









Recurrent neural networks rnn
- 1. Deep Learning – (RNN) Recurrent Neural Networks
- 2. Content • Architecture for an RNN • Forward propagation • Back propagation • Long Short Term Memory Networks LSTM
- 3. Motivation: what about sequence prediction? What can I do when input size and output size vary?
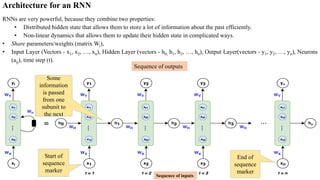
- 4. Architecture for an RNN RNNs are very powerful, because they combine two properties: • Distributed hidden state that allows them to store a lot of information about the past efficiently. • Non-linear dynamics that allows them to update their hidden state in complicated ways. • Share parameters/weights (matrix Wi), • Input Layer (Vectors - x1, x2, …, xn), Hidden Layer (vectors - h0, h1, h2, …, hn), Output Layer(vectors - y1, y2, …, yn), Neurons (aij), time step (t). Some information is passed from one subunit to the next Start of sequence marker End of sequence marker Sequence of outputs Sequence of inputs
- 5. Architecture for an RNN • The recurrent net is a layered net with shared weights and then train the feed- forward net with weight constraints. Training algorithm is working in the time domain: 1. Forward propagation: Compute predictions • The forward pass builds up a stack of the activities of all the units at each time step. • The input vector xᵢ to each hidden state where i=1, 2,…, n for each element in the input sequence. • The input text must be encoded into numerical values. E.g. every letter in the word “dogs” is one-hot encoded vector with dimension (4x1). Similarly, x can also be word embedding or other numerical representations. • Hidden state output vector after the activation function from previous state is applied to the next state of hidden nodes. • At time t, the architecture uses for h vector hidden vector from the previous state and the input x at time t-1. i.e. takes information from previous inputs that are sequentially behind the current input. • But, the h0 vector will always start as a vector of 0’s because the algorithm has no information preceding the first element in the sequence. 2 1 2 1 2 1 2 1 2 1 : : : w and w for w E w E use w E and w E compute w w need we w w constrain To + = = Back propagation Sharing weights
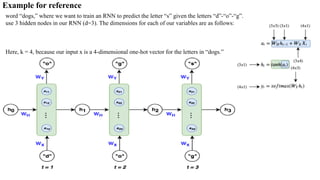
- 6. Example for reference word “dogs,” where we want to train an RNN to predict the letter “s” given the letters “d”-“o”-“g”. use 3 hidden nodes in our RNN (d=3). The dimensions for each of our variables are as follows: Here, k = 4, because our input x is a 4-dimensional one-hot vector for the letters in “dogs.”
- 7. Architecture for an RNN • Activation function: tanh at hidden layers, softmax at output layer 2. Compute the loss using cross entropy: 3. Back propagation: compute the gradient (error derivatives) at each time step. • Update the weights to minimize the loss: For hidden state at t=2, input is the output from t-1 and x at t
- 8. Applications of Recurrent Neural Networks (RNNs) 1. Prediction problems 2. Language Modelling and Generating Text 3. Machine Translation 4. Speech Recognition 5. Generating Image Descriptions 6. Video Tagging 7. Text Summarization 8. Call Center Analysis 9. Face detection, OCR Applications as Image Recognition 10. Other applications like Music composition
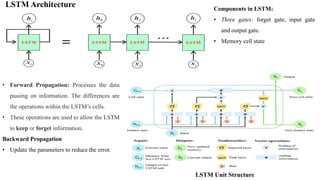
- 9. Long Short Term Memory Networks (LSTMs) • LSTMs are a type of recurrent neural network (RNN) that can learn and memorize long-term dependencies. • LSTMs retain past information for long period of time. Hence, It is very useful in time-series prediction. • LSTMs have a chain-like structure where four (memory cell, forget, input, output) interacting layers communicate in a unique way. • LSTM has three gates (forget, input, output) to protect and control the cell state. LSTMs Working principle: • First, they forget irrelevant information of the previous state or keep the relevant information of the previous state. • Next, they selectively update the memory cell-state values. • The memory cell state carry relevant information from the earlier time steps to later time steps throughout the processing of the sequence that reducing the effects of short-term memory. • As the cell state goes on its journey, information get’s added or removed to the cell state via gates. • The gates are different neural networks that decide which information is allowed on the cell state. The gates can learn what information is relevant to keep or forget during training. • Finally, provides the output of certain parts of the cell state.
- 10. LSTM Architecture LSTM Unit Structure Components in LSTM: • Three gates: forget gate, input gate and output gate. • Memory cell state • Forward Propagation: Processes the data passing on information. The differences are the operations within the LSTM’s cells. • These operations are used to allow the LSTM to keep or forget information. Backward Propagation • Update the parameters to reduce the error.
- 11. LSTM layers working principle • Gates are composed with a sigmoid neural net layer and a pointwise multiplication operation. • The sigmoid layer output range is between zero and one that describe how much of each component pass/remove information. A value of zero means “no information allows,” while a value of one means “pass everything”. Forget gate layer: • Decides what information going to throw away from the memory cell state. • 1 represents “completely keep this” while a 0 represents “completely reject this.” Input gate layer: • The next step is to decide what new information we’re going to store in the cell state. • This has two parts. First, a sigmoid layer called the “input gate layer” decides which values we’ll update. • Next, a tanh layer creates a vector of new candidate values, Ct, that could be added to the state. • In the next step, we’ll combine these two to create an update to the state. Memory Cell State: • Update the old cell state, Ct-1, into the new cell state Ct. • Multiply the old state by ft, forgetting the things we decided to forget earlier. • Then we add it ∗ Ct. This is the new candidate values, scaled by how much we decided to update each state value. Output gate layer: • Decides output based on cell state, but will be a filtered version. • First, run a sigmoid layer which decides what parts of the cell state to be output. • Then, we put the cell state through tanh (to push the values to be between −1 and 1) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to.
- 12. Types of LSTM models based on input and output • One input to One output - eg : Giving labels to image • One input to many outputs- eg : Giving description/caption to image (description will have sequence of words - many output) • Many inputs to one output - eg : Predicting the next word in given incomplete statement • Many inputs to Many outputs- eg : Stock market prediction for following days based on past data
- 13. Applications of LSTM 1. Speech Recognition (Input is audio and output is text) - Google Assistant, Microsoft Cortana, Apple Siri 2. Machine Translation (Input is text and output is also text) - Google Translate 3. Image Captioning (Input is image and output is text) 4. Sentiment Analysis (Input is text and output is rating) 5. Music Generation/Synthesis ( input music notes and output is music) 6. Video Activity Recognition (input is video and output is type of activity)