













LSTM Tutorial
- 1. Long Short Term Memory Neural Networks Short Overview and Examples Ralph Schlosser https://github.com/bwv988 February 2018 Ralph Schlosser Long Short Term Memory Neural Networks February 2018 1 / 18
- 2. Overview Agenda RNN Vanishing / Exploding Gradient Problem LSTM Keras Outlook Demo Links Git repo: https://github.com/bwv988/lstm-neural-net-tests Demo: https://www.kaggle.com/ternaryrealm/ lstm-time-series-explorations-with-keras Ralph Schlosser Long Short Term Memory Neural Networks February 2018 2 / 18
- 3. RNN Recurrent Neural Networks (RNN) are an extension to traditional feed forward NN. Original application: Sequence data, e.g.: Music, video Words in a sentence Financial data Image patterns Main advantage over traditional (D)NNs: Can retain state over a period of time. There are other tools to model sequence data, e.g. Hidden Markov Models. But: Becomes computationally unfeasible for modelling large time dependencies. Today, RNNs often outperform classical sequence models. Ralph Schlosser Long Short Term Memory Neural Networks February 2018 3 / 18
- 4. Elements of a simple RNN Input layer: x with weight θx . Hidden, recursive layer (feeds back into itself): h with weight θ. Output layer: y with weight θy . Arbitrary (e.g. RELU) activation function φ(·). ht = θφ(ht−1) + θx xt yt = θy φ(ht) Ralph Schlosser Long Short Term Memory Neural Networks February 2018 4 / 18
- 5. Unrolling the Recursion We can see how this is applicable to sequence data when unrolling the recursion: Ralph Schlosser Long Short Term Memory Neural Networks February 2018 5 / 18
- 6. Vanishing / Exploding Gradient Problem Training the RNN means: Perform backpropagation to find optimal weights. Need to minimize the error (or loss) function E wrt., say, parameter θ. Optimization problem for S steps: ∂E ∂θ = S t=1 ∂Et ∂θ Applying the chain rule gives that for a particular time step t, and looking at θk happening in layer k: ∂Et ∂θ = t k=1 ∂Et ∂yt ∂yt ∂ht ∂ht ∂hk ∂hk ∂θ Ralph Schlosser Long Short Term Memory Neural Networks February 2018 6 / 18
- 7. Vanishing / Exploding Gradient Problem The issue is with the term ∂ht ∂hk . Further maths shows (omitting many, many details): ∂ht ∂hk ≤ ct−k Here: c is some constant term related to θ and the choice of the activation function φ. Problem: c < 1: Gradients tend to zero (vanish). c > 1: Gradients will tend to infinity (explode). Impact of vanishing gradients to RNN: Can’t “remember” impacts of long sequences. Ralph Schlosser Long Short Term Memory Neural Networks February 2018 7 / 18
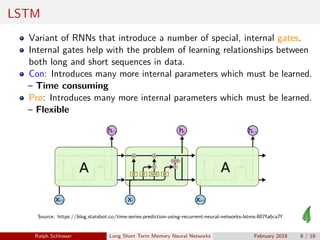
- 8. LSTM Variant of RNNs that introduce a number of special, internal gates. Internal gates help with the problem of learning relationships between both long and short sequences in data. Con: Introduces many more internal parameters which must be learned. – Time consuming Pro: Introduces many more internal parameters which must be learned. – Flexible Source: https://blog.statsbot.co/time-series-prediction-using-recurrent-neural-networks-lstms-807fa6ca7f Ralph Schlosser Long Short Term Memory Neural Networks February 2018 8 / 18
- 9. LSTM Gates Input gate i: Takes previous output ht−1 and current input xt. it ∈ (0, 1) it = σ(θxi xt + θhtht−1 + bi ) Forget gate f : Takes previous output ht−1 and current input xt. ft ∈ (0, 1) ft = σ(θxf xt + θhf ht−1 + bf ) If ft = 0: Forget previous state, otherwise pass through prev. state. Read gate g: Takes previous output ht−1 and current input xt. gt ∈ (0, 1) gt = σ(θxg xt + θhg ht−1 + bg ) Ralph Schlosser Long Short Term Memory Neural Networks February 2018 9 / 18
