







































Redesigning the Netflix API - OSCON
- 1. The Netflix APIThe History and Future of the Netflix API Daniel Jacobson
- 2. Netflix OverviewNetflix offers subscriptions to unlimited streaming movies and TV shows for a very low priceAbout 700 operational employees, 300 engineersMore than 25 million subscribers in US and CanadaGoing global, starting with 43 countries in Latin America later this yearMarket capitalization is about $15BResponsible for more than 30% of US bandwidth during peak hours, by some accounts
- 3. Netflix API OverviewLaunched three years agoServices public developersAbout 20K developersAlmost 13K registered applicationsServices catalog discovery for hundreds of Netflix-branded devicesHandles more than 1B requests per dayPeak traffic about 20K requests per second
- 4. Original Charter for the Netflix APIExpose Netflix metadata and services to the public developer community to “let 1,000 flowers bloom”. That community will build rich and exciting new tools and services to improve the value of Netflix to our customers.
- 5. Netflix API
- 9. Netflix API
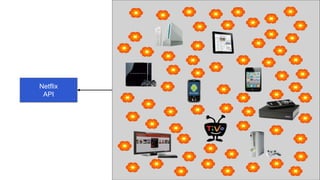
- 10. Some of the hundreds of Netflix devices
- 11. Growth of Netflix API Requests
- 12. So, why redesign the API if it is so successful?
- 13. Morphed Public API to Internal APILaunch of APIToday… And implemented hundreds of devices
- 14. Focusing Business and API on StreamingLaunch of APIToday
- 15. Migrated from Data Centers to CloudLaunch of APIToday
- 16. Becoming an International Streaming CompanyLaunch of APIToday
- 17. Many fundamental business changesNo fundamental changes to the API
- 18. Netflix API Requests by Audience
- 19. Netflix API
- 20. Future Architecture needs to support key audience first with a trickle down of features to the public audienceNetflix API
- 21. The Goal
- 22. Over 30 Billion requests per month(Peaks at about 20,000 requests per second)
- 25. {"catalog_title":{"id":"http://api.netflix.com/catalog/titles/movies/60034967","title":{"title_short":"Rosencrantz and Guildenstern Are Dead","regular":"Rosencrantz and Guildenstern Are Dead"},"maturity_level":60,"release_year":"1990","average_rating":3.7,"box_art":{"284pix_w":"http://cdn-7.nflximg.com/en_US/boxshots/ghd/60034967.jpg","110pix_w":"http://cdn-7.nflximg.com/en_US/boxshots/large/60034967.jpg","38pix_w":"http://cdn-7.nflximg.com/en_US/boxshots/tiny/60034967.jpg","64pix_w":"http://cdn-7.nflximg.com/en_US/boxshots/small/60034967.jpg","150pix_w":"http://cdn-7.nflximg.com/en_US/boxshots/150/60034967.jpg","88pix_w":"http://cdn-7.nflximg.com/en_US/boxshots/88/60034967.jpg","124pix_w":"http://cdn-7.nflximg.com/en_US/boxshots/124/60034967.jpg"},"language":"en","web_page":"http://www.netflix.com/Movie/Rosencrantz_and_Guildenstern_Are_Dead/60034967","tiny_url":"http://movi.es/ApUP9"},"meta":{"expand":["@directors","@bonus_materials","@cast","@awards","@short_synopsis","@synopsis","@box_art","@screen_formats","@"links":{"id":"http://api.netflix.com/catalog/titles/movies/60034967","languages_and_audio":"http://api.netflix.com/catalog/titles/movies/60034967/languages_and_audio","title":"http://api.netflix.com/catalog/titles/movies/60034967/title","screen_formats":"http://api.netflix.com/catalog/titles/movies/60034967/screen_formats","cast":"http://api.netflix.com/catalog/titles/movies/60034967/cast","awards":"http://api.netflix.com/catalog/titles/movies/60034967/awards","short_synopsis":"http://api.netflix.com/catalog/titles/movies/60034967/short_synopsis","box_art":"http://api.netflix.com/catalog/titles/movies/60034967/box_art","synopsis":"http://api.netflix.com/catalog/titles/movies/60034967/synopsis","directors":"http://api.netflix.com/catalog/titles/movies/60034967/directors","similars":"http://api.netflix.com/catalog/titles/movies/60034967/similars","format_availability":"http://api.netflix.com/catalog/titles/movies/60034967/format_availability"}}}<catalog_titles> <number_of_results>1140</number_of_results> <start_index>0</start_index> <results_per_page>10</results_per_page> <catalog_title> <id>http://api.netflix.com/catalog/titles/movies/60021896</id><title