

















































Paige Roberts: Shortcut MLOps with In-Database Machine Learning
- 1. Shortcut MLOps with In-Database Machine Learning Paige Roberts Vertica Open Source Relations Manager
- 2. Agenda MLOps – Machine Learning Operations Challenges with Operationalizing ML Is In-Database ML Possible? How Does In-DB ML Help MLOps? How Does In-DB ML Work? Questions
- 3. Advanced Analytics Use Cases are Everywhere It’s not an option; competing on data is the new style of business. Network Optimization Energy Optimization
- 6. A lot of machine learning projects never make it to production https://www.redapt.com/blog/why-90-of-machine- learning-models-never-make-it-to-production https://www.forbes.com/sites/forbestechcouncil/2019/04/03/why- machine-learning-models-crash-and-burn-in-production/ https://thenewstack.io/add-it-up-how-long- does-a-machine-learning-deployment-take/ https://info.algorithmia.com/hubfs/2019/Whitepapers/ The-State-of-Enterprise-ML- 2020/Algorithmia_2020_State_of_Enterprise_ML.pdf https://towardsdatascience.com/why-90-percent-of-all-machine- learning-models-never-make-it-into-production-ce7e250d5a4a
- 7. Data science journey – Now sample extraction ODBC/JDBC Data Preparation & Model Training Model Deployment & Management
- 8. Separation of Dev and Prod Environments is Problematic Development Environment Notebooks – Interactive Python – Pandas, SciKit Tensorflow Training Batch One Instance or single computer Small sample – fits in memory No worries about resource mgmt Production Environment No notebook – Automated Java, Scala JS, C++ Prediction/Inference Streaming Many nodes or instances Full data set – could be huge Concurrent jobs, resource mgmt, autoscaling 8 Tools: Scale:
- 9. Challenges Added Cost Additional hardware and software required. Lots of components to make a whole solution. Requires Down Sampling Cannot process large data sets due to memory and computational limitations, resulting in inaccurate predictions Slower Time to Development Higher turnaround times for model building/scoring and need for moving, transforming large volumes of data between systems Slower Time to Deployment Inability to quickly deploy predictive models into production. Often must be rebuilt in another technology so it will scale. 7
- 10. In-Database Machine Learning End-to-end data science workflow in place SELECT IMPUTE SELECT NORMALIZE SELECT RF_CLASSIFIER SELECT ROC SQL User Defined Functions Distributed Analytical Database
- 11. Is in-database ML really possible?
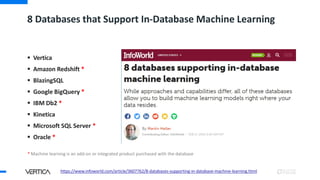
- 12. 8 Databases that Support In-Database Machine Learning Vertica Amazon Redshift * BlazingSQL Google BigQuery * IBM Db2 * Kinetica Microsoft SQL Server * Oracle * https://www.infoworld.com/article/3607762/8-databases-supporting-in-database-machine-learning.html * Machine learning is an add-on or integrated product purchased with the database
- 13. Many analytical databases have full set of ML functions https://www.vertica.com/python/ https://github.com/vertica/VerticaPy Correlations Heteroscedascity Trend & Stationarity Normality Cramer’s V Biserial Point Kendall Spearman Pearson Breush-Pagan Goldfeld-Quandt White’s Lagrange Engle Augmented Dickey-Fuller Mann-Kendall Normaltest Regular Joins Joins XGBoost Random Forest Tree Based Models Linear Regression Logistic Regression LinearSVC Linear Models KMeans Bisecting KMeans Clustering Time Series Joins Spatial Joins
- 14. Deployment/ Management End-to-end machine learning process in database 14 Data Analysis/ Exploration Data Preparation Modeling Evaluation Business Understanding In-Database Scoring Speed at Scale Security Statistical Summary Sessionization Pattern Matching Date/Time Algebra Window/Partition Date Type Handling Sequences and more… Outlier Detection Normalization Imbalanced Data Processing Sampling Test/Validation Split Time Series Missing Value Imputation and more… K-Means Support Vector Machines Logistic, Linear, Ridge Regression Naïve Bayes Cross Validation and more… Model-level Stats ROC Tables Error Rate Lift Table Confusion Matrix R-Squared MSE XGBoost Filtering Feature Selection Correlation Matrices Table-Like Management Versioning Authorization and more… Random Forests and more… Principal Component Analysis PMML Import/Export TensorFlow Import AutoML
- 15. Modern analytical databases analyze data in many formats – Semi-structured, streaming, text, complex, … data formats optimized for long-term storage Database format optimized for read/analyze performance Historical Recent Unified Analytics Analyze data where it sits. Web logs Sensor, IOT data Time series Click streams Purchase history Geospatial … Streaming CSV Cloud storage, Hadoop (HDFS), S3 on prem data formats optimized for streaming messaging ROS
- 16. How does in-database ML help?
