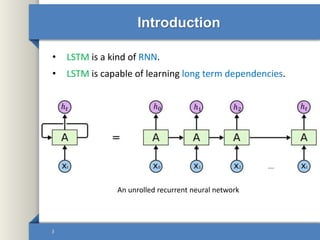
- 3. Introduction • LSTM is a kind of RNN. • LSTM is capable of learning long term dependencies. 3 An unrolled recurrent neural network ℎ 𝑡 ℎ0 ℎ1 ℎ2 ℎ 𝑡
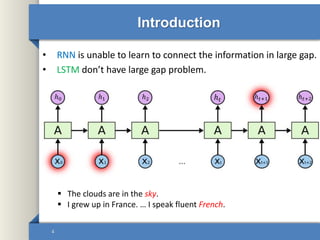
- 4. Introduction • RNN is unable to learn to connect the information in large gap. • LSTM don’t have large gap problem. 4 The clouds are in the sky. I grew up in France. … I speak fluent French. ℎ 𝑡 ℎ 𝑡+1 ℎ 𝑡+2ℎ2ℎ1ℎ0
- 5. Introduction • Using LSTM: – Robot control – Time series prediction – Speech recognition – Rhythm learning – Music composition – Grammar learning – Handwriting recognition – Human action recognition – End to end translation 5
- 6. Introduction • Using LSTM: – Google • Speech recognition on the smartphone • Smart assistant Allo – Amazon • Amazon Alexa 6
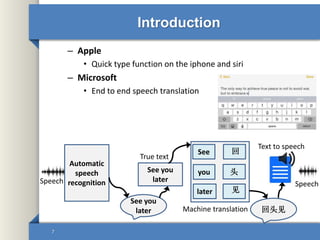
- 7. Introduction – Apple • Quick type function on the iphone and siri – Microsoft • End to end speech translation 7 Automatic speech recognition See you later See you later See you later 头 回 见 回头见 Text to speech SpeechSpeech Machine translation True text
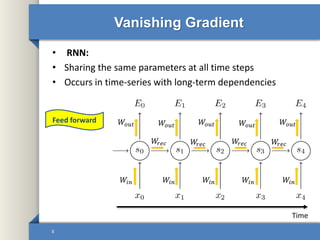
- 8. Vanishing Gradient • RNN: • Sharing the same parameters at all time steps • Occurs in time-series with long-term dependencies 8 𝑊𝑖𝑛 𝑊𝑖𝑛𝑊𝑖𝑛𝑊𝑖𝑛𝑊𝑖𝑛 𝑊𝑜𝑢𝑡 𝑊𝑜𝑢𝑡𝑊𝑜𝑢𝑡𝑊𝑜𝑢𝑡𝑊𝑜𝑢𝑡 𝑊𝑟𝑒𝑐 𝑊𝑟𝑒𝑐𝑊𝑟𝑒𝑐𝑊𝑟𝑒𝑐 Time Feed forward
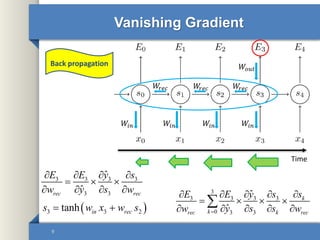
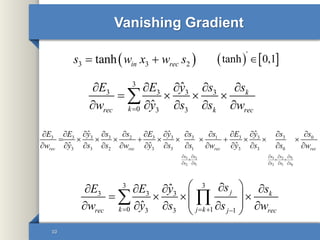
- 9. Vanishing Gradient 9 𝑊𝑖𝑛 𝑊𝑖𝑛𝑊𝑖𝑛𝑊𝑖𝑛 𝑊𝑜𝑢𝑡 𝑊𝑟𝑒𝑐 𝑊𝑟𝑒𝑐𝑊𝑟𝑒𝑐 Time Back propagation 3 3 3 3 3 3 ˆ ˆrec rec E E y s w y s w 3 3 2tanh in recs w x w s 3 3 3 3 3 0 3 3 ˆ ˆ k krec k rec E E y s s w y s s w
- 10. Vanishing Gradient 10 3 3 3 3 3 0 3 3 ˆ ˆ k krec k rec E E y s s w y s s w 3 3 2tanh in recs w x w s 3 2 3 2 1 2 1 2 1 0 3 3 3 3 2 3 3 3 1 3 3 3 0 3 3 2 3 3 1 3 3 0 ˆ ˆ ˆ ˆ ˆ ˆrec rec rec rec s s s s s s s s s s E E y s s E y s s E y s s w y s s w y s s w y s s w 33 3 3 3 0 13 3 1 ˆ ˆ j k k j krec j rec sE E y s w y s s w ' tanh 0,1
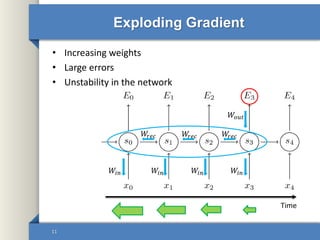