short="Star" regular="Star"></title> <box_art small="http://alien2.netflix.com/us/boxshots/tiny/60021896.jpg" medium="http://alien2.netflix.com/us/boxshots/small/60021896.jpg" large="http://alien2.netflix.com/us/boxshots/large/60021896.jpg"></box_art> <link href="http://api.netflix.com/catalog/titles/movies/60021896/synopsis" rel="http://schemas.netflix.com/catalog/titles/synopsis" title="synopsis"></link> <release_year>2001</release_year> <category scheme="http://api.netflix.com/catalog/titles/mpaa_ratings" label="NR"></category> <category scheme="http://api.netflix.com/categorieSo, the 1,000 flowers, who previously accounted for 100% of the total API traffic, now…s/genres" label="Foreign"></category> <link href="http://api.netflix.com/catalog/titles/movies/60021896/cast" rel="http://schemas.netflix.com/catalog/people.cast" title="cast"></link><link href="http://api.netflix.com/catalog/titles/movies/60021896/screen_formats" rel="http://schemas.netflix.com/catalog/titles/screen_formats" title="screen formats"></link <link href="http://api.netflix.com/catalog/titles/movies/60021896/languages_and_audio" rel="http://schemas.netflix.com/catalog/titles/languages_and_audio" title="languages and audio"></link> <average_rating>1.9</average_rating> <link href="http://api.netflix.com/catalog/titles/movies/60021896/similars" rel="http://schemas.netflix.com/catalog/titles.similars" title="similars"></link> <link href="http://www.netflix.com/Movie/Star/60021896" rel="alternate" title="webpage"></link> </catalog_title></catalog_titles>
- 26. Could it have been 5 billion requests per month? Or less?(Assuming everything else remained the same)
- 27. The Challenge
- 28. Some of the many Netflix-ready devices
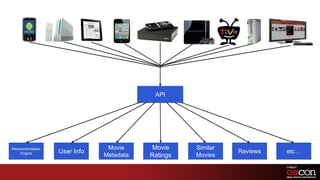
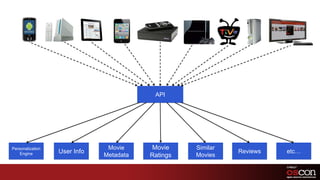
- 29. APIRecommendation EngineUser InfoMovie MetadataMovie RatingsSimilar MoviesReviewsetc…
- 30. The Problem with This ApproachThis device:Is different than this device:
- 31. The Problem with This ApproachAnd this UI:Is different than this UI:
- 32. Some of the many Netflix-ready devices
- 33. Products and Features Vary from Device to DeviceAspect RatiosConnection SpeedsSecurity ConcernsScreen Real EstateUser ExpectationsUser Interaction ModelsTouchscreensRemote controlsGame controllersVoice commands
- 34. Some Unique Requests of API Across User InterfacesOutput Format ExpectationsProprietary XML markupFlattened JSON object modelHierarchical JSON object modelsHardware ConstraintsSignificant memory constraintsMetadata Delivery NeedsDifferent fields required for different UIsSome UIs are easier to build/maintain if they stream the bits on delivery
- 35. Conclusion:Most REST APIs are designed to generically accommodate the needs of a large number of clientsbut they are optimized for none
- 36. New Charter for the Netflix APIBuild and maintain an infinitely scalable data distribution pipeline for getting metadata and services from internal Netflix systems to streaming client apps on all platforms in the format and/or delivery method that is most optimal for each app and platform.
- 37. So, What Does This Look Like?
- 38. APIPersonalization EngineUser InfoMovie MetadataMovie RatingsSimilar MoviesReviewsetc…
- 39. APIPersonalization EngineUser InfoMovie MetadataMovie RatingsSimilar MoviesReviewsetc…
- 40. Wrappers Manipulate Metadata for Each Title ReturnedGenerates List of IDs and Returns All Metadata for EachCLIENT APPREQUEST WRAPPERREQUEST WRAPPERHANDLERREQUEST WRAPPERREQUEST WRAPPERSerialized MetadataObjectDEFAULTRESPONSEWRAPPERAPI ENGINEContract Data ModelCUSTOM RESPONSEWRAPPERRESPONSE WRAPPERHANDLERDEPENDENCIESDependency Management to Populate Metdata ObjectCUSTOM RESPONSEWRAPPERREQUEST RESPONSE HANDLERCUSTOM RESPONSEWRAPPERDEDICATED LOCATION ON APIFOR CLIENTSAPI SERVERSCLIENT APPS
- 42. Key Ideas for the API RedesignCustom endpoints for appropriate screens on appropriate devicesBrings complexity to the serverLimits network transactions costsLimits byte size on payloadGive power of custom endpoints to device development teamsAllows them to be more nimbleMinimizes (or removes?) versioning needs at the formatting levelMaintain native API for generic requestsShould handle majority of distinct queries, but minority of requestsAlso to be exposed to public developersIsolate tiers of system and technology based on jobFormatting tier may be in lighter-weight language (like Scala, Grails, etc.)
- 43. Benefits with This ApproachIsolationProblems with a formatting script are isolated to that UIRapid DevelopmentUI teams can get a lot of what they want without waiting for API teamChanges to scripts don’t require full API pipeline deploymentsVersioningBecause the scripts are very targeted, we may not need to version that output
- 44. Challenges with This ApproachIncreased variability in request profilesMore testingMore risk of problemsMaintenance challengesFormatter script repository could grow largeHarder to triage issues Duplicative workUI teams could do redundant work in their scripts
- 45. Questions?
Editor's Notes
- This is my paraphrase of what the original intent of the Netflix API was.
- A visual representation of the original charter
- The result of the 1,000 flowers model is a wide range of apps and sites built by third-party developers. These are some examples of them.
- Extending our community engagement was the Netflix Prize, which exposed a fixed dataset to registered teams who would work to improve the Netflix recommendations algorithm by 10%. The winning team would receive $1M. There were several thousand teams that participated in the prize, which lasted about three years.
- Then streaming started taking off for Netflix, first on the desktop and then on devices.
- As we broadened the device support, we leveraged the Netflix API to deliver the content. The 1,000 flowers were then sharing the API with internal and external development teams who produce Netflix-branded streaming apps.
- Over time, streaming really took off and now streaming is supported on hundreds of Netflix-ready devices.
- The explosion in streaming usage has resulted in tremendous growth in the Netflix API. In the last 12 months alone, the API traffic has gone up 12x, from about 2.5M requests per month to about 31M.
- As streaming took off, the API continued to morph to support the needs of streaming on hundreds of devices.
- Moreover, when the API launched, Netflix users were consuming substantially more DVDs. Over time, the focus of the company has shifted more towards streaming.
- Meanwhile, major architectural challenges have been undertaken, such as moving the entire streaming operation from data centers to the AWS cloud.
- Finally, when the API initially launched, we were a US-only service. Now we are in Canada and have announced expansion to 43 countries in Latin America for later this year.