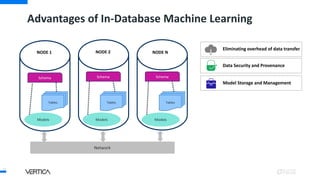
- 17. Advantages of In-Database Machine Learning 17 NODE 1 NODE 2 NODE N Schema Tables Models Schema Tables Models Schema Tables Models Network Eliminating overhead of data transfer
- 18. Advantages of In-Database Machine Learning 18 NODE 1 NODE 2 NODE N Schema Tables Models Schema Tables Models Schema Tables Models Network Eliminating overhead of data transfer Data Security and Provenance
- 19. Advantages of In-Database Machine Learning 19 NODE 1 NODE 2 NODE N Schema Tables Models Schema Tables Models Schema Tables Models Network Eliminating overhead of data transfer Data Security and Provenance Model Storage and Management
- 20. Advantages of In-Database Machine Learning 20 NODE 1 NODE 2 NODE N Schema Tables Models Schema Tables Models Schema Tables Models Network Eliminating overhead of data transfer Data Security and Provenance Model Storage and Management Serving concurrent users
- 21. Advantages of In-Database Machine Learning 21 NODE 1 NODE 2 NODE N Schema Tables Models Schema Tables Models Schema Tables Models Network Eliminating overhead of data transfer Data Security and Provenance Model Storage and Management Serving concurrent users Highly scalable ML functionalities
- 22. Advantages of In-Database Machine Learning 22 NODE 1 NODE 2 NODE N Schema Tables Models Schema Tables Models Schema Tables Models Network Eliminating overhead of data transfer Data Security and Provenance Model Storage and Management Serving concurrent users Highly scalable ML functionalities Avoiding maintenance cost of a separate system
- 23. Advantages of In-Database Machine Learning 23 NODE 1 NODE 2 NODE N Schema Tables Models Schema Tables Models Schema Tables Models Network Eliminating overhead of data transfer Data Security and Provenance Model Storage and Management Serving concurrent users Highly scalable ML functionalities Avoiding maintenance cost of a separate system Identical Dev, Prod environments
- 24. How does in-database ML work?