- 10. LSTM Gates Cell gate c: New value depends on ft, its previous state ct−1, and the read gate gt. Element-wise multiplication: ct = ft ct−1 + it gt. We can learn whether to store or erase the old cell value. Output gate o: ot = σ(θxoxt + θhoht−1 + bo) ot ∈ (0, 1) New output gate h: ht = ot tanh(ct) Will be fed as input into next block. Intuition: We learn when to retain a state, or when to forget it. Parameters are constantly updated as new data arrives. Ralph Schlosser Long Short Term Memory Neural Networks February 2018 10 / 18
- 11. Practical Part Let’s see this in action sans some of the more technical details. ;) The practical examples are based on Keras: https://keras.io/ First a few words on Keras. Ralph Schlosser Long Short Term Memory Neural Networks February 2018 11 / 18
- 12. Keras Consistent and simple high-level APIs for Deep Learning in Python. Focus on getting stuff done w/o having to write tons of lines of code. Fantastic documentation! Has abstraction layer for multiple Deep Learning backends: Tensorflow CNTK Theano (has reached its final release) mxnet (experimental?) Comparable in its ease of use to sklearn in Python, or mlr in R. Ralph Schlosser Long Short Term Memory Neural Networks February 2018 12 / 18
- 13. Keras Runs Everywhere On iOS, via Apple’s CoreML (Keras support officially provided by Apple). On Android, via the TensorFlow Android runtime. Example: Not Hotdog app. In the browser, via GPU-accelerated JavaScript runtimes such as Keras.js and WebDNN. On Google Cloud, via TensorFlow-Serving. In a Python webapp backend (such as a Flask app). On the JVM, via DL4J model import provided by SkyMind. On Raspberry Pi. Ralph Schlosser Long Short Term Memory Neural Networks February 2018 13 / 18
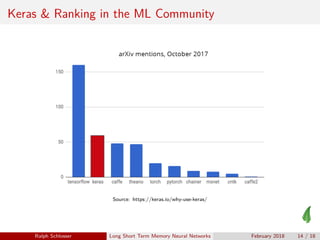
- 14. Keras & Ranking in the ML Community Source: https://keras.io/why-use-keras/ Ralph Schlosser Long Short Term Memory Neural Networks February 2018 14 / 18
- 15. Outlook Some interesting, more recent advances with LSTM. LSTMs are Turing-complete. As a result: Can produce any output a human-made computer program could produce, given sufficient units and weights (and of course time, money, computational power). DNNs are often called universal function approximators; LSTMs are universal program approximators. Ralph Schlosser Long Short Term Memory Neural Networks February 2018 15 / 18
- 16. O M G Is the end of human-made software nigh???? ;) Neural Turing Machines: LSTMs and other techniques can be leveraged to learn (as of yet simple) algorithms from data: https: // arxiv. org/ pdf/ 1410. 5401. pdf Ralph Schlosser Long Short Term Memory Neural Networks February 2018 16 / 18
- 17. Demo Let’s run this one on Kaggle: https://www.kaggle.com/ternaryrealm/ lstm-time-series-explorations-with-keras Ralph Schlosser Long Short Term Memory Neural Networks February 2018 17 / 18
- 18. References Main source for this presentation – Nando de Freitas brilliant lecture: https://www.youtube.com/watch?v=56TYLaQN4N8 Ilya Sutskever PhD thesis: http://www.cs.utoronto.ca/~ilya/ pubs/ilya_sutskever_phd_thesis.pdf “A Critical Review of Recurrent Neural Networks for Sequence Learning”: https://arxiv.org/abs/1506.00019 Why RNNs are difficult to train: https://arxiv.org/pdf/1211.5063.pdf Original LSTM paper: https://www.mitpressjournals.org/doi/ abs/10.1162/neco.1997.9.8.1735 Keras documentation: https://keras.io/ Nice blog post explaining LSTMs: https://blog.statsbot.co/ time-series-prediction-using-recurrent-neural-networks-lst Ralph Schlosser Long Short Term Memory Neural Networks February 2018 18 / 18