Scaling Data Science on Big Data

Data science holds tremendous potential for organizations to uncover new insights and drivers of revenue and profitability. Big Data has brought the promise of doing data science at scale to enterprises, however this promise also comes with challenges for data scientists to continuously learn and collaborate. Data Scientists have many tools at their disposal such as notebooks like Juypter and Apache Zeppelin & IDEs such as RStudio with languages like R, Python, Scala and frameworks like Apache Spark. Given all the choices how do you best collaborate to build your model and then work through the development lifecycle to deploy it from test into production ? In this session learn the attributes of a modern data science platform that empowers data scientists to build models using all the data in their data lake and foster continuous learning and collaboration. We will show a demo of DSX with HDP with the focus on integration, security and model deployment and management. Speakers: Sriram Srinivasan, Senior Technical Staff Member, Analytics Platform Architect, IBM Vikram Murali, Program Director, Data Science and Machine Learning, IBM












Scaling Data Science on Big Data
- 1. © 2017 IBM Corporation Scaling Data Science on Big Data Vikram Murali Program Director, Data Science & Machine Learning, IBM Sriram Srinivasan STSM & Architect, Data Science & Machine Learning, IBM
- 2. IBM Analytics 3 © 2017 IBM Corporation<#> Data Scientist Pain Points Where is the data I need to drive business insights? I don’t want to know Hadoop/Hive etc How do I collaborate and share my work with others? What is the best visualization technique to tell my story? How do I bring my familiar R/Python libraries to this new Data Science platform? How do I learn to use the latest libraries/Technique? (TensorFlow, Scikit learn, XGBoost,…) and how do I ensure the right set of compute resources for these ? How are my Machine Learning Models performing & how to improve them? I have this Machine Learning Model, how do I deploy it in production? Machine Learning & Data Science
- 3. IBM Analytics 4 © 2017 IBM Corporation<#> Challenges for the Enterprise Ensure secure data access & auditability - for governance and compliance Control and Curate access to data and for all open source libraries used Explainability and reproducibility of machine learning activities Improve trust in analytics and predictions Efficient Collaboration and versioning of all source, sample data and models Repeatability of process Establish Continuous integration practices Agility in delivery Publish/Share and identify provenance/ lineage with confidence Visibility and Access control Effective Resource utilization and ability to scale-out on demand Balance resources amongst different data scientists, machine learning practioners' workloads Machine Learning & Data Science
- 4. IBM Analytics 5 © 2017 IBM Corporation<#> Why has this been hard ? Rigid toolsets & absence of an integrated platform Have to choose one and only one approach Cannot easily connect all of the capabilities required Difficult to navigate between the various tools used Fragmented and time consuming practices Result of using multiple disjoint environments Separate on-ramp/community for each tool/environment Does not yield meaningful meta data or complete data lineage Analytical Silos Difficult to maintain and version control project assets Limited means of collaborating with teams Results are difficult to share and audit Machine Learning & Data Science Resource Management Complexity Lack of scalable infrastructure Inflexible resource prioritization techniques
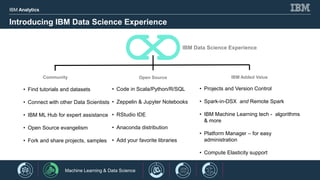
- 5. IBM Analytics 6 © 2017 IBM Corporation<#> Introducing IBM Data Science Experience • Projects and Version Control • Spark-in-DSX and Remote Spark • IBM Machine Learning tech - algorithms & more • Platform Manager – for easy administration • Compute Elasticity support IBM Data Science Experience Community Open Source IBM Added Value • Find tutorials and datasets • Connect with other Data Scientists • IBM ML Hub for expert assistance • Open Source evangelism • Fork and share projects, samples • Code in Scala/Python/R/SQL • Zeppelin & Jupyter Notebooks • RStudio IDE • Anaconda distribution • Add your favorite libraries Machine Learning & Data Science
- 6. IBM Analytics 7 © 2017 IBM Corporation<#> IBM Data Science Experience DSX on Public Cloud DSX Desktop DSX Local on Private Cloud PayGo consumption with as-a-service delivery, up & running in seconds Integrated with IBM Spark-as-a-Service for compute, IBM Object Store for data, as well as other platform assets Immediate cloud collaboration via RStudio and Jupyter notebooks Easily installed on your laptop or PC Won’t scale beyond the hardware available on your machine Access to RStudio and Jupyter notebooks, powered by one small Spark worker operating locally on your machine Load CSV data files into Data Frames Scalable DSX cluster deployed on your private infrastructure Dockerized containers via Kubernetes DSX Local can also deploy with Hortonworks Data Platform on-premises LDAP for user management and authentication Easy collaboration, versioning with Projects & git Built-in Zeppelin & Jupyter Notebooks and RStudio for visualizing and coding on data science tasks using Python, R, & Scala. Built-in Spark parallelizes & accelerates data science tasks. Machine Learning & Data Science
- 7. IBM Analytics 8 Machine Learning Workflow in Data Science Experience Machine learning detects if models fall out of spec — and automatically triggers retraining Fully integrated model management means data scientists, app developers & operations can use the same environment Machine Learning & Data Science Data Live SystemIngest Data Processing Model Training Deployment & Management Creating samples & Cleansing Automating Data Science Workloads Scalable Deployment Feedback Loop Historical Streaming Data visualization Feature transform and engineering Model selection and evaluation Pipelines, not only models Versioning Predict when given new data Monitoring and live evaluation Models lose accuracy Data Scientists + Researchers ML Engineers + Production Engineers Data Engineers
- 8. IBM Analytics 9 Data Science Experience Machine Learning Everywhere – An Open Platform Add your favorite libraries Publish Open APIs for secure ML applications Machine Learning & Data Science
- 9. IBM Analytics 10 DSX Local Architecture Machine Learning & Data Science
- 10. IBM Analytics 11 DSX Scale out in Kubernetes is simple DSX-Spark scale-out is automatically done by adding more compute nodes (via “Daemon Sets”) Remote Spark can be independently scaled out as usual (say in Hadoop/Yarn) Individual workload Isolation and scale-out in pods Each DSX individual user (or an entity, in general) gets a Kubernetes namespace assigned, making metering simple. All containers (pods) for that user gets spawned in that namespace, such as for tools – Jupyter/Zeppelin (Python) or R/RStudio as well as other non-spark jobs. Namespace provides total quota for that user with resource requests and limits set in each pod deployment “Shared” services are load balanced (with HA support) across all user access by typical Kubernetes techniques, such as via replicas of pods & DNS-routing via Kubernetes services. Machine Learning & Data Science
- 11. IBM Analytics 12 Data Science Experience with Hortonworks Data Platform Big Data DSX
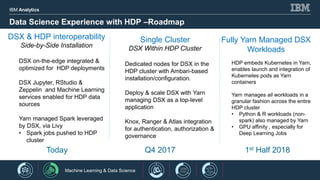
- 12. IBM Analytics 13 Data Science Experience with HDP –Roadmap DSX & HDP interoperability Side-by-Side Installation DSX on-the-edge integrated & optimized for HDP deployments DSX Jupyter, RStudio & Zeppelin and Machine Learning services enabled for HDP data sources Yarn managed Spark leveraged by DSX, via Livy • Spark jobs pushed to HDP cluster Single Cluster DSX Within HDP Cluster Dedicated nodes for DSX in the HDP cluster with Ambari-based installation/configuration. Deploy & scale DSX with Yarn managing DSX as a top-level application Knox, Ranger & Atlas integration for authentication, authorization & governance Fully Yarn Managed DSX Workloads HDP embeds Kubernetes in Yarn, enables launch and integration of Kubernetes pods as Yarn containers Yarn manages all workloads in a granular fashion across the entire HDP cluster • Python & R workloads (non- spark) also managed by Yarn • GPU affinity , especially for Deep Learning Jobs Today Q4 2017 1st Half 2018 1 Machine Learning & Data Science
- 13. IBM Analytics 14 Goal: Enterprise IaaS for Data Scientists Efficient Compute Resource Management for large-scale Analytics, Machine Learning and Deep Learning workloads -Enable Data Scientists to procure resources from a shared compute “grid” for any kind of activity from interactive notebooks & IDEs to training Jobs or scheduled scripts and Apps. -All compute manifested as Docker containers/Kubernetes pods HDP/Yarn as the Resource Manager -Enable all workloads, whether Map Reduce or Spark Jobs or DSX/ML activities to be uniformly handled by the HDP/Yarn scheduler. -Manage Queue Priorities, balancing of workloads and scale-out for the whole cluster providing best utilization of all resources. Yarn and Kubernetes - the best of both worlds ! Machine Learning & Data Science
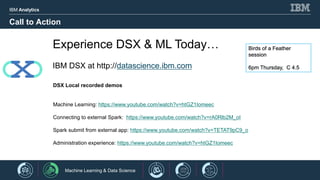
- 14. IBM Analytics 15 © 2017 IBM Corporation<#> Call to Action Experience DSX & ML Today… IBM DSX at http://datascience.ibm.com DSX Local recorded demos Machine Learning: https://www.youtube.com/watch?v=htGZ1Iomeec Connecting to external Spark: https://www.youtube.com/watch?v=rA0Rlb2M_oI Spark submit from external app: https://www.youtube.com/watch?v=TETAT9pC9_o Administration experience: https://www.youtube.com/watch?v=htGZ1Iomeec Birds of a Feather session 6pm Thursday, C 4.5 Machine Learning & Data Science
- 15. © 2017 IBM Corporation THANK YOU IBM Data Science Experience Vikram Murali Program Director, Data Science & Machine Learning, IBM Sriram Srinivasan STSM & Architect, Data Science & Machine Learning, IBM