- 25. In-Database Random Forest A B C r1 r2 r3 NODE 1 1 NODE 2 2 NODE 3 3 2 A B C Tree1 r1 r2 A B C Tree2 r1 r3 A B C Tree3 r2 r3 3 Tree1 Tree2 Tree3 A B C r1 r3 A B C r2 r3 A B C r1 r2 TRAIN TRAIN TRAIN MERGE TABLE SPLIT DISTRIBUTE 1
- 26. In-Database Extreme Gradient Boosting A COMPUTE SUMMARY STATISTICS NODE 1 1 B COMPUTE SUMMARY STATISTICS NODE 2 2 C COMPUTE SUMMARY STATISTICS NODE 3 3 NODE 1 1 NODE 2 2 NODE 3 3 A B C FIND BEST SPLIT A B C FIND BEST SPLIT A B C FIND BEST SPLIT 1 2 ... ? Tree1 TreeN 3 ITERATIVE PROCESS TRAIN EXPORT SQL + memModel BINARY 4 JSON
- 27. SARIMA In-Database SARIMA X Y 0 s+2 s+4 s+6 s+8 s+10 s+12 V 2V 3V trend seasonality AR MA ARIMA value prediction confidence interval 1 2 3 4 seasonal decomposition NODE 1 NODE N X Xt Xt-1 Xt-2 𝜃𝜃𝑖𝑖 0 ≤ 𝑖𝑖 ≤ 𝑘𝑘𝑘 X Xt Xt-1 Xt-2 𝛼𝛼𝑗𝑗 0 ≤ 𝑗𝑗 ≤ 𝑘𝑘𝑘 𝜃𝜃𝑖𝑖 𝑘𝑘𝑘 ≤ 𝑖𝑖 ≤ 𝑞𝑞 𝛼𝛼𝑗𝑗 𝑘𝑘𝑘 ≤ 𝑗𝑗 ≤ 𝑝𝑝 COMPUTE COMPUTE A Simple Noniterative Estimator for Moving Average Models John W. Galbraith & Victoria Zinde-Walsh
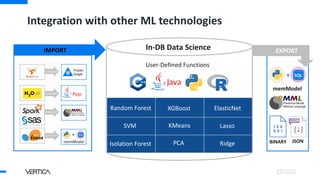
- 28. Integration with other ML technologies Geospatial Event Series Time series Text Analytics Pattern Matching Regression User-Defined Functions Machine Learning In-DB Data Science Pojo Frozen Graph SQL + memModel EXPORT EXPORT EXPORT EXPORT IMPORT SQL + memModel BINARY EXPORT XGBoost Random Forest ElasticNet Lasso Ridge KMeans Isolation Forest SVM JSON PCA
- 30. Q&A VerticaPy: https://vertica.com/python Paige Roberts Open Source Relations Manager E: Paige.Roberts@microfocus.com Try: https://www.vertica.com/try
- 31. Thank You
- 32. Previously, we used Apache Spark. Using Apache Spark cost 80% of the time from data I/O, only 20% of the time on machine learning. Now, we switched to using Vertica in-database machine learning and saved 80-90% data reading time. So, it’s had huge benefits in saving time and costs for model training. Xiaobo Ge, CTO, EOITek 32
- 33. Using Vertica’s User-Defined Extension, we have already built a bespoke lowpass filter to run against our data – that ensures top analytical performance without having to move the data to other systems or tools. Vertica analytics and machine learning ultimately delivers an edge that leads to more points, podiums, and wins for Jaguar Racing. Phil Charles 33 Technical Manager Jaguar Formula E racing team
- 34. What People Are Saying 34 “Vertica is the path to production for machine learning.” “With Vertica in Eon Mode’s sub-clustering ability, we can also give more computation power to our users as needed. This is really helpful for our machine learning analysts.” “We’re using machine learning and deep learning, technologies, in the cloud, to consume, that data, leveraging things like Python and TensorFlow to build out and then operationalize those predictive models ...” “Vertica is a key technology, bringing in those diverse, data sets and building flexible, data models, and being able to do it quickly and at scale …” “If we have a particular use case, we can easily write our own functions in any language – Java, Python, R – and deploy this in Vertica, harnessing the power of parallel computing.” “Others are forced to sample. This is about using all of your data which is fantastic.”
