











































Predicting Flights with Azure Databricks
- 1. Predicting Flights with Azure Databricks Presented by Sarah Dutkiewicz Microsoft MVP, Developer Technologies Cleveland Tech Consulting, LLC
- 2. Microsoft Cloud Workshops (MCWs) • Great way to see how Azure services work together in end-to-end scenarios • This presentation is based on content for the Big Data Analysis and Visualization MCW. • Learn more at: Microsoft Cloud Workshop
- 3. Agenda • What is Databricks? • Introducing the flight prediction scenario • Exploring Databricks while getting to the solution
- 4. Scenario • Margie’s Travels – a concierge for business travelers - wants to enable their agents to enter in the flight information and produce a prediction as to whether the departing flight will encounter a 15- minute or longer delay, considering the weather forecast for the departure hour. • Data details: • Sample data from 2013 • 2.7 million flight delays with airport codes - examples • 20 columns – features
- 5. Training the model • Using Decision Tree algorithm (binary classification) from Spark MLlib • Part of the historical data (2013) is used for training and another part for test • Flights are delayed have DepDel15 value of 1 • Sample keeps all delayed and a downsample of 30% not delayed – stratified sampling • One-Hot encoded categorical variables and use the Pipeline API • 3-fold CrossValidator • Save the model for use in other notebooks and saved in case cluster restarts
- 6. What is Databricks? • Web-based analytics platform with 3 environments: • Databricks SQL – for querying data lakes with SQL • Databricks Data Science & Engineering – for data engineers, data scientists, and ML engineers for data ingestion and analysis using the Apache Spark Ecosystem • Databricks Machine Learning – experiment tracking, model training, feature development and management
- 8. Databricks SQL • Query data lake using SQL • Create visualizations as part of queries • Build and share dashboards using visualizations
- 9. SQL Endpoint • Starter Endpoint created by default • Additional endpoints can be created
- 11. Databricks SQL Components flow
- 12. Data Source: Data Lake • Using Azure Storage • CSVs will get migrated from an on-premises environment to Azure Storage using Azure Data Factory
- 13. Azure Data Factory • Azure Data Factory can migrate data from on- premises to Azure Storage. • Once migrated, we can run a Databricks notebook to score the data.
- 14. Loading the Data into Azure Databricks • Done in the Data Science and Engineering load • Uses a cluster for loading data into Azure Databricks • Tables have 2 different types: • Global tables - accessible across all clusters • Local tables - available only within one cluster
- 15. Creating a Table
- 16. Working with Queries in Azure Databricks
- 17. Query in SQL Editor • Schema Browser to help show tables and columns • Past Executions for metrics of past performance • Query tabs • Results / Visualizations • Table is by default • Create additional visualizations here
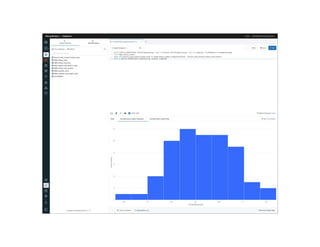
- 21. Dashboard
- 22. Dashboard • Visualizations need to be created with queries first • Lay out multiple visualizations • Filter details – filters also come from queries
- 23. Alerts
- 24. Databricks Data Science & Engineering Classic Databricks
- 25. Databricks Data Science & Engineering • Classic Databricks environment • Backbone for the ML environment • Key components: • Workspaces • Runtimes • Clusters • Notebooks • Jobs
- 26. Workspaces • Environment for all Azure Databricks assets • Organizes notebooks, libraries, and experiments into folders • Notebooks – runnable code + markdown • Libraries – third party resources or locally built code accessible to clusters • Experiments – MLflow machine learning model activities • Provides access to clusters and jobs • Integrates with Git through Repos