- 11. Exploding Gradient • Increasing weights • Large errors • Unstability in the network 11 𝑊𝑖𝑛 𝑊𝑖𝑛𝑊𝑖𝑛𝑊𝑖𝑛 𝑊𝑜𝑢𝑡 𝑊𝑟𝑒𝑐 𝑊𝑟𝑒𝑐𝑊𝑟𝑒𝑐 Time
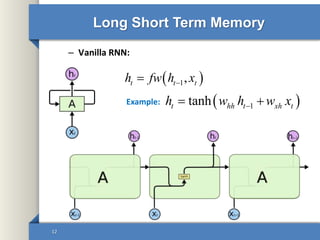
- 12. Long Short Term Memory 12 – Vanilla RNN: 1,t t th fw h x 1tanht hh t xh th w h w x Example:
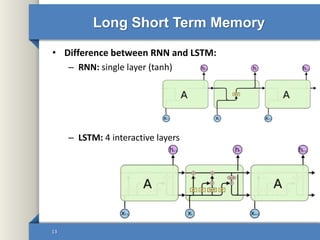
- 13. Long Short Term Memory • Difference between RNN and LSTM: – RNN: single layer (tanh) – LSTM: 4 interactive layers 13
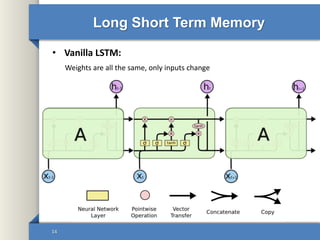
- 14. Long Short Term Memory • Vanilla LSTM: 14 Weights are all the same, only inputs change
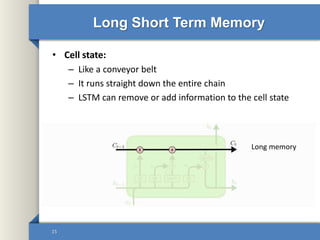
- 15. Long Short Term Memory • Cell state: – Like a conveyor belt – It runs straight down the entire chain – LSTM can remove or add information to the cell state 15 Long memory
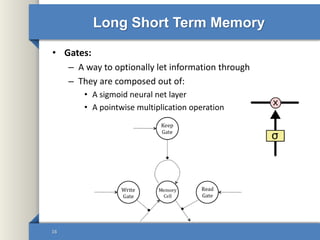
- 16. Long Short Term Memory • Gates: – A way to optionally let information through – They are composed out of: • A sigmoid neural net layer • A pointwise multiplication operation 16
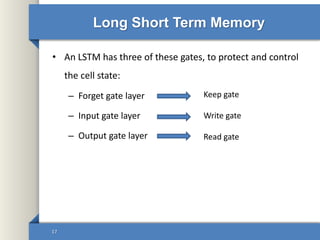
- 17. Long Short Term Memory • An LSTM has three of these gates, to protect and control the cell state: – Forget gate layer – Input gate layer – Output gate layer 17 Keep gate Write gate Read gate
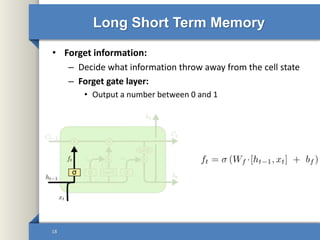
- 18. Long Short Term Memory • Forget information: – Decide what information throw away from the cell state – Forget gate layer: • Output a number between 0 and 1 18
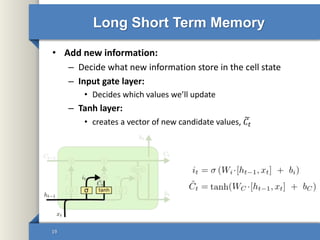
- 19. Long Short Term Memory • Add new information: – Decide what new information store in the cell state – Input gate layer: • Decides which values we’ll update – Tanh layer: • creates a vector of new candidate values, 𝐶𝑡 19
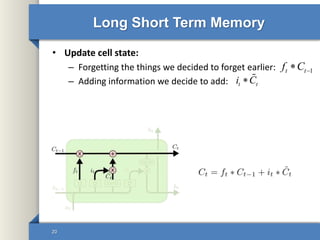
- 20. Long Short Term Memory • Update cell state: – Forgetting the things we decided to forget earlier: – Adding information we decide to add: 20 1t tf C t ti C
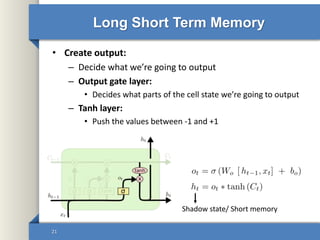