- 35. Analyze Data In Many Formats – Semi-structured, streaming, text, complex, … data formats optimized for long-term storage data format optimized for read/analyze performance Historical Recent Unified Analytics Analyze data where it sits. Web logs Sensor, IOT data Time series Click streams Purchase history Geospatial … Streaming CSV Cloud storage, Hadoop (HDFS), S3 on prem data formats optimized for streaming messaging ROS
- 36. Distributed databases automatically parallelize algorithm training Deliver accurate predictive analytics at speed and scale MPP architecture is a great fit – ML functions run in parallel across hundreds of nodes in a Vertica cluster Tree1 Tree2 Node1 Tree3 Tree4 Tree2n-1 Tree2n Node2 Noden
- 37. High Performance + High Concurrency 37 Get data quickly enough to act upon it, explore your data interactively, and enable everyone to make their own data-driven decisions Enable everyone to make their own data-driven decisions. Get data quickly enough to act on it. Explore data interactively. Scale Data Volumes Scale Users and Jobs SQL Database + + Analytics & ML Query Engine
- 38. Vertica ML is fast and scalable • Leverages MPP infrastructure and scale-out architecture for parallel high performance • No data movement across the system • No need to downsample, so accuracy is boosted Manage resources for many users or jobs Use a familiar interface • Manage, train, and deploy ML models using simple SQL calls • Integrate ML functions with other tools via SQL • Or use Jupyter and Python for familiar data science Proven infrastructure • No additional hardware and software to manage • Open integration with other solutions • Requires fewer people to setup and maintain • Resource isolation for multiple user sessions • Natural segmentation of user environments and privileges • Configurable memory usage for ML functions In-Database Machine Learning Advantages Enterprise-Grade Scalability Concurrency Productivity
- 39. VerticaPy – Python API for Machine Learning at Scale 28 Benefits: Jupyter/Python – popular interactive tool of choice Graphs and visualizations – even on large data sets Data stays in database – security, integrity Distributed Engine - heavy computation done by optimized MPP engine Open source – you can contribute! Manage models – store in DB Results where they’re needed – available in DB for other analyses, visualization, or driving applications and AI
- 40. VerticaPy Python library Open source https://github.com/vertica/VerticaPy Pandas and Scikit Learn functionality Conduct data science projects in Vertica – high performance, high scale analytical database Takes advantage of built-in parallel analytics and machine learning You write Python in a Jupyter Notebook, the database executes it on the full data set Uses vertica-python native Python client for Vertica created by Uber with contributions from Twitter, Palantir, Etsy, Kayak, Gooddata, … - https://github.com/vertica/vertica-python 40
- 41. Bruce Yen, WW Business Intelligence Leader “Our Vertica platform is instrumental in many areas of our business—creating predictive algorithms, serving up product recommendations, powering insight to our mobile apps, and generating daily reports and ad- hoc queries. It’s crucial for enabling us to be more agile with data.”
- 42. Challenge - Analyze large volumes of endpoint data to detect indications of cyber attacks Result - Provides near real-time data insertion across hundreds of thousands of endpoints; results in enterprise-grade threat detection quality - Ensures rapid querying, essential for analysts to outpace attackers - Delivers higher detection rates and dramatically reduces false positives - Enables analysts to perform complex queries over large volumes of data; presents results in easy-to-understand interface - Provides credible, robust, and scalable big data technology that will be trusted by its customers Cyberbit Surpasses Conventional Security Systems Vertica uses big data, behavioral analysis, and machine learning to optimize detection and response
- 43. Our Vertica platform is instrumental in many areas of our business—creating predictive algorithms, serving up product recommendations, powering insight to our mobile apps, and generating daily reports and ad- hoc queries. It’s crucial for enabling us to be more agile with data. Bruce Yen 43 WW Business Intelligence Leader Guess
- 44. Advantages of Python + MPP Analytical Database MPP Scale Clusters with no name node or other single point of failure allow unlimited scale Speed and Concurrency Query optimization and resource management across multiple nodes Features ML algorithm parallelization, moving windows, geospatial analysis, time series joins, fast data prep... Open Architecture Integration with many other applications - BI, ETL, Kafka, Spark, Data Science Labs … Broad Utility Many functionalities - one of the most broadly useful programming languages. Flexibility It Many right paths to do things, a lot of freedom, works on many platforms. Ease of Use High level of abstraction makes Python one of the easiest programming languages. Strong Community Most data scientists master Python. Many useful packages (pandas, scikit, …)
- 45. Linear regression Analytic database functions include machine learning algorithms K-means Logistic regression Naive Bayes Random Forest SVM Predict customer retention Forecast sales revenues Customer segmentation Predict sensor failure Classify gene expression data for drug discovery Refine keywords to improve Click Through Rate (CTR)
- 46. 20 Bring your R, TensorFlow, and Python code inside the database – analyze the data in place.