- 27. Clusters • Powerhouse for Azure Databricks • Compute and configuration • Supports workloads for: • Data engineering • Data science • Data analytics • Takes time to start • Two types • All-purpose – can be shared for collaborative works; manually managed • Job clusters – used for jobs, created and terminated by the Azure Databricks job scheduler; cannot be restarted
- 29. Runtimes • Assigned at the cluster-level • Provides the engine for the platform, based on Apache Spark • Includes Delta Lake for storage • GPU-enabled support available • Ubuntu and system libraries • Supports the following languages: • Python • R • Java • Scala
- 30. Special Runtimes • Databricks Runtime for Machine Learning • Databricks Light • Photon-enabled runtimes • Uses a native vectorized query engine • Currently in Public Preview • Works in both Azure Databricks clusters and Databricks SQL endpoints
- 31. Notebooks • Can mix Markdown and languages to present data • Example: Data Preparation notebook with: • Markdown • SQL • Python • R
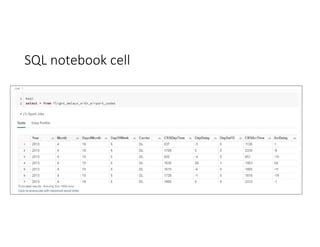
- 32. Notebook cells • Command number helps for execution and navigation • Execution details include: • Duration • User • Timestamp • Cluster name • Example shows Python command and output
- 34. Data munging • Using SparkR to clean • Yes… R in the same notebook as SQL… labeled as a Python notebook
- 35. Export to a Databricks table • Storing munged data into another table
- 36. Cleaning weather data with Python • Same notebook
- 37. DataFrame schema • dfFlightDelays is a DataFrame • Python code, using pretty print pprint library
- 38. Jobs • Used for running non-interactive code • ETL or ELT • Task orchestration • Tasks include: • JAR file (Java) • Azure Databricks notebook • Delta Live Tables pipeline • Application written in Scala, Java, or Python • Not included in this presentation’s demo
- 40. Databricks Machine Learning • Builds on top of Data Science & Engineering • Same workspace components • ML components: • Experiments • Feature Stores • Models
- 41. Experiments • In the 02 Train and Evaluate Models notebook, Cmd27 • Uses mlflow to trigger experiment via code • Experiments can show MLflow experiments across an organization that you have access to
- 42. Creating your own AutoML experiment • Select a compute cluster • ML Problem Type: • Classification • Regression • Forecasting – ML Runtimes 10.x and higher • Evaluation metric (advanced configuration): • Classification • F1 score • Accuracy • Log loss • Precision • ROC/AUC • Regression • R-squared • Mean absolute error • Mean squared error • Root mean squared error
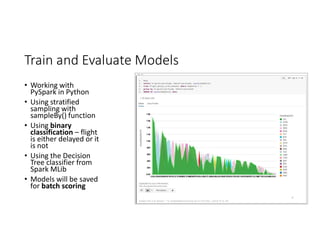
- 43. Train and Evaluate Models • Working with PySpark in Python • Using stratified sampling with sampleBy() function • Using binary classification – flight is either delayed or it is not • Using the Decision Tree classifier from Spark MLib • Models will be saved for batch scoring
- 44. Batch Scoring • Reads from Azure Data Storage • Creates DataFrames for the CSVs • Load the trained model • Make predictions against the set • Save the scored data in a global table scoredflights
- 45. Databricks as a Data Source
- 47. Summary data in Power BI
- 48. Looking at PHX’s track record
- 49. Source: Microsoft Cloud Workshop: Big Data Analytics and Visualization, Hands-on Lab
- 50. Additional Resources • User guides • Databricks SQL user guide - Azure Databricks - Databricks SQL | Microsoft Docs • Databricks Data Science & Engineering guide - Azure Databricks | Microsoft Docs • Databricks Machine Learning guide - Azure Databricks | Microsoft Docs • Microsoft Learn pathways • Build and operate machine learning solutions with Azure Databricks - Learn | Microsoft Docs • Data engineering with Azure Databricks - Learn | Microsoft Docs • Perform data science with Azure Databricks - Learn | Microsoft Docs