- There have been many incremental changes to the API, but none fundamental in the way that match the growth of the business.
- So, the 1,000 flowers, who previously accounted for 100% of the total API traffic, now account for < .3% of the total API traffic.
- Currently, the API is still based on the design that was targeted towards the public third-party developers with the streaming devices running off the same design.
- What we would like to get to is redesigning the API to be targeted towards the key audience (the Netflix-branded streaming devices) and then trickle down the features to the third-party developers.
- Metrics like 30+B requests per month sound great, don’t they? The reality is that this number is concerning…
- In the web world, increasing request numbers mean increasing opportunity of ad impressions, which means increasing opportunity for generating revenue. And when you hit certain thresholds in impressions, CPMs start to rise, which means even more money. That is why some media companies have stories spanning multiple pages, etc.
- And some companies, like The New York Times, create more opportunity for ad impressions by article pagination.
- But for systems that yield output that looks like these documents, such as APIs, ad impressions are not part of the game. As a result, the increase in requests don’t translate into more revenue. In fact, they translate into more expenses. That is, to handle more requests requires more servers, more systems-admins, a potentially different application architecture, etc.
- We are challenging ourselves to redesign the API to see if those same 30+ billion requests could have been 5 billion or perhaps even less. Through more targeted API designs based on what we have learned through our metrics, we will be able to reduce our API traffic as Netflix’ overall traffic grows. Reduction in traffic results in lower server counts (and costs), fewer demands on systems infrastructure engineers, etc. More importantly, if rendering a single page on a UI can be done in 2 transactions instead of 15, the end user will see tremendous benefits in overall performance of the app.
- So, we are now on hundreds of devices. How do we modify our development approach to make it easier to add new devices? How do we improve the efficiency around device implementation to match the efficiencies that the API provide us?
- So, we are now on hundreds of devices. How do we modify our development approach to make it easier to add new devices? How do we improve the efficiency around device implementation to match the efficiencies that the API provide us?
- Netflix has an array of internal engineering teams who specialize in discreet problems, such as recommendations, movie metadata, reviews, ratings, etc. That content needs to be delivered to the hundreds of Netflix-branded streaming devices (many of which are developed by internal engineering teams within Netflix). The API is the central pipeline that delivers that material to the devices.Right now, the API is a generic pipeline that the individual devices all call, basically in the same ways.
- We would like to get to a model where the API, in addition to offering the generic pipeline, also offers custom endpoints that the devices can call to replace the high-transaction needs currently found in rendering more complicated screens on the various devices. These custom endpoints will allow the API to do the heavy lifting in preparing the responses needed to render these complicated screens rather than requiring the client apps to handle it through many API calls.
- The model may look something like this, where the solid vertical black line to the right is dividing the clients from the servers:Client app makes a call across HTTP to a request handler.The request handler determines if the request is a custom endpoint or a generic one.If generic, the request gets sent to the API engine.If customer, the request goes to a request wrapper that knows what this custom endpoint needs. In some cases, it will explode the single request into many so it can retrieve all of the necessary data for the request.The API engine, in all cases, will make the appropriate calls to the dependencies to get all of the information needed to compile a response.The dependencies’ output will get pushed to a serialized metadata object that passes the response metadata up the stack to prepare delivery.The API engine, once brokering all of the metadata, will pass the serialized object to a response wrapper that determines what formatting script is needed to prepare the response.If the request was to a generic endpoint, the response wrapper handler will pass the serialized object to the default response wrapper where the response will be formatted and delivered.If the requests was to a custom endpoint, the response wrapper handler will pass the serialized object to the appropriate custom wrapper where the serialized object will be pruned, formatted and delivered in the optimal way for that particular device and UI.
- As we expand internationally, this degree of flexibility becomes even more important as the variability of devices, Uis, user expectations, country-specific elements, etc. could continue to grow dramatically.