- 47. Online Examples
- 48. Predictive Maintenance Demo 48 Analyze sensor data from cooling towers across the US , enabling equipment manufacturers to predict and prevent equipment failure
- 49. Flight Tracker Demo 49 Vertica operates at the “edge” with flight track detail. Sensor data is collected using a Raspberry pi with radio receiver and antenna. Data is loaded into Vertica as thousands of records per second and builds to billions of flight data points collected within a 250-mile radius. https://www.vertica.com/blog/blog-post-series-using-vertica-track- commercial-aircraft-near-real-time/
- 51. Huge improvements in stability and performance after moving to Vertica 24 mins on Spark, 3 mins in Vertica Can incorporate other data like weather to optimize predictive thermostat efficiency after moving to Vertica ML Citing speed of analytics, ease of use when coding in SQL, and improvements in the accuracy of models after moving workloads to Vertica ML Solving issues that were previously unsolvable Minimal hardware, software, and personnel investments when differentiating with data science. 51
- 52. Moving data science workloads from Spark on Hadoop to in-database Improvements in stability and performance Creating customer segmentation via clustering algorithms on a 15 million customer dataset took 24 mins on Spark - 3 mins in database Concurrently running other algorithms without performance impact Cardlytics partners with more than 1,500 financial institutions to run their online and mobile banking rewards programs, which gives us a robust view into where and when consumers are spending their money.
- 53. Fidelis Cybersecurity protects the world's most sensitive data by identifying and removing attackers no matter where they're hiding on your network and endpoints. 53 Data science team was experiencing challenges with performance while using Spark ML Moving workloads from Spark ML to in-database ML provided: Speed of analytics Ease of use when coding in SQL Increased accuracy of models
- 54. Some Vertica IoT Customer Resources Case Studies Anritsu ROI case study: https://www.vertica.com/wp- content/uploads/2017/01/r24-HPE-Vertica-ROI-case-study-Anritsu.pdf Infographic of ROI: https://www.vertica.com/wp- content/uploads/2017/03/Anritsu-v2.pdf Nimble Storage ROI case study: https://www.vertica.com/wp- content/uploads/2017/08/Nimble-Storage-ROI.pdf Optimal+ case study: https://www.vertica.com/wp- content/uploads/2017/06/Optimal-MF-rebrand-FINAL-lo-res.pdf *Climate Corp case study: https://www.vertica.com/wp- content/uploads/2019/01/Climate-Corp_Success-Story-FINAL.pdf Webcasts – Data Disruptors Philips: https://www.brighttalk.com/webcast/10477/277693 Climate Corp: https://www.brighttalk.com/webcast/8913/336201 Nimble Storage (HPE InfoBright): https://www.brighttalk.com/webcast/8913/330769 Zebrium: https://www.brighttalk.com/webcast/8913/332838 Simpli.fi: https://www.brighttalk.com/webcast/8913/354325/simpli-fi- delivers-advertising-insights-on-billions-of-streaming-bid-messages Videos Optimal+: https://www.youtube.com/watch?v=IZkkoy5ZT1M&feature=youtu.be Anritsu: https://www.youtube.com/watch?v=QZ5vWqblVXU&feature=youtu.be 54