- 21. Long Short Term Memory • Create output: – Decide what we’re going to output – Output gate layer: • Decides what parts of the cell state we’re going to output – Tanh layer: • Push the values between -1 and +1 21 Shadow state/ Short memory
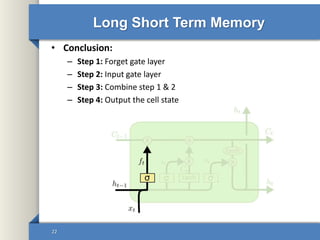
- 22. Long Short Term Memory • Conclusion: – Step 1: Forget gate layer – Step 2: Input gate layer – Step 3: Combine step 1 & 2 – Step 4: Output the cell state 22
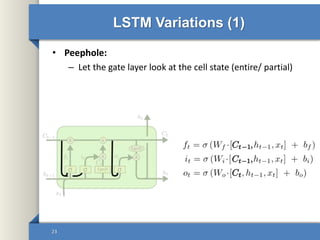
- 23. LSTM Variations (1) • Peephole: – Let the gate layer look at the cell state (entire/ partial) 23
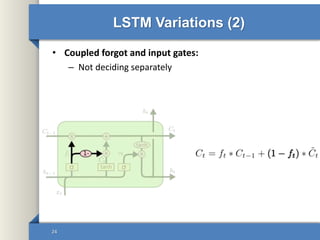
- 24. LSTM Variations (2) • Coupled forgot and input gates: – Not deciding separately 24
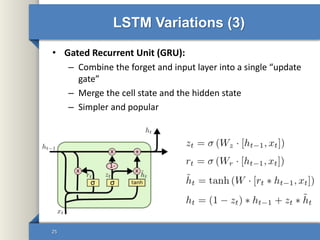
- 25. LSTM Variations (3) • Gated Recurrent Unit (GRU): – Combine the forget and input layer into a single “update gate” – Merge the cell state and the hidden state – Simpler and popular 25
- 26. LSTM Variations Comparison • They’re all about the same in performance • We can reduce the number of parameters and the computational cost by: – Coupling the input and forget gates (GRU, Variation #2) – Removing peephole connections (Vanilla LSTM) 26 Greff, K., et al. (2017). LSTM: A search space odyssey. IEEE transactions on neural networks and learning systems.
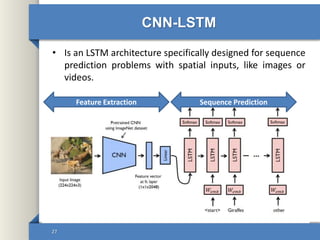
- 27. CNN-LSTM • Is an LSTM architecture specifically designed for sequence prediction problems with spatial inputs, like images or videos. 27 Feature Extraction Sequence Prediction
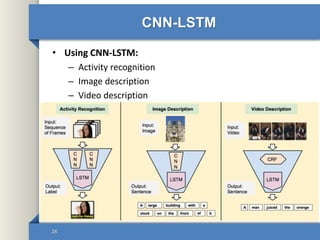
- 28. CNN-LSTM • Using CNN-LSTM: – Activity recognition – Image description – Video description 28
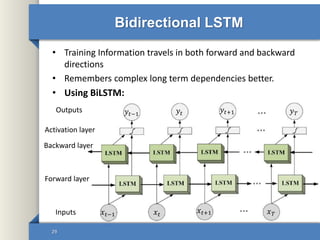
- 29. Bidirectional LSTM • Training Information travels in both forward and backward directions • Remembers complex long term dependencies better. • Using BiLSTM: 29 𝑦𝑡−1 𝑦𝑡 𝑦𝑡+1 𝑦 𝑇 𝑥 𝑡−1 𝑥 𝑡 𝑥 𝑡+1 𝑥 𝑇 Outputs Activation layer Backward layer Forward layer Inputs
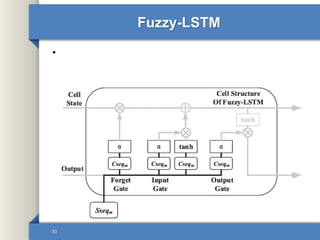
- 30. Fuzzy-LSTM • 30
- 31. 31 Thank you