Embed, Encode, Attend, Predict – applying the 4 step NLP recipe for text classification and similarity
•Download as PPTX, PDF•
14 likes•3,916 views

The document discusses applying a 4-step recipe for natural language processing (NLP) tasks with deep learning: embed, encode, attend, predict. It presents examples applying this approach to document classification, document similarity, and sentence similarity. The embed step uses word embeddings, encode uses LSTMs to capture word order, attend reduces sequences to vectors using attention mechanisms, and predict outputs labels. The document compares different attention mechanisms and evaluates performance on NLP tasks.




















Embed, Encode, Attend, Predict – applying the 4 step NLP recipe for text classification and similarity
- 1. | Presented By Date July 6, 2017 Sujit Pal, Elsevier Labs Embed, Encode, Attend, Predict – applying the 4 step NLP recipe for text classification and similarity
- 4. | 4 AGENDA • NLP Pipelines before Deep Learning • Deconstructing the “Encode, Embed, Attend, Predict” pipeline. • Example #1: Document Classification • Example #2: Document Similarity • Example #3: Sentence Similarity
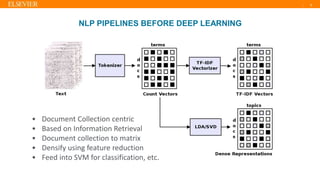
- 5. | 5 NLP PIPELINES BEFORE DEEP LEARNING • Document Collection centric • Based on Information Retrieval • Document collection to matrix • Densify using feature reduction • Feed into SVM for classification, etc.
- 6. | 6 NLP PIPELINES BEFORE DEEP LEARNING • Idea borrowed from Machine Learning (ML) • Represent categorical variables (words) as 1-hot vectors • Represent sentences as matrix of 1-hot word vectors • No distributional semantics at word level.
- 7. | 7 WORD EMBEDDINGS • Word2Vec – predict word from context (CBOW) or context from word (skip-gram) shown here. • Other embeddings – GloVe, FastText. • Pretrained models available • Encode word “meanings”.
- 8. | 8 STEP #1: EMBED • Converts from word ID to word vector • Change: replace 1-hot vectors with 3rd party embeddings. • Embeddings encode distributional semantics • Sentence represented as sequence of dense word vectors
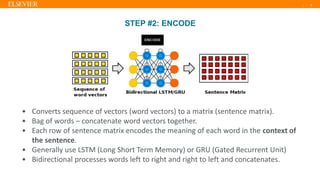
- 9. | 9 STEP #2: ENCODE • Converts sequence of vectors (word vectors) to a matrix (sentence matrix). • Bag of words – concatenate word vectors together. • Each row of sentence matrix encodes the meaning of each word in the context of the sentence. • Generally use LSTM (Long Short Term Memory) or GRU (Gated Recurrent Unit) • Bidirectional processes words left to right and right to left and concatenates.
- 10. | 10 STEP #3: ATTEND • Reduces matrix (sentence matrix) to a vector (sentence vector) • Non-attention mechanism –Sum or Average/Max Pooling • Attention tells what to keep during reduction to minimize information loss. • Different kinds – matrix, matrix + context (learned), matrix + vector (provided), matrix + matrix.
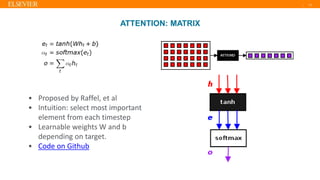
- 11. | 11 ATTENTION: MATRIX • Proposed by Raffel, et al • Intuition: select most important element from each timestep • Learnable weights W and b depending on target. • Code on Github
- 12. | 12 ATTENTION: MATRIX + VECTOR (LEARNED) • Proposed by Lin, et al • Intuition: select most important element from each timestep and weight with another learned vector u. • Code on Github
- 13. | 13 ATTENTION: MATRIX + VECTOR (PROVIDED) • Proposed by Cho, et al • Intuition: select most important element from each timestep and weight it with a learned multiple of a provided context vector • Code on Github
- 14. | 14 ATTENTION: MATRIX + MATRIX • Proposed by Parikh, et al • Intuition: build alignment (similarity) matrix by multiplying learned vectors from each matrix, compute context vectors from the alignment matrix, and mix with original signal. • Code on Github
- 15. | 15 STEP #4: PREDICT • Convert reduced vector to a label. • Generally uses shallow fully connected networks such as the one shown. • Can also be modified to have a regression head (return the probabilities from the softmax activation.
- 16. | 16 DOCUMENT CLASSIFICATION EXAMPLE – ITERATION #1 • 20 newsgroups dataset • 40k training records • 10k test records • 20 classes • Embed, Predict • Bag of Words idea • Sentence = bag of words • Document = bag of sentences • Code on Github
- 17. | 17 DOCUMENT CLASSIFICATION EXAMPLE – ITERATION #2 • Embed, Encode, Predict • Hierarchical Encoding • Sentence Encoder: converts sequence of word vectors to sentence vector. • Document Encoder: converts sequence of sentence vectors to document vector. • Sentence encoder Network embedded inside Document network. • Code on Github
- 18. | 18 DOCUMENT CLASSIFICATION EXAMPLE – ITERATION #3 (a, b, c) • Embed, Encode, Attend, Predict • Encode step returns matrix, vector for each time step. • Attend reduces matrix to vector. • 3 types of attention (all except Matrix Matrix) applied to different versions of model. • Code on Github – (a), (b), (c)
- 19. | 19 DOCUMENT CLASSIFICATION EXAMPLE – RESULTS
- 20. | 20 DOCUMENT SIMILARITY EXAMPLE • Data derived from 20 newsgroups • Hierarchical Model (Word to Sentence and sentence to document) • Tried w/o Attention, Attention for sentence encoding, and attention for both sentence encoding and document compare • Code in Github – (a), (b), (c)
- 21. | 21 SENTENCE SIMILARITY EXAMPLE • 2012 Semantic Similarity Task dataset. • Hierarchical Model (Word to Sentence and sentence to document). • Used Matrix Matrix Attention for comparison • Code in Github – without attention, with attention
- 22. | 22 SUMMARY • 4-step recipe is a principled approach to NLP with Deep Learning • Embed step leverages availability of many pre-trained embeddings. • Encode step generally uses Bidirectional LSTM to create position sensitive features, possible to use CNN here also. • Attention of 3 main types – matrix to vector, with or without implicit context, matrix and vector to vector, and matrix and matrix to vector. Computes summary with respect to input or context if provided. • Predict step converts vector to probability distribution via softmax, usually with a Fully Connected (Dense) network. • Interesting pipelines can be composed using complete or partial subsequences of the 4 step recipe.
- 23. | 23 REFERENCES • Honnibal, M. (2016, November 10). Embed, encode, attend, predict: The new deep learning formula for state-of-the-art NLP models. • Liao, R. (2016, December 26). Text Classification, Part 3 – Hierarchical attention network. • Leonardblier, P. (2016, January 20). Attention Mechanism • Raffel, C., & Ellis, D. P. (2015). Feed-forward networks with attention can solve some long-term memory problems. arXiv preprint arXiv:1512.08756. • Yang, Z., et al. (2016). Hierarchical attention networks for document classification. In Proceedings of NAACL-HLT (pp. 1480-1489). • Cho, K., et al. (2015). Describing multimedia content using attention-based encoder-decoder networks. IEEE Transactions on Multimedia, 17(11), 1875-1886. • Parikh, A. P., et al. (2016). A decomposable attention model for natural language inference. arXiv preprint arXiv:1606.01933.
- 24. | 24 THANK YOU • Code: https://github.com/sujitpal/eeap-examples • Slides: https://www.slideshare.net/sujitpal/presentation-slides-77511261 • Email: sujit.pal@elsevier.com • Twitter: @palsujit 50% off on EBook Discount Code EBDEEP50 Valid till Oct 